作者 | 黄婉宜
编辑 | 周伟鹏
中国AI太争气了!
OpenRouter官方数据显示,2月9日至15日,中国AI模型的周调用量达到4.12万亿Token,而美国同期则是2.94万亿Token。
这是中国首次在周调用量上超过美国,实现历史性反超。
随后一周,中国调用量再次攀升到5.16万亿Token,而美国却下滑至2.7万亿Token。

所谓Token,就是AI处理文本的最小单位,咱平时用AI写文章、编代码、问问题,每一个字、每一个标点,都会被拆成Token来处理。
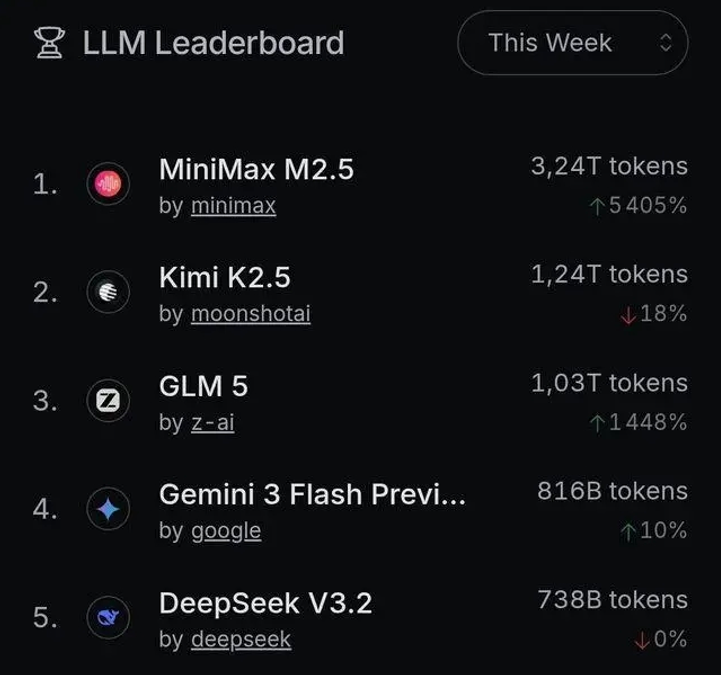
另外,在全球调用量前五的模型中,中国占据四席,分别是MiniMax M2.5、月之暗面Kimi K2.5、智谱GLM-5和DeepSeek V3.2,合计贡献前五名总量的八成。
其中MiniMax M2.5发布仅两周,就拿下单月调用量冠军,跻身全球最受欢迎的AI模型之一。
 中国AI实现大反超
中国AI实现大反超
OpenRouter是目前全球最大的AI模型API聚合平台,相当于一个大超市,开发者可自由选择和调用全球各种AI模型,不用挨个去各家公司注册账号。
因此,这个平台的调用量榜单,就相当于全球大模型的销量榜,也是衡量AI竞争力的重要风向标。
在该平台的开发者中,美国占比高达47.17%,而中国仅占6.01%。
这意味着,推动中国模型调用量爆发的,主要是海外开发者。
而在2025年11月,我们在这一方面还并不具备优势,美国Token调用量是中国的两倍左右。
短短三个月时间,中国AI就实现从追赶到超越的大反超,为啥?
今年年初,中国头部AI厂商集体发力,密集发布新一代旗舰模型,在春节期间大展身手。
月之暗面的Kimi K2.5模型,在软件工程任务上的成绩达到71.3%,超过了美国的Claude Sonnet 4.5;
MiniMax M2.5模型延迟低,适合高频调用;智谱GLM-5则擅长处理长文本,能满足复杂的文档分析需求。
当时中国大模型的更新次数约为美国的2倍,加上产品针对性强、覆盖场景多,吸引了海内外大量开发者使用。
 技术架构和电力成本的差异
技术架构和电力成本的差异
除了模型迭代迅速,技术架构的选择和电力成本的优势,也是实现反超的关键。
在技术架构上,中国AI厂商集体采用了MoE架构(混合专家模型),这是一条更高效、更省钱的路径。
这种架构的核心逻辑,就是将一个庞大的AI模型拆分成多个专业小模型,就像一个团队里有众多领域专家,处理不同任务时,只需激活最擅长该任务的专家,无需整个模型全员发力,极大提升了算力利用效率。
而海外主流AI模型,比如ChatGPT系列、Claude系列,大多采用传统的密集型(Dense)架构。
哪怕是处理简单的小任务,也需要激活整个模型的所有参数,难免造成大量算力浪费。
比如,在处理相同数量的Token时,美国Claude Opus 4.6的价格高达5美元,而中国MiniMax M2.5与智谱GLM-5的价格仅为0.3美元,性价比十分明显。
除此之外,电力是AI运行的燃料,成本占到AI总运营成本的60%~70%,而中国西部绿色电力每度仅需两三毛钱。
欧美那边每度则要1~1.5元,比我们贵了5倍左右。
这就意味着,生产同样数量的Token,中国的运营成本要比欧美低得多,进一步放大中国AI的全球竞争力。
 行业迎来发展黄金期
行业迎来发展黄金期
中国AI调用量的爆发,直接点燃国产算力的市场需求。
A股市场里,AI算力、云计算、数据中心等相关板块掀起涨停潮,国产GPU、AI服务器的需求量也跟着猛涨,整个行业迎来黄金发展期。

摩根大通预测,2025到2030年,中国AI推理的Token消耗量,会以约330%的年复合增速暴涨,整体规模能扩大370倍。
过去两年,大模型比拼的就是“大力出奇迹”,谁舍得砸钱买显卡,谁就能做出更强的模型。但现在不一样了,算法创新、工程优化、开源协作,照样能跑出优势。
不过,这次调用量实现反超,不代表中国AI就已经赢了。
目前咱们的AI专利数量虽然领先,但能获得国际认可的比例只有4%,远低于美国的32%。
谷歌旗下的 DeepMind CEO德米斯・哈萨比斯也评价道,中国 AI 模型和西方顶尖技术的差距已经缩小到几个月,但从0到1的原创性突破,还需要继续验证。
中美AI大PK,将迎来更加激烈的全方位较量。
•END•