最近,一个叫OpenClaw(小龙虾)的开源项目突然爆火,甚至出现线下排队安装的场面。很多人第一次直观地看到,AI不只是chatbot,而是可以真正“动手”操作电脑、完成复杂任务和个性化工作流的智能体。这意味着AI正在进入下半场,开始走向真实应用,并逐渐进入普通人的日常生活。
如果说上半场的 AI 是在拼模型参数和 benchmark 分数,那下半场真正要解决的,是一个更现实的问题:
AI 能不能在真实世界里,持续地干活。
过去几年,大家卷的是 scale、架构、训练 recipe,把 MMLU、数学题、代码题刷到 90%+。但大部分的数据集几乎都是短上下文、一次性任务。现实世界完全不是这样:白领工作、个性化助手、医疗诊断、深度研究,全部都是长时间、多轮次、以任务为导向或者以用户为核心的交互的场景。
Agent 能力已经从最初的尝试 function calling,进化到开始真正影响各类白领行业;Anthropic 开放各个行业级插件生态,也让一批 SaaS 公司股价剧烈波动;年初 openclaw 小龙虾项目的爆火,GitHub star 增长速度甚至超过 Linux。
但在这些现象背后,真正的核心便是 Memory。
近日一篇关于 Agent Memory 的系统性综述,联合了 20 + 所高校与工业界研究单位,包括伊利诺伊、加州等全球多所研究高校,以及 Meta、Google、Salesforce 等工业界团队,一起梳理了 Agent memory 这条正在爆炸式发展的赛道。

论文标题:Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey
论文链接:https://arxiv.org/pdf/2602.06052
论文资源:https://github.com/AgentMemoryWorld/Awesome-Agent-Memory
我们会持续更新最新foundation memory的文章,欢迎关注收藏。

这篇 Agent Memory 综述的核心是:当 Agent 从短对话走向长周期任务,真正爆炸的需求的不是仅仅模型的智能,而是去处理复杂 context、environment 的系统级 memory 能力。
单纯扩大 context window,并不能真正解决这个问题。现实环境中的信息会持续累积,复杂度远不止 token 数量的增长。
用户的历史行为、多任务记录、工具调用结果、外部文档、环境状态变化、模型自身的推理轨迹都会持续积累。随着时间推移,这些信息相互交织。如果只是简单拼接到 prompt 中,推理成本会迅速上升,注意力机制会被噪声淹没,关键线索反而更难被捕捉。
更重要的是,真实任务具有时间跨度。一个科研助手不能在每次对话时都 “忘记” 过去的讨论;一个个性化助理不能每一轮都重新学习你的偏好。
因此,问题不再是 “能读多少 token”,而是:
Agent 是否具备真正的 memory 机制,能够存储、抽象、压缩、更新甚至遗忘信息,并在长期过程中持续演化。这也是近两年 memory 相关论文数量急剧增长的根本原因。
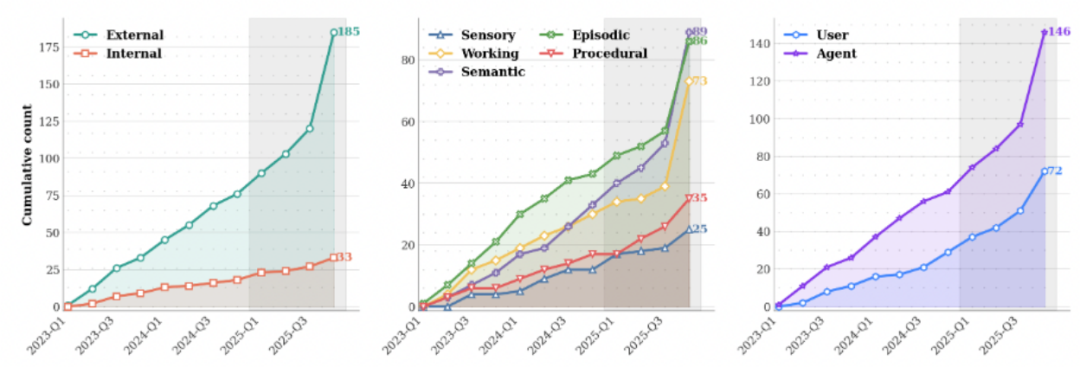
Memory 不只是 RAG
很多人把 memory 简化为 “RAG + 向量库”。这种理解只触及了表层。
这篇综述从系统设计视角重新组织了 Agent Memory,将其拆解为多个相互作用的维度,而不是一个孤立模块。
1. 首先是 memory 存储的位置。它可以存在于模型内部,例如通过参数更新、latent 表示或扩展的 KV cache;也可以存在于模型外部,例如结构化数据库、知识图谱或事件日志。内部 memory 紧密但难以控制,外部 memory 可解释性更强但需要调度策略。未来的 Agent 很可能是多层 memory 协同的混合结构。
2. 其次是 memory 在认知层面的功能。借鉴认知科学的划分,memory 可以承担不同 function。有些负责短期感知,有些支撑当前任务,有些记录具体事件,有些沉淀抽象知识,还有一些用于形成技能和策略。
3. 最后是 memory 的主体。记忆可以服务于用户,用于个性化;可以服务于任务领域,用于形成专业能力;也可以服务于 Agent 自身,用于自我改进。三者的优化目标和更新策略并不相同。
当这三条轴展开之后,我们看到的已经不是简单的 “存储系统”,而是一个系统级记忆体结构框架。未来 Agent 的在真实应用场景的能力上限,很可能不再完全取决于模型参数规模,而是依赖于 memory 如何与工具、环境和用户交互。
当环境变得真实,
数据集评估变得尤为重要
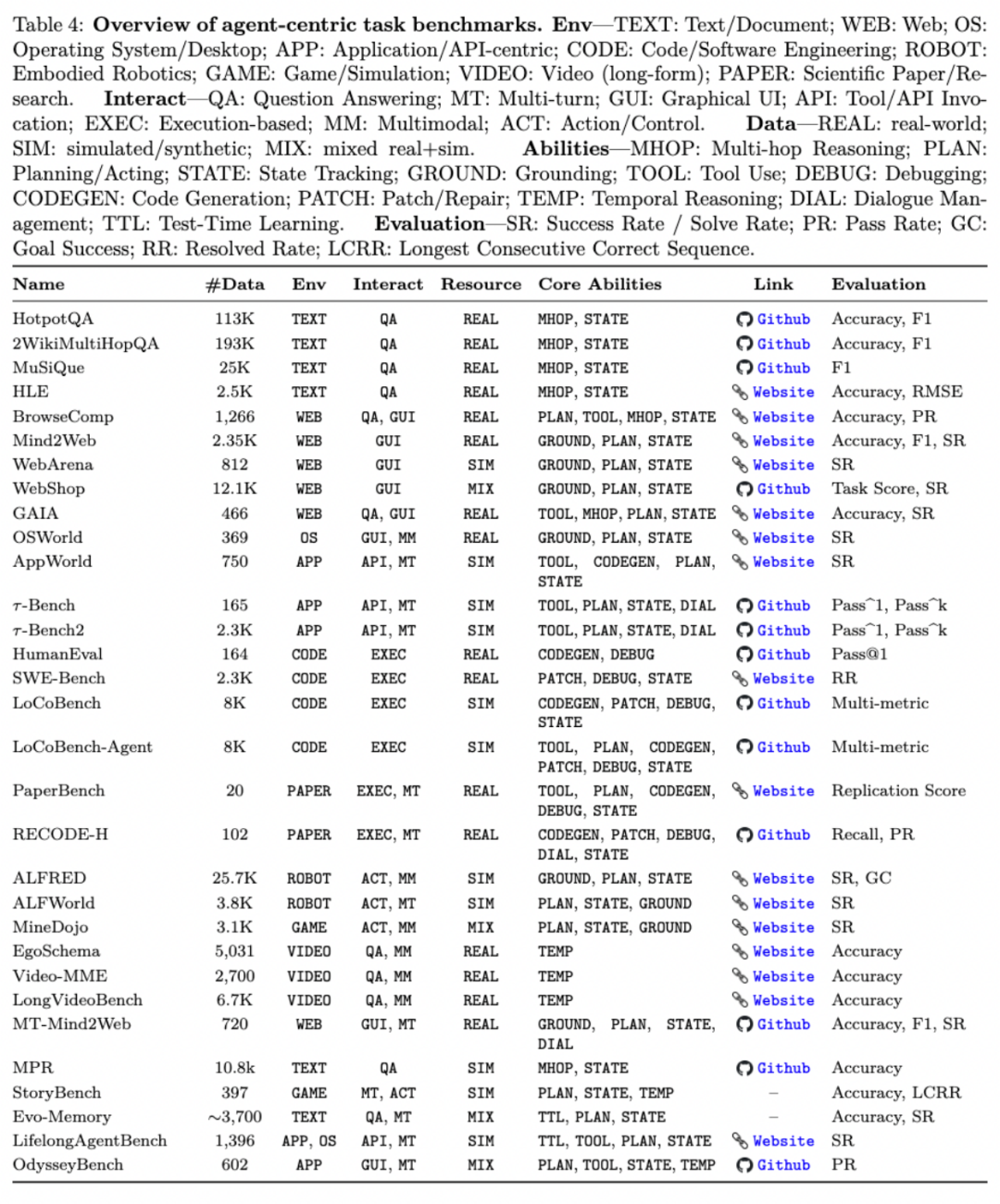
在真实部署中,Agent 面对的不再是静态 prompt,而是动态环境。网页状态在变,文件系统在更新,工具输出不断叠加,权限与约束持续变化。context 的增长不只是对话历史延长,而是跨时间、跨系统、跨任务的状态积累。
因此,memory 的核心挑战不再是 “能存多少”,而是 “如何管理环境状态”。
随着交互时间变长、环境复杂度提升、工具数量增加,context 会沿多个维度扩张。单纯扩大窗口无法解决结构混乱、信息污染和因果断裂的问题。Agent 必须能够结构化存储环境状态,维护可更新、可回溯的内部表示,而不是简单拼接 token。
未来的关键方向是让 memory 策略本身可学习。系统需要学会在长期回报下判断哪些信息值得保留、哪些应被压缩、哪些可以遗忘。这意味着 memory controller 将从规则工程演化为优化目标的一部分。
评测体系也会随之转向。未来 benchmark 的核心不再只是回答是否正确,而是任务是否真正完成、环境状态是否被正确维护、决策是否可追溯。真实世界环境的构建,将成为区分实验室模型与可部署 Agent 的分水岭。

也许几年后我们回头看,会发现:
上半场解决的是模型是否会智能对话。
下半场真正要解决的是:
Agent 能不能帮你把事情做完。

从单轮智能到长期协作,从一次性回答到跨环境执行,AI 的重心正在悄然转移。
决定系统价值上限的,或许不再只是参数规模,而是 memory 的系统级设计能力。
AI 的下半场,这场无硝烟的战场,
已经从系统级记忆体正式打响!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com