在AI算力成本居高不下、大模型部署门槛越来越高的今天,一家来自美国西雅图的硬件初创公司,正用全新路线向英伟达发起正面挑战。
近日,由前苹果、Meta机器学习工程师联合创立的AI硬件公司ElastixAI正式走出隐身模式,发布了基于FPGA的大语言模型推理平台。
这家成立不久的初创公司,直接打出了一组极具冲击力的数据:
相比英伟达GPU部署方案,其平台可实现总体拥有成本最高降低50倍,功耗减少80%。
前苹果Meta团队出山,1800万美元融资加持
ElastixAI的创始团队来头不小,核心成员均来自苹果、Meta、Waymo等一线科技巨头,在机器学习优化、AI芯片、自动驾驶系统等领域拥有深厚积累。
2025年5月,公司已完成由Fuse VC领投的1800万美元种子轮融资。
此次公开亮相,他们带来了可直接替换现有GPU服务器的Elastix Rack整机方案,首批硬件计划在2026年年中正式出货。
在产品发布前的独家专访中,联合创始人团队详细解释了一个核心判断:
GPU擅长训练,FPGA才是推理的未来。
GPU天生不适合LLM推理:一个根本性错配
ElastixAI的核心论点非常清晰:
当前行业的主流方案——英伟达GPU,从架构上就不是为LLM推理设计的。
•大模型训练:强计算密集型,需要大量算力,GPU如鱼得水。
•大模型推理:强内存密集型,更吃带宽与容量,GPU效率大幅下降。
创始人Mohammad Rastegari直言:
“训练高度依赖算力,推理高度依赖内存。这种错配,直接导致GPU在推理场景下利用率极低。”
更致命的是硬件僵化问题。
以4比特量化为例,理论上可以让吞吐量翻倍,但在H100这类缺乏原生支持的硬件上,工程师只能通过软件内核“绕路实现”,最终算力利用率可能只有10%。
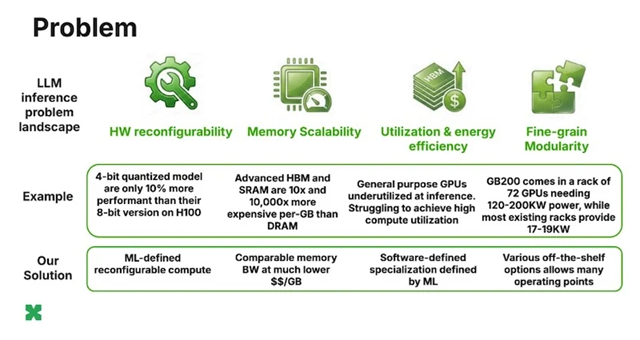
ElastixAI 的方法如何应对关键的大型语言模型推理挑战
ElastixAI的思路则完全不同:
不堆最贵的存储,不做封闭的专用芯片,而是围绕单位带宽成本、单位容量成本这两个真正决定TCO的指标做优化。
通过软件‑ML‑硬件协同设计,在通用商用FPGA服务器上榨干性能,用更便宜的DDR、HBM实现大模型推理所需的带宽,成本远低于行业顶级存储方案。
为什么选FPGA,而不是死磕专用芯片?
很多人会问:既然要颠覆GPU,为什么不直接做ASIC专用芯片?
ElastixAI的答案非常现实:
AI迭代速度,已经远超芯片研发周期。
Rastegari举了一个极具说服力的例子:混合专家模型MoE。
不少公司刚立项流片时,MoE还不是主流;等芯片设计完成、准备量产,行业已经全面转向MoE,之前的芯片直接过时。
“定制芯片从设计到量产要三年以上,
但机器学习的格局,几个月就可能天翻地覆。”
反观FPGA,优势一目了然:
可快速重构、随需求迭代。
从早期20令牌/秒就能满足交互,到如今需要200令牌/秒支持推理,硬件需求变化极快。
FPGA可以持续适配,而固定架构芯片做不到。
团队同时指出:
通用性和效率本身就是矛盾。
越追求通用,就要加越多冗余硅片,效率必然下降。
Transformer架构如今已足够稳定,非常适合用FPGA实现;
而底层优化仍在飞速迭代,锁定专用芯片设计,风险极高。
至于未来是否会自研专用芯片,公司态度非常谨慎:
“是否流片、何时流片,完全取决于机器学习技术的迭代速度。”
成本降50倍、功耗降80%,还能风冷部署
在最关键的性能对比上,ElastixAI给出了明确数据:
•相比英伟达B200,成本优势最高可达50倍
•同等吞吐量下,单令牌功耗降低5倍
•整体功耗降低80%
这些数字覆盖数据中心全场景的资本支出CapEx与运营支出OpEx,并已与FPGA厂商、数据中心运营商联合验证。
更让现有机房心动的是部署条件:
•Elastix Rack:标准机柜,17–19 kW,风冷即可
•英伟达GB200 NVL72:120–200 kW,需要专用液冷
绝大多数现有数据中心,无法直接上英伟达高端方案,
但可以无缝接入ElastixAI的FPGA机架。
即插即用:无痛替换英伟达GPU
为了降低迁移门槛,ElastixAI做了一个极其关键的设计:
通过vLLM插件,直接替换掉英伟达CUDA后端,
但前端OpenAI兼容接口完全不变。
这意味着:
从GPU迁移过来的用户,不需要修改任何应用代码与业务栈,就能直接使用。
公司还计划效仿英伟达早年构建CUDA生态的思路:
未来向研究者开放模型转换工具,免费提供软件能力,
逐步围绕自身平台,形成持续滚动的开发者飞轮。
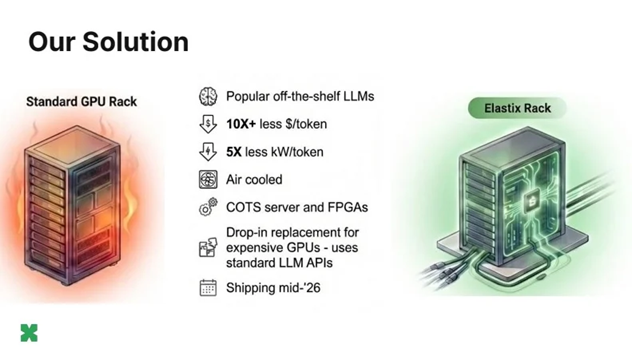
ElastixAI 的方法相较于标准 GPU 机架实现在 AI 计算中具有多项关键优势
写在最后
在英伟达凭借GPU占据AI算力绝对主导的今天,ElastixAI走出了一条差异化路线:
不做最贵的芯片,做最适合推理的方案。
用FPGA替代GPU、用通用硬件替代专用加速器、用风冷替代液冷、用低成本替代高投入。
如果其宣称的**成本降50倍、功耗降80%**能够落地,
那么整个LLM部署、云服务商、数据中心的格局,都可能被重新改写。
目前,ElastixAI已向部分企业客户与数据中心开放试用,
硬件正式交付时间定在2026年年中。
GPU的推理霸权,真的要被FPGA动摇了吗?
我们很快就会看到答案。
参考原文
https://www.allaboutcircuits.com/news/elastixai-emerges-from-stealth-with-fpga-approach-to-gen-ai-supercomputing