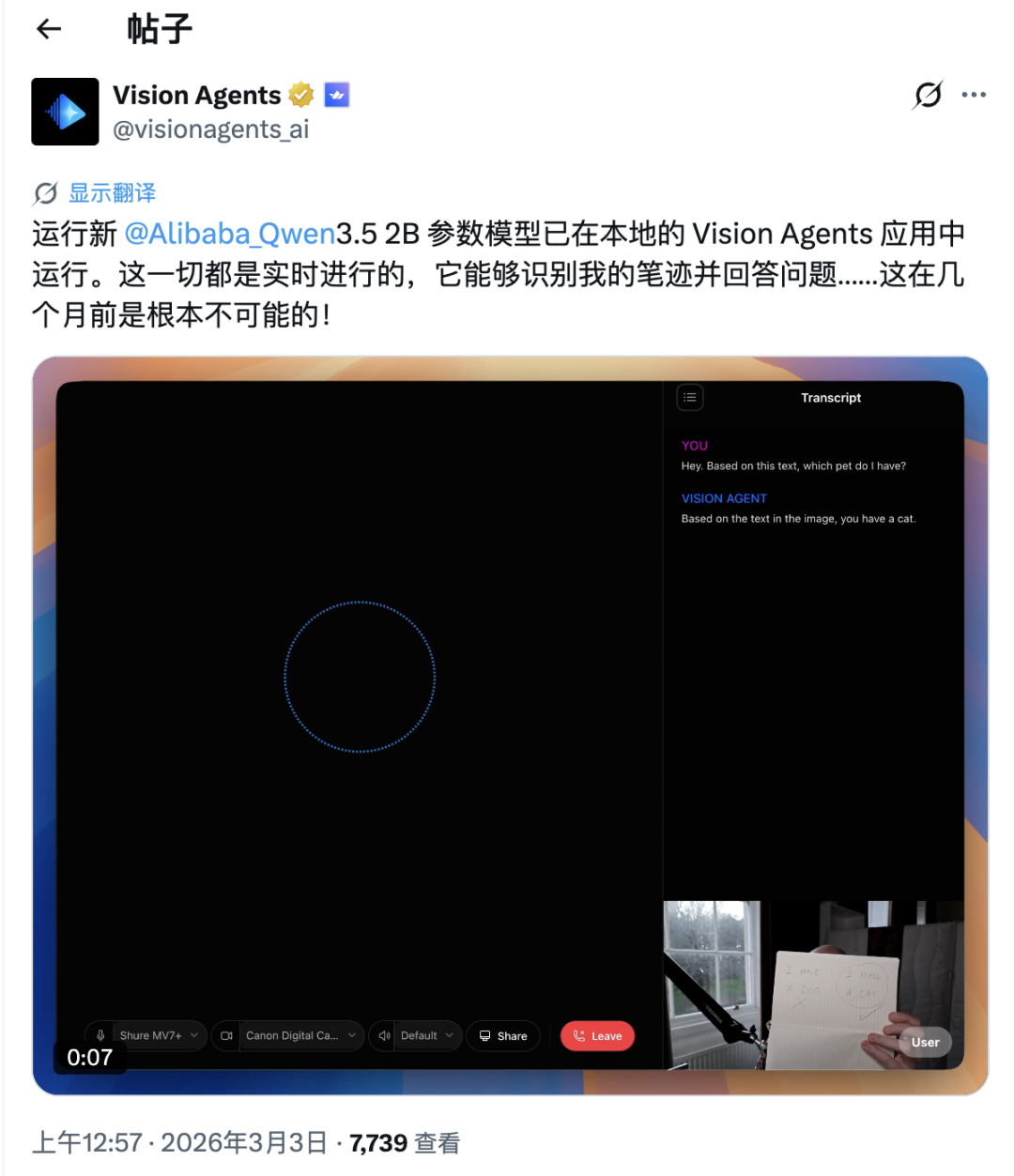
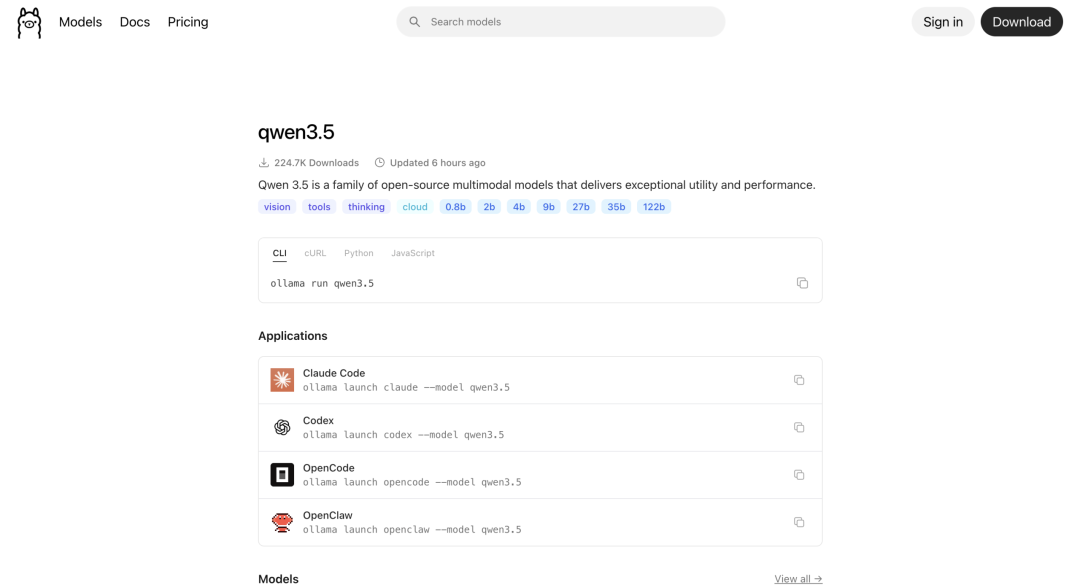
马斯克又双叒叕下场点赞中国 AI 了。 昨天深夜,阿里通义千问团队在 X 平台正式发布了 Qwen3.5 小模型系列,覆盖 0.8B、2B、4B 和 9B 四个参数规格。甫一发布,便在海外科技圈引发强烈反响。 马斯克也在该推文下评论称:「Impressive intelligence density」(令人印象深刻的智能密度)。这股热度的背后,APPSO 也好奇,为什么这几款小模型能够激起如此大的波澜? 又小又猛,凭什么 Qwen 官方在 X 平台发帖宣布这批模型上线,言简意赅地将其定位为「更强的智能,更少的算力」。 官方强调,四款小模型共享同一套 Qwen3.5 基础架构,原生支持多模态,并经过架构层面的专项改良与大规模强化学习训练。 Qwen 团队表示,希望这批模型能更好地支撑学术研究、实验探索与真实工业场景的创新落地,同时也宣布同步发布对应的 Base 基础模型。 Qwen3.5 系列模型核心采用「门控增量网络与稀疏混合专家」相结合的混合注意力架构,注意力层以 3:1 的比例排列,即 3 个 Gated DeltaNet 层搭配 1 个 Gated Attention 层。 这一设计的关键在于,模型在前向传播时只激活对当前任务必要的网络部分,而非全量计算,从而在极低延迟与算力开销下实现高吞吐推理。 附上 HuggingFace 地址:https://huggingface.co/Qwen/Qwen3.5-2B 多模态这块也有讲究。Qwen3.5 采用「早期融合」训练机制,文本、图像、视频在底层就一起处理,不是在文本模型上事后挂个视觉编码器。 这个差异直接决定了小参数模型在视觉问答、OCR 文档理解等任务上,能打出远超同量级传统轻量多模态模型的表现。 全系列同时支持长达 26 万 Token 的上下文窗口,并引入「思考」与「非思考」双模式,可在深度逻辑推理与快速响应之间灵活切换。 0.8B 与 2B 模型均为 24 层结构,隐藏维度分别为 1024 和 2048,专为物联网设备等极端边缘场景设计,也可直接在主流手机上原生运行。 尽管 0.8B 在语言基准 MMLU-Pro 上得分 29.7,表现平平,但受益于早期融合架构,其在视觉任务 MathVista 上达到 62.2,OCRBench 达到 74.5,展现出与参数量不相称的视觉理解能力。2B 模型的 OCRBench 进一步提升至 84.5,表现亮眼。 上下滑动查看更多内容 4B 模型为 32 层结构,隐藏维度 2560,能够流畅运行于消费级移动硬件。官方将其定性为「出乎意料强大的多模态轻量智能体底座」。 9B 则再进一步,同为 32 层结构,但隐藏维度提升至 4096,FFN 维度扩展至 12288,可以在 Mac 上流畅运行。 其 MMLU-Pro 得分达到 82.5,不仅超越了参数量为其三倍的上一代 Qwen3-30B,在视觉任务上更以两位数优势超过 GPT-5-Nano 与 Gemini 2.5 Flash Lite。 MMMU-Pro 得分高达 70.1,MathVision 达到 78.9,证明了其在复杂物理和数学图像解析上的实力。官方将 9B 的目标明确为「缩小与前沿大模型的能力差距」,从基准数据来看,这一目标已初步实现。 海外开发者对这批模型的实际表现给出了高度正面的评价。 有开发者直言,称其为「小模型」不过是低估了它,就好比把飓风叫做微风。 另有观点认为,真正值得关注的指标是每十亿参数所能释放的智能密度。如今只需 3 万美元的硬件,就能跑出一年前需要 20 万美元 GPU 配置才有的推理能力。 已有开发者演示了在 iPhone 17 Pro 上通过针对 Apple Silicon 优化的 MLX 框架本地运行 Qwen3.5-2B 6-bit 版本,模型可实时完成视觉理解与问答任务。 网友在本地 Vision Agents 应用中实时识别手写内容并即时回答问题,并感叹这在几个月前根本无法实现。 还有用户这样总结道,9B 模型性能与规模达 120B 的 ChatGPT 开源模型相当,体积却只有其十三分之一,且完全免费,可在任何笔记本电脑乃至手机上运行。 知名开源推理工具 Ollama 也迅速跟进,官宣支持 Qwen3.5 全系四个尺寸,并配套提供原生工具调用、思维链推理与多模态功能,只需一行命令即可拉取运行。 附上地址:https://ollama.com/library/qwen3.5 跑分是起点,AI+硬件才是终局 在谈及阿里为何坚持追求开源与发布全尺寸模型时,千问技术负责人林俊旸曾在清华 AGI-Next 峰会上转述其师弟的观点,给出了一个朴素的答案。 他表示,小模型起源于内部实验需求,是为了让资源有限的学生也能参与研究。他回忆道,7B 规模的模型已让很多硕士博士生无力承担实验成本,若将 1.8B 的模型开源出去,很多同学就有机会顺利毕业,「这是很好的初心」。 平心而论,Qwen 系列一路开源走下来,客观上确实让很多人用上了本来用不起的 AI 模型。而对于普通用户而言,想亲身体验这批最新的小模型其实也不复杂。 目前,你可以通过 PocketPal AI 这款手机应用,直接下载并在本地运行 Qwen3.5 系列模型,无需任何 API,模型推理全程在设备端完成。如果不习惯英文界面,可以在设置 (Setting) 里找到语言 (Language) 选项,切换成中文。 (具体教程可参考 APPSO 此前的文章:。 不过有一个细节,比选哪个模型更重要:选对量化版本。 BF16 是接近原始精度的半精度权重,回答稳定性最好,推理细节与对齐效果最接近原版,但 2B 的 BF16 权重文件就要 4.45GB,运行时还需额外占用内存用于 KV cache 和运行缓冲区,极易触发系统杀后台或直接加载失败。 因此手机端的选择逻辑应该是:可用内存长期能剩 6GB 以上,优先选 IQ4_NL;可用内存常在 3GB 至 5GB 之间,优先选 Q3_K_M;可用内存更低,才考虑 Q3_K_S 等等。 说到底,一个无法独立运行的模型,不过是一堆权重文件。真正有价值的,是与正确硬件深度绑定、以正确量化格式部署的小模型,那才能成为真正的产品。 智能手机时代本质上是「单向输入」的范式,而即将到来的 AI 硬件浪潮,是要以更碎片化、更有粘性的方式接管人类的记忆与生活。小模型,正是给这些硬件注入灵魂的关键。 阿里已将 Qwen 小模型嵌入 AI 眼镜等可穿戴硬件,实现毫秒级端侧视觉解析。在真实物理场景中,向眼镜询问前方障碍物时哪怕延迟三秒也会失去全部意义,而这恰恰是云端大模型无法克服的物理瓶颈。 你向眼镜询问前方障碍物的时候,哪怕延迟三秒也会失去全部意义,遇到需要深度推理的复杂问题,再作为路由器把请求交给云端的大模型处理。是的,端云协同架构,才是接下来几年计算平台的基本形态。 包括在 iPhone 的「视觉智能」中,当用户把摄像头对准餐厅或商品,端侧实时完成场景解析、文本提取,甚至直接唤起购买流程,全程在设备上完成。 此外有媒体报道称,苹果下一步还在开发带摄像头的 AirPods 和智能眼镜,这些设备会变成用户的「第二双眼睛和耳朵」。 工业方面,IoT 设备、工厂传感器、医疗监测终端,这些场景里数据隐私更敏感,本地推理同样是硬需求。而端侧小模型实时处理第一视角多模态数据,则是绕不过去的基础设施。 就像今天没有人会专门写一篇文章夸手机能打电话一样。AI 眼镜、AI 手表、AI 耳机等可穿戴设备,现在听起来还有点新鲜,但在未来,它们也会变得稀松平常。 而让这件事成为可能的,恰恰是一批又一批看似没什么存在感的小模型。它们很小,但如无意外,它们将无处不在。