点击下方卡片,关注“具身智能之心”公众号
作者丨Wenyao Zhang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
研究背景与动机
近年来,视觉-语言-动作(VLA)模型在整合图像生成与动作预测以提升机器人操作的泛化性和推理能力方面展现出潜力。但现有方法受限于基于图像的预测,存在信息冗余,且缺乏动态、空间和语义等关键世界知识,难以形成闭环的感知-预测-动作循环。
人类在行动前会先形成抽象的多模态推理链,而现有VLA模型多直接从观测映射到动作,缺乏这种前瞻推理能力。部分方法尝试生成未来帧或关键点辅助动作预测,但仍存在局限:图像预测包含大量与当前观测重叠的冗余像素;缺乏环境的3D空间信息;缺失高层语义等未来状态理解。
为此,DreamVLA提出通过预测全面的世界知识(动态区域、深度、语义等),构建更有效的感知-预测-动作循环,以贴近人类与世界交互的方式提升机器人操作性能。
模型设计核心思路
全面世界知识预测
不同于生成完整未来帧,DreamVLA聚焦与机器人执行相关的关键世界知识,包括三类核心特征:
动态区域预测:利用光流预测模型识别场景中动态区域(如运动物体、机器人末端执行器),让模型专注于任务关键的运动区域,避免冗余帧重建。通过CoTracker提取动态区域,训练模型仅重建这些区域,优化目标为最大化对数似然的证据下界,损失函数为:(其中为数据集,和分别为编码器和解码器)。 深度感知预测:采用深度估计算法生成每帧深度图,提供3D空间上下文。在无深度传感器时,以Depth-Anything预测为监督,通过尺度归一化均方误差训练,损失函数为:(用于消除单目方法的全局尺度模糊)。 高层基础特征:整合DINOv2和SAM等视觉基础模型的语义特征,通过InfoNCE损失进行对比语义预测,鼓励模型区分正确与错误的未来语义:(为温度参数,为空间 token 数量)。
结构注意力与动作生成
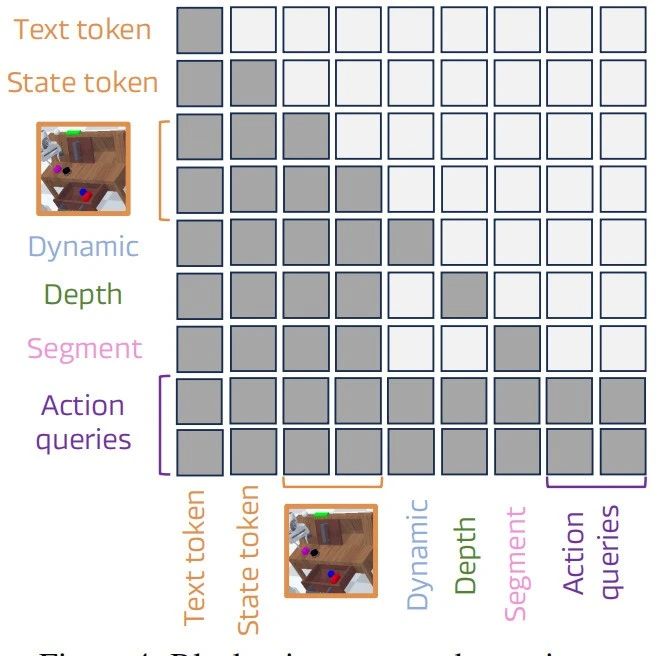
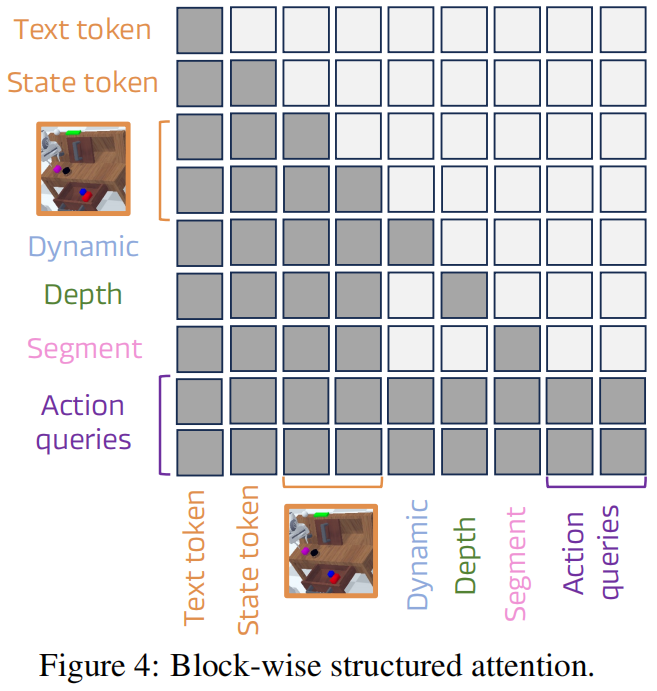
块结构注意力机制:将 <dream>查询分解为动态、深度、语义三个子查询,屏蔽子查询间的相互注意力,仅允许它们关注共享的视觉、语言和状态 token,避免跨类型知识泄露,保持表示的清晰分离(见figure 4)。
扩散Transformer解码器:由于世界embedding和动作embedding共享潜在空间,采用基于扩散的Transformer(DiT)从共享潜在特征中分离动作表示,通过迭代自注意力和去噪过程,将高斯噪声转化为n步动作序列,完成逆动力学建模。
实验结果与分析
基准测试性能
CALVIN模拟基准:在ABC-D任务上,DreamVLA的平均任务长度达4.44,超过RoboVLM(4.25)、Seer(4.28)等方法,在连续完成任务的成功率上也全面领先(见table 1)。

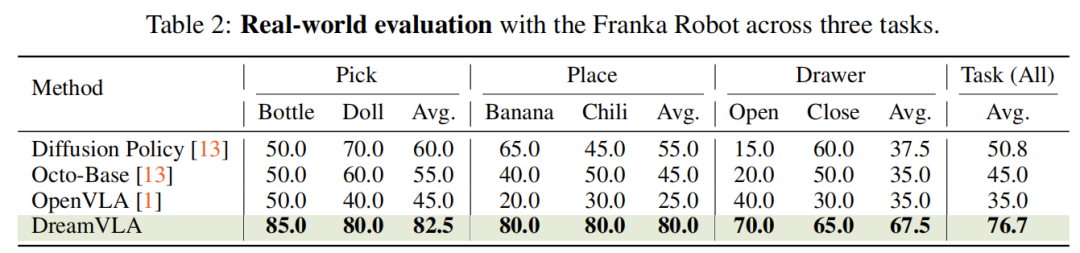
真实世界实验:在Franka Panda机械臂的抓取、放置和抽屉操作任务中,平均成功率达76.7%,显著高于Diffusion Policy(50.8%)、Octo-Base(45.0%)等基线(见table 2)。
消融实验洞察
各知识类型的贡献:动态区域预测单独使用时增益最大,深度和语义线索增益较小且接近;但深度或语义单独使用时可能损害性能(见figure 6)。

预测 vs 重建:预测未来知识(动态区域、深度、语义)的性能(平均长度4.44)显著优于仅重建当前信息(4.14),因预测提供更贴合动作的导向信号(见table 4)。

结构注意力的作用:相比普通因果注意力,块结构注意力使平均任务长度从3.75提升至4.44,证明其在抑制跨信号干扰中的有效性(见table 6)。

核心贡献与局限
主要贡献
将VLA模型重构为感知-预测-动作模型,通过预测动态、空间和高层语义信息,为规划提供简洁而全面的前瞻线索。 提出块结构注意力机制结合扩散Transformer解码器,抑制跨类型知识泄露的表示噪声,实现连贯的多步动作推理。 在CALVIN基准(4.44平均长度)和真实世界任务(76.7%成功率)上刷新SOTA,消融实验验证各组件有效性。
局限性与未来方向
当前主要适用于平行夹爪操作,依赖RGB数据,场景的几何和材料多样性有限。未来计划:加入灵巧手演示与接触标注;融合3D点云、触觉等信息;扩展数据收集以增强泛化性和长视野鲁棒性。
参考
[1]DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge