一、英伟达的推理秘密武器:Groq LPX (LPU)
英伟达CEO黄仁勋在GTC 2026大会上宣称:“训练只是开启大门的钥匙,推理才是AI商业化的核心战场。AI正在从简单的信息检索演变为复杂的思考、决策和任务执行。在这个‘推理经济’时代,每一瓦特能效所产生的Token价值将决定企业的成败。”
为此英伟达新发布的Vera Rubin平台展示了一个异构计算的“三位一体”形态。
Vera Rubin 超级集群并非单一芯片的演进,而是由 Vera CPU、Rubin GPU 与 Groq LPX (LPU) 构成的异构计算“三位一体”架构。这一架构通过精确的职能分工,解决了大规模 AI 推理中的每一个潜在瓶颈。
在单 Pod(超级集群)规模下,典型的配置比例为:1,152 颗 Rubin GPU、1,088 颗 Vera CPU 以及 2,560 颗 Groq LPX。这种配置确保了计算、逻辑调度与极速解码之间的完美平衡。
· Vera CPU: 针对 AI 智能体场景优化的单线程性能。其每核心带宽比市场平均水平高出 3 倍,确保在 GPU 等待工具调用或处理复杂逻辑调度时,I/O 不会成为拖累。“绝不让 GPU 处于闲置状态”是其设计的核心哲学。
· Rubin GPU: 搭载 HBM4 存储。作为计算密集型任务的核心,它利用 HBM4 的高容量特性处理海量的 KV 缓存(Key-Value Cache)和大规模并行计算。
· Groq LPX (LPU): 基于软件定义的 VLIW(超长指令字)架构。作为解耦式推理加速器,它利用 SRAM 的亚纳秒延迟实现确定性执行(Deterministic Execution)。
核心芯片性能与功能对比



二、AI生成的两个物理阶段:预填充(Prefill)与解码(Decode)
这种从“信息生成”向“逻辑推理”的范式转移,对底层硬件架构提出了严苛的要求。要洞察其中的技术逻辑,我们必须拆解AI生成答案的两个截然不同的物理阶段:预填充与解码。
-
第一阶段:预填充(Prefill)—— 逻辑的“重型卡车”
当你向AI输入一段长达数千字的文档并要求总结时,系统首先进入“预填充”阶段。这一阶段的目标是“消化”并“理解”用户的输入。 在这一阶段,计算机会并行处理输入提示词(Prompt)中的所有Token。由于输入数据是已知的,系统可以利用大规模并行计算,同时在数千个计算核心上铺开任务。这就像一辆载重百吨的“重型卡车”,虽然加速慢、掉头难,但一旦跑起来,单次运载的数据吞吐量(Throughput)巨大。

-
第二阶段:解码(Decode)—— 响应的“极速信使”
“解码”阶段是用户感知最明显的阶段,即你看到AI在屏幕上“吐字”的过程。
解码是“自回归(Autoregressive)”的。为了产生下一个词,AI必须基于之前产生的所有词进行计算,这意味着它一次只能生成一个Token。在这一阶段,处理器每秒能进行万亿次运算,但它必须先从内存中把数据读出来。由于每次只算一个词,计算单元经常处于闲置状态,系统被迫反复等待数据的读取。
解码阶段的三个关键特征:
1.逐个生成: 序列依赖性极强,前一个词不出来,后一个词无法动工。
2.内存带宽受限: 性能瓶颈不在算力,而在内存读取速度,属于“访存密集型”任务。
3.对延迟高度敏感: 决定了AI的“思考感”。如果延迟高,AI就像在结巴;如果延迟极低,AI就像在流式思考。
如果说GPU是重型卡车,那么 Groq 的 LPU(语言处理单元)就是“极速信使”。它摒弃了传统的、需要不断刷新且路径漫长的 DRAM/HBM 内存,转而使用位于芯片内部、离计算核心最近的 SRAM。信使手中总是攥着所需的信件,不需要去偏远的仓库排队取货,从而绕过了存储墙。
-
核心技术:推测性解码(Speculative Decoding)
这是 GPU 与 LPU 联手的终极武器。Groq LPU 作为“草稿模型”,利用其极速响应能力预先生成一批候选 Token。随后,强大的 Rubin GPU 作为“验证模型”进行一次性批量核验。如果 LPU 生成的“草稿”被接受(通常接受率可达 80%-90%),生成速度将实现量级飞跃。

三、CIM技术路线分析:存储介质与计算域的多元化竞争
对于云端服务商(Hyperscalers)和边缘端开发者而言,推理阶段的核心考量不再仅仅是理论峰值算力,而是总拥有成本(TCO)、交互延迟(Interactive Latency)、Token生成速率(Tokens/sec)。存算一体(CIM)通过在存储阵列内原位完成矩阵乘累加(MAC)运算,从硅片层面消除了数据搬运开销,实现了结构性的能效突破。这种架构不仅是性能的优化,更是未来 AI 基础设施在物理极限边缘的必然选择。
CIM 芯片的性能上限受限于底层物理介质的电学特性及计算域(模拟 vs. 数字)的架构选择。底层介质决定了权重的存储密度与挥发性,而计算域则决定了运算的确定性与工艺可扩展性。
存储介质对比分析

模拟 (ACIM) vs. 数字 (DIMC)
· 模拟存内计算 (ACIM): 利用基尔霍夫电流/电荷定律实现并行计算。其优势在于极致的能效比(TOPS/W),在功耗受限的端侧视觉、音频场景中具有绝对优势。然而,ACIM 易受工艺波动(PVT)和随机噪声干扰,限制了其在高精度 LLM 推理中的表现。
· 数字存内计算 (DIMC): 数据全过程在数字域处理。其核心竞争力在于确定性的计算精度和工艺可扩展性。DIMC 能够无缝适配 5nm 及更先进的先进制程,通过数字逻辑规避模拟域的非线性问题,是数据中心级高性能推理的首选。
四、全球CIM芯片厂商对比

-
北美与欧洲领军CIM企业:追求性能极限
西方 CIM 厂商利用先进工艺与复杂的非矩阵操作编排(Non-matrix operations orchestration)技术,瞄准超大规模数据中心与高性能边缘 AI 市场。
· d-Matrix: 数字 CIM 领军者。其当前 Corsair 平台利用 DIMC 架构与 Block Floating Point (BFP) 技术,在维持浮点动态范围的同时实现了 INT8 的计算效率,精准解决了 LLM 的 TCO 痛点。其下一代 Raptor 推理加速器将引入 3D-CIM (3DIMC™),通过 3D 堆叠 DRAM 提供远超 HBM4 的带宽,并利用 Andes AX46MPV (RISC-V) 核心作为编排层,实现 Die-to-die 互联与 All-to-all 拓扑。
· Axelera AI: 欧洲 AI 主权的代表。其 Metis AIPU 采用数字 CIM 与 RISC-V 架构,在边缘侧实现了 214 TOPS 的算力与 15 TOPS/W 的能效。其 Voyager SDK 通过自动化编译与量化,极大地降低了模型部署至空间分布式存储阵列的门槛。
· Mythic:模拟 Flash 计算的先驱。其 M1076 芯片通过在 Flash 阵列中固化 8000 万个参数,消除了外部 DRAM 依赖。在功耗仅 3-4W 的情况下,为无人机和工业视觉提供高吞吐的实时推理能力。
· EnCharge AI: 差异化地采用了基于金属电容的电荷域计算技术。该路径克服了传统阻性模拟计算的信噪比(SNR)瓶颈,使其 EN100 加速器能够以 40 TOPS/W 的极高性能,支持 10B-20B 参数的模型在 AI PC 端本地运行。
-
中国 CIM 生态系统:自主创新与大规模商业化落地
在中国“半导体主权”与“国产算力体系”的战略驱动下,CIM 被视为在成熟工艺节点实现对先进制程 GPU/NPU 性能超越的“换道超车”利器。
· 知存科技 (Witmem): Flash-CIM 商业化标杆。其 WTM2101 已在可穿戴设备中大规模应用;旗舰 WTM-8 针对 4K 影像与 AR/VR 场景,在 3W 低功耗下提供 24 TOPS 算力,证明了模拟存存在垂直领域的爆发力。
· 后摩智能 (Houmo Tech): 专注于 SRAM 路径的“大算力”场景。其产品突破了 CIM 仅限于微功耗应用的刻板印象,针对 L3/L4 自动驾驶的高吞吐需求,利用 SRAM 的低延迟特性实时处理海量传感器数据。
· 微纳核芯 (Micro-Nano): 3D-CIM 范式的引领者。通过 3D 近存堆叠与原位张量计算,其架构能实现在 22nm 工艺下达到传统 7nm 芯片的算力密度,实现 5-10 倍的效率提升。作为 RISC-V 存算一体标准牵头人,其“恒山”系列正加速大模型在端侧的落地方案。
· 迈特芯 (MateChip): 深耕“具身智能”赛道,采用 SRAM-CIM (MMSCIM) 路径。其端侧 LPU 芯片针对仿生机器人与个人智能体的实时推理进行了深度优化,在 22nm 成熟工艺下通过模数混合技术平衡了精度与能效,支持医疗与工业机器人的离线交互。
-
全球 CIM 竞争图谱:多维度横向基准测试
衡量 CIM 价值的核心逻辑已从峰值 TOPS 转向“单位成本下的有效吞吐量”。
核心厂商性能基准表

*注:d-Matrix 性能指 8 卡服务器集群 MXINT8 表现。Groq LPU 虽同属推理加速,但其基于静态调度逻辑,不属于物理层面的 CIM 范式。
五、战略分析及技术趋势展望
CIM 已成为国家级 AI 战略博弈的焦点。其战略逻辑在于:CIM 允许在 22nm/28nm 等成熟制程上实现 7nm 级别 GPU 的性能,这对于规避先进制程 EUV 设备限制、构建“硅片主权”具有决定性意义。
· 资本信心:d-Matrix (Series C, 275M美元)与 Axelera AI (250M美元) 的巨额融资证明了资本市场对取代 GPU 推理架构的紧迫感。
· 中国动态: 微纳核芯(B轮 >1亿 RMB)与迈特芯(Pre-A >1亿 RMB)的快速融资,反映了战略资本正向具备“具身智能”与“3D 堆叠”能力的团队倾斜。
· TCO 驱动: 对于云服务商,CIM 的吸引力在于能以极低的电力和空间成本,实现单节点内以前需要一整机架 GPU 才能达到的吞吐,这种效率优势是抛弃通用架构转向专用 CIM 的核心诱因。
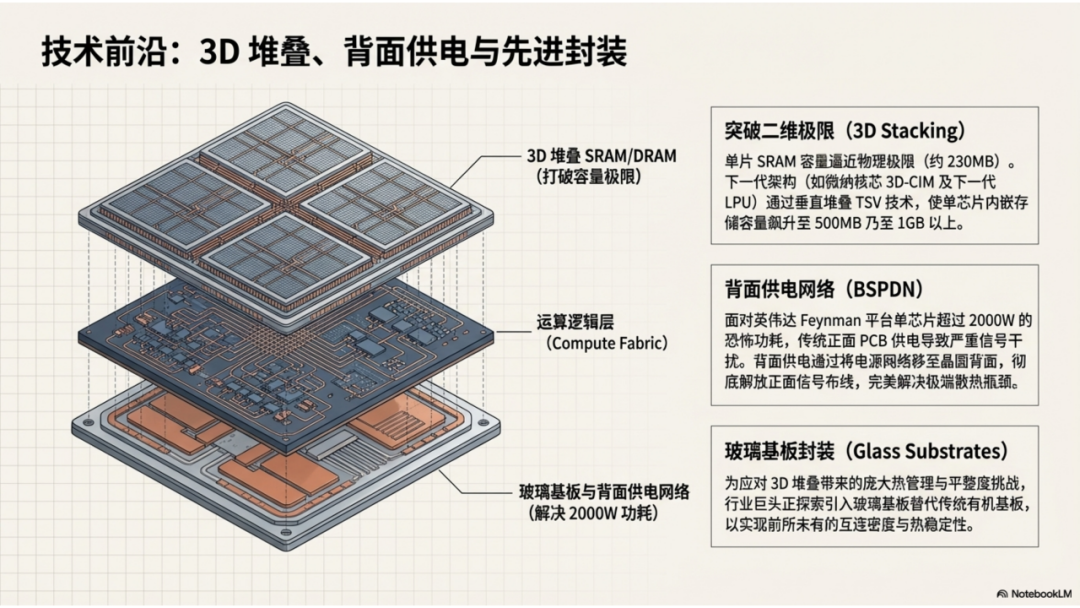
· 3D 垂直集成: 3D-CIM 将成为解决带宽瓶颈的终极方案。通过垂直封装,存储不再是计算的“邻居”,而是其“载体”,使端侧设备具备承载万亿参数模型的能力。
· 显著性计算与混合架构: 结合数字 CIM 的确定性与模拟 CIM 的能效,根据数据显著性(Saliency)动态调节精度。在非关键区域(如视频背景)使用低精度模拟计算,在关键区域使用高精度数字计算。
· 软件栈的“护城河”效应: 硬件的物理优势必须通过编译器(如 Aviator, Voyager)与 MLIR 生态转化为易用性。未来的赢家将是那些能无缝对接 PyTorch、并能实现自动化模型映射与权重编排的厂商。
结语: 存算一体技术正从实验室走向全球 AI 基础设施的底座。在AI推理时代,CIM 将以其无可比拟的 TCO 优势和对成熟制程的性能激发,成为定义全球人工智能算力主权的战略基石。