本文由 Intern-S1 等 AI 生成,机智流编辑部校对
在React、Linux内核这类异步系统中,有一条黄金准则:永远不要阻塞事件循环。
而AI推理负载,也有一条相似的核心准则:永远不要让GPU陷入空闲等待。
当GPU陷入空闲等待时,就会产生一种被称为CPU开销(Host Overhead) 的效率损耗。在这篇文章中,我们会告诉你如何判断推理任务是否正受CPU开销的困扰、它的危害到底有多大,以及对应的解决办法——同时也会分享我们如何在生产级开源推理引擎中,实现了CPU开销的大幅优化。
CPU开销,直接体现为GPU核函数利用率偏低
当下,AI推理的延迟问题已经十分突出。用户的期待与计算机系统共同演进,任何响应耗时超过几百毫秒的系统,都会被用户定义为“卡顿”。而AI推理,恰恰很难满足这种强交互性的需求。
从根本上来说,这个瓶颈最终要靠芯片技术突破来解决:更高的内存带宽、更强的核心算力。但在此之前,作为软件工程师,我们必须把现有硬件的性能压榨到极致。
此前,我们已经分享过如何判断GPU硬件的有效利用率,从集群管理到Tensor Core流水线利用率都有涉及。而CPU开销,恰恰卡在中间环节:整个GPU的执行进度停滞,只因它在等待CPU为它准备好下一步的工作。
这个指标在nvidia-smi等工具中被标注为“GPU利用率”,我们更倾向于用更精准的叫法——GPU核函数利用率:它衡量的是GPU运行CUDA核函数的能力被利用的比例。在测量周期内,若GPU上每时每刻都至少有一个CUDA核函数在运行,该指标即为100%。
如果系统整体始终有任务需要处理(生产环境通常都是如此),那么GPU没有执行运算的每一个时间片,都是CPU开销造成的浪费。
想要找到解决CPU开销的优化点,我们的建议是:盯着代码死磕直到顿悟,哦不,是用PyTorch Profiler或Nsight Systems对推理引擎进行链路追踪。当你可视化查看这些追踪结果时,会发现CUDA流中存在大量“空隙”——这些,就是你解决CPU开销的优化机会。
CPU开销的危害,远超你的想象
一台现代数据中心级GPU,理论上1纳秒就能完成约100万次浮点运算。这意味着,GPU因等待CPU下发下一步指令而空闲的每一纳秒,都意味着100万次运算被白白浪费——这比你一生手动完成的算术运算总量还要多。
而这会直接冲击AI推理的成本效率:如果你的CPU开销达到50%,那么推理任务的GPU成本就是理论最优值的2倍。而GPU成本,恰恰是推理服务最核心的成本构成。
我们可以用领航员与航船的类比来理解这个问题:领航员需要提前规划好全程航线,确保航船不会因为等待航行指令而停滞。航船每一次因等待领航员确定航向、航速而停航,都是一次“领航员开销”,最终换来的只会是乘客的不满。
在AI推理负载中,CPU就是这位领航员,负责决定需要执行的计算任务;GPU设备就是这艘航船,负责完成实际的运算工作。优秀的船长,和所有优秀的领导者一样,除非万不得已,绝不会让实际执行工作停滞在决策环节。
不必要的CPU同步,是CPU开销的核心来源
我们来看这样一段航行指令:
“抵达珊瑚礁后,驶向地平线处的岛屿。”
当航船抵达珊瑚礁时,领航员需要完成三件事:识别目标岛屿、计算驶向岛屿的航向、向航船下发新的航向指令。在这段时间里,航船只能原地停航等待。
我们再对比另一段指令:
“抵达珊瑚礁后,将航向调整为向西5度。”
此时,航船仅需要等待领航员下发新航向的极短时间,几乎不会出现停滞。
可想而知,第二种方案的实现难度更高:你需要提前规划,甚至可能需要有人提前登岛,提前测量好准确的航向。但在生产级AI推理这种场景下,这些前置准备工作的成本,可以被数万亿次的执行过程完全摊销,最终带来的收益是无可替代的。
优化方案1:优先在目标设备构造张量,而非跨设备传输张量
我们在生产级推理引擎中,发现并修复的一类高频CPU开销问题,就是CPU与GPU之间不必要的数据传输。
举个例子,有一个位置嵌入张量,原本的实现是在CPU上构造完成后,再传输到GPU中。但在对CPU开销最敏感的解码阶段,这个张量始终有着固定的简单结构,完全可以直接在GPU上完成构造。
详见我们的PR。这里的核心收益,并不是GPU构造张量的计算速度更快,而是我们彻底避免了一次同步数据传输。
再看另一个案例:为了适配核函数的选择逻辑,一个KV缓存页长度张量,原本需要从GPU回传到CPU。但在对CPU开销最敏感的固定单位页场景下,这个张量的所有值永远都是1,完全可以直接在CPU上构造——用本地计算,替代跨设备通信。
详见我们的PR。这个案例的收益来源就更明显了:我们甚至把张量构造从GPU移到了CPU,性能反而提升了,这足以证明收益和GPU算力无关,核心是消除了同步传输带来的CPU开销。
每一次CUDA核函数启动,都是CPU开销的潜在来源
我们再回到航船的类比,看这样一组指令:
“向南航行5分钟。” “向东航行10分钟。” “向北航行。”
每完成一条指令,航船都会在等待领航员下发下一条指令时,出现短暂的停滞。如果航向调整的间隔长达数分钟,而转向操作仅需几秒,这种开销几乎可以忽略。但如果航船需要在险滩中穿行,必须执行一连串仅持续几秒的短航向调整,这种等待开销就会变得致命。
更好的方案,是把多条指令合并成一条:
“向南航行5分钟,随后向东航行10分钟,再向北航行。”
完全一样的问题,也出现在AI推理负载中。
在GPU上启动一次核函数,耗时大约在数微秒级别。听起来似乎微不足道——但别忘了,这段时间足够GPU完成约10亿次算术运算!更不用说,这些微秒级的开销会持续累积,尤其对于小模型、小输入的场景,影响会被无限放大。
举个例子,搭载HBM3e显存的B200 GPU,能在1毫秒内将一个8GB的模型从显存加载到寄存器中(这也是词元间延迟的内存下限)。像Qwen 3 8B FP8这样的8GB参数量模型,拥有数十个网络层,每层又包含数十个算子,原生实现会产生数百个核函数。就算每次启动仅耗时1微秒,数百次核启动带来的开销,也会严重侵蚀你的毫秒级延迟预算。
而最优解,就是把多次核函数启动合并为一次,只支付一次开销成本。
优化方案2:核函数融合,减少核启动带来的CPU开销
削减核函数启动开销的核心技巧,就是核函数融合——把多个核函数合并为一个。这个操作既可以手动实现,也可以自动完成。在当下最主流的神经网络加速框架PyTorch中,最常用的核融合工具就是Torch编译器。
在一个实际案例中,我们通过Torch编译器,将核函数启动次数从约20次压缩到3次,消除了约30微秒的CPU开销,同时将平均端到端延迟降低了20%。详见我们的PR。
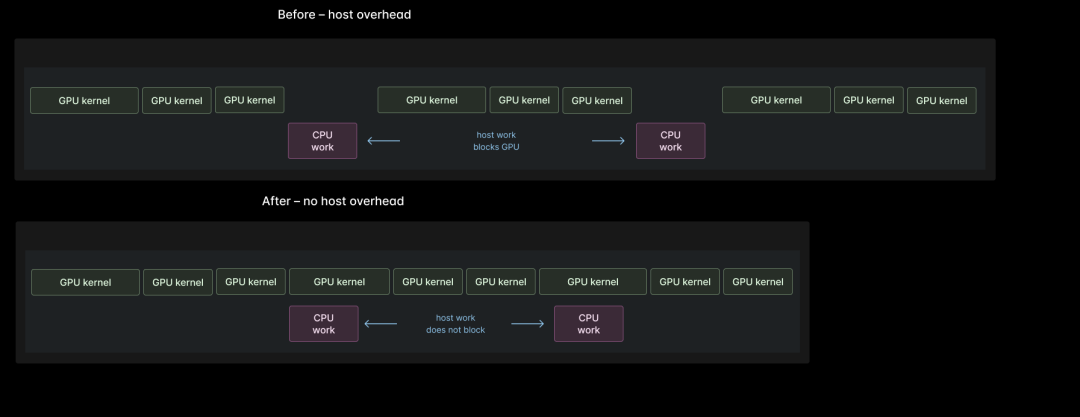
优化方案3:使用CUDA Graphs,进一步摊销启动开销
理论上,一次推理过程中的所有核函数,都可以被融合在一起。但在实际工程中,这对编译器来说难度过高,对人工开发来说则耗时过长。因此,即便经过了手动和自动的核函数融合,单次推理过程中通常还是会保留大量的核函数启动操作。
对于构成有向无环图的多次核函数启动,我们可以通过CUDA Graphs,将它们合并为一个可启动的执行单元。这项技术已经被SGLang、vLLM等生产级推理服务广泛采用。随着这些引擎和它们所服务的模型不断成熟,我们预计,将整个前向传播过程作为单个CUDA Graph启动,会成为行业通用方案。我们也非常期待在这个方向持续深耕。
结语
所以,想尽办法消除cpu开销是LLM推理中必不可少的一环。
-- 完 --










