
“如何让在虚拟世界中训练的机器人,在真实世界中同样出色地完成任务”?
上面这个被称为"Real2Sim2Real"的挑战,一直是阻碍机器人大规模应用的关键瓶颈。
来自极佳科技、中科院自动化所和北京大学的研究团队,针对这一难题,提出了首个实现机器人物理和视觉统一的大一统框架——EmbodieDreamer!
本文将具体介绍,该框架是如何通过创新的「双重对齐技术」,让机器人在"Dream"般的仿真环境中学会真实世界的技能。

数据困境与仿真陷阱
机器人学习的根本矛盾
当前机器人学习领域面临着一个几乎无解的困境:
一方面,深度学习模型需要海量数据才能学会复杂的操作技能;另一方面,在真实世界中收集机器人数据的成本高得令人望而却步。
想要教会一个机器人抓取并放置物体,传统方法需要:
昂贵的硬件设备:每个机器人系统动辄数万美元,且机器人在学习过程中可能损坏;
专业的操作人员:需要经过培训的工程师进行数据收集;
漫长的收集过程:每个任务需要成百上千次的演示;
这种情况下,「仿真环境」成为了看似完美的替代方案。
在虚拟环境中可以:无限次地重复实验而不担心损坏;快速并行地训练多个策略;精确控制环境条件和干扰因素;自动化地生成各种场景变化。

Reality Gap:仿真的致命弱点
然而,仿真环境存在一个致命弱点——Reality Gap(现实差距)。
这种差距主要体现在两个关键维度:物理动力学差异、视觉外观差异。
(1)物理动力学差异
仿真器中的物理模型往往是真实世界的简化版本。具体表现包括:
摩擦模型过于理想化:真实世界中的摩擦是非线性的、各向异性的,而仿真中通常使用简单的库仑摩擦模型;
关节特性难以精确建模:真实机器人的关节存在齿隙、弹性变形、非线性刚度等复杂特性;
接触动力学简化过度:物体间的碰撞、滑动、滚动等接触行为在仿真中往往被大幅简化;
材料属性缺失:柔性物体、液体、粉末等材料的物理特性极难准确模拟。
这些差异导致的后果是:
在仿真中完美执行的动作序列,在真实世界中可能完全失效。比如,一个在仿真中能稳定抓取物体的策略,在真实世界中可能因为摩擦力估计错误而导致物体滑落。
(2)视觉外观差异
仿真渲染与真实世界的视觉差异同样显著:
纹理细节缺失:仿真物体往往使用简单的纹理贴图,缺乏真实世界的细节变化;
光照效果不真实:全局光照、阴影、反射等效果难以完全模拟真实环境;
材质渲染简化:金属、玻璃、塑料等不同材质的视觉特性被过度简化;
环境复杂度不足:背景杂乱度、遮挡关系等真实场景特征难以完全复现。
视觉差异的影响尤其严重,因为现代机器人策略大多依赖视觉输入。一个在干净仿真环境中训练的视觉模型,面对真实世界的复杂视觉场景时可能完全"失明"。

EmbodieDreamer
面对Real2Sim2Real的挑战,EmbodieDreamer提出:通过构建一个统一框架,同时从物理和视觉两个维度缩小仿真与现实的差距。
核心设计理念

▲EmbodieDreamer是一个统一的Real2Sim2Real框架,它结合了PhysAligner用于从真实观察中快速优化物理参数,以及VisAligner用于生成视觉逼真的场景。©️【深蓝具身智能】编译
EmbodieDreamer的设计可以概括为三个关键点:
(1)统一框架思维:不再将物理和视觉问题割裂处理,而是设计一个协同工作的整体系统;
(2)可微分优化:利用现代深度学习的梯度优化能力,替代传统的启发式搜索方法;
(3)结构化建模:将复杂场景分解为可控的组件,实现精细化的生成和控制。
系统架构概览

▲EmbodieDreamer框架集成了PhysAligner和VisAligner,以减少物理和外观方面的Real2Sim2Real差距。PhysAligner优化模拟器动力学,而VisAligner将模拟渲染转换为用于机器人策略训练的真实观察。©️【深蓝具身智能】编译
EmbodieDreamer包含两个核心模块:
(1)PhysAligner:负责物理参数的自动校准和优化
(2)VisAligner:负责视觉外观的真实化转换
这两个模块通过一个统一的训练流程进行端到端优化,确保物理真实性和视觉真实性的协调一致。

PhysAligner
让物理仿真"懂"真实世界
为什么需要可微分物理?
传统的物理参数优化方法(如SimplerEnv使用的模拟退火)存在诸多问题:
收敛速度慢:需要大量的随机采样和评估;
容易陷入局部最优:启发式搜索难以保证全局最优;
参数敏感性高:微小的参数变化可能导致性能大幅波动;
计算资源消耗大:每次评估都需要完整的仿真rollout。
三阶段优化流程
PhysAligner的工作流程为三个相互衔接的阶段。

▲该图说明了PhysAligner的工作流程。首先,使用模拟器生成大量数据。然后,训练一个代理模型来拟合数据。最后,通过梯度下降优化物理参数。©️【深蓝具身智能】编译
第一阶段:仿真数据集生成
Step1:从真实机器人收集的数据中提取动作序列和对应状态
Step2:随机采样多组物理参数: : 摩擦系数 (包括静摩擦和动摩擦)
a. : 关节刚度系数 (影响位置控制的响应特性)
b. : 阻尼系数 (影响运动的平滑性和稳定性)
这个过程会生成一个三元组数据集:
第二阶段:代理模型构建
直接优化仿真器参数的挑战在于,大多数物理仿真器(如MuJoCo)的内部计算过程是不可微的。PhysAligner的创新在于构建一个可微分的代理模型:
这个代理模型是一个神经网络,它学习物理参数如何影响状态转换。训练目标是最小化预测状态与仿真状态的差异:
代理模型的设计考虑了几个关键因素:
输入归一化:物理参数的数值范围差异很大,需要合适的归一化
网络容量:使用三层MLP,平衡表达能力和过拟合风险
激活函数选择:使用平滑的激活函数确保梯度流畅

▲PhysAligner演示示例。©️【深蓝具身智能】编译
第三阶段:基于梯度的参数细化
有了可微分的代理模型,就可以使用梯度下降来优化物理参数:
这里S_t是真实世界观测到的状态。优化过程:
固定代理模型的权重 → 将(f,p,d)视为可优化参数 → 通过梯度下降迭代更新参数值 → 直到预测轨迹与真实轨迹充分对齐。
损失函数的精细设计
PhysAligner的损失函数不仅考虑末端执行器的位置,还包含旋转信息:
平移损失考虑笛卡尔空间的位置误差:
旋转损失使用SO(3)空间的度量:
这里的归一化因子来自旋转矩阵差的最大Frobenius范数,确保角度误差在合理范围内。

VisAligner:
从简陋渲染到逼真视频
为什么需要视频生成而非图像转换?
许多现有方法尝试通过图像级别的风格迁移来解决视觉差异,但这种方法存在根本性缺陷:
时序不一致:逐帧处理导致视频闪烁和不连贯;
物体完整性丧失:风格迁移可能破坏物体的结构信息;
语义信息混乱:重要的视觉线索可能在转换中丢失。
技术架构:结构化的条件生成
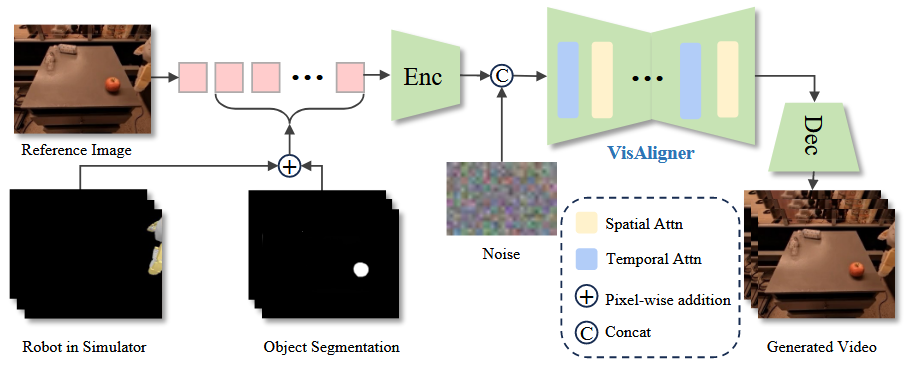
▲VisAligner的框架。包含初始背景和机器人外观信息的参考图像作为条件视频的第一帧。后续帧通过对来自模拟环境的机器人运动观察和前景物体的分割掩码进行逐像素相加来生成。©️【深蓝具身智能】编译
VisAligner的核心创新在于将场景分解为三个独立可控的组件:
(1)机器人组件
使用 URDF 模型精确描述机器人结构
通过关节轨迹 在仿真器中重放:
手动标定虚拟相机参数以对齐真实视角
(2)前景物体组件
应用 GroundSAM 进行自动物体分割
生成二进制掩码 seg 标识物体区域
通过像素级相加生成条件信号:
(3)前景组件
利用静态相机假设
使用单张参考图像 作为背景控制
条件序列构建:
扩散模型训练细节
VisAligner采用潜在视频扩散模型(Latent Video Diffusion Model)作为骨干:
编码阶段:
使用 VAE 编码器 将条件帧和真实视频编码到潜在空间
获得潜在表示
潜在空间维度: (相比 RGB 空间大幅降低计算量)
扩散过程:
在时间步 , 向干净的潜在表示添加噪声:
噪声调度 遵循预定义的衰减曲线, 控制扩散过程的速度。

去噪网络优化:
去噪网络采用U-Net架构,包含:
(1)空间注意力机制:捕捉帧内的空间关系
(2)时序注意力机制:维护帧间的时序连贯性
(3)交叉注意力层:融合条件信息
关键设计选择及其影响
为什么要进行物体分割?
实验表明,不使用物体分割会导致:抓取过程中物体"消失";物体形状严重变形;位姿估计错误
通过显式的物体分割,VisAligner能够:
保持物体的结构完整性;准确跟踪物体的运动轨迹;生成物理上合理的交互效果。

实验验证
实验设置
研究团队使用Cobot Mobile ALOHA机器人平台进行实验,这是一个基于Mobile ALOHA设计的商业化系统。实验设计体现了几个关键考虑:
数据规模控制:每个任务收集50个演示,平衡了数据质量和收集成本
任务多样性:涵盖抓取、放置、精确操作等不同难度级别
评估指标完整性:同时考虑中间步骤(抓取成功)和最终结果(任务成功)
PhysAligner性能分析

▲物理参数优化对比©️【深蓝具身智能】编译
整体轨迹误差降低3.74%:看似不大,但在控制领域,这种精度提升可能决定任务成败
旋转误差显著改善:从0.1282降至0.1101,这对精确操作任务尤其重要
计算效率提升89.91%:从3.6小时缩短到22分钟,使得在线参数调整成为可能
VisAligner生成质量评估

▲视频生成质量指标©️【深蓝具身智能】编译
FVD(Fréchet Video Distance):衡量生成视频的整体分布质量,降低58.3%意味着生成视频更接近真实分布
PSNR(峰值信噪比):像素级相似度,提升表明细节保真度更高
SSIM(结构相似性):感知质量指标,0.821表示高度的结构保持
LPIPS(感知相似度):基于深度特征的相似度,更符合人类感知

▲是否将前景对象分割用作条件输入的视觉化对比©️【深蓝具身智能】编译
视觉对比展示了物体分割的重要性:
上排(无分割):抓取时杯子严重变形,甚至"融化"到桌面
下排(有分割):物体保持完整形状,抓取过程物理合理
真实世界任务评估

▲不同训练方法的成功率对比©️【深蓝具身智能】编译
研究设计了四个递进难度的任务:
抓取纸杯:基础抓取能力测试;
笔放入笔筒:需要精确的位姿控制;
遥控器放入盒子:涉及形状匹配和空间推理;
杯子放到垫子上:要求准确的深度感知。
关键发现:
单视角性能超越三视角:通过EmbodieDreamer训练的单视角模型(77%)超过了原始的三视角模型(60%)
泛化能力提升:在未见过的物体配置上表现稳定
精确操作改善:放笔任务从20%提升到70%,提升幅度达250%

RL集成:从模仿到自主改进
轨迹偏好优化(TPO)的创新应用
EmbodieDreamer不仅支持模仿学习,还能与强化学习无缝集成。这通过轨迹偏好优化(Trajectory Preference Optimization)实现:
核心思想: 与其定义复杂的奖励函数,不如直接从轨迹的相对好坏中学习。
数学框架: 优化目标遵循 KL 正则化的强化学习范式:
其中:
: 通过监督学习获得的参考策略
: 控制与参考策略偏离程度的系数
: 轨迹的奖励函数
TPO 损失函数设计:
对于偏好轨迹对 (分别表示较好和较差的轨迹), 损失函数为:
对数概率优势定义为:
实际实现细节:
在离散动作空间的 ACT 模型中, 轨迹的对数似然通过预测误差计算:
这种设计巧妙地将连续的预测误差转化为概率度量, 使得 TPO 框架可以应用于确定性策略。
训练流程
轨迹生成:使用当前策略在EmbodieDreamer中生成多条轨迹
轨迹评分:基于末端执行器与目标的距离计算奖励
偏好对构建:选择top-M和bottom-M轨迹作为正负样本(M=25)
策略更新:使用TPO损失训练80个epoch
迭代改进:重复上述过程直到收敛

总结
传统方法往往陷入"局部优化陷阱"——单独优化物理或视觉,忽视了两者的相互影响。EmbodieDreamer通过统一框架:
首次实现了物理和视觉的统一;
将不可微的组件(物理仿真器)转换为可微分形式;
通过高质量的仿真环境,50个真实演示就能训练出可用的策略。
未来的机器人将在越来越逼真的"梦境"中学习,然后在真实世界中展现它们的技能。这个"梦境"不再是简陋的模拟,而是物理准确、视觉逼真的平行世界。
编译|JeffreyJ
审编|具身君
论文信息
标题:EmbodieDreamer: Advancing Real2Sim2Real Transfer for Policy Training via Embodied World Modeling
作者:Boyuan Wang, Xinpan Meng, Xiaofeng Wang, Zheng Zhu, Angen Ye, Yang Wang, Zhiqin Yang, Chaojun Ni, Guan Huang, Xingang Wang
论文地址:https://arxiv.org/pdf/2507.05198
项目主页:https://embodiedreamer.github.io/
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文










