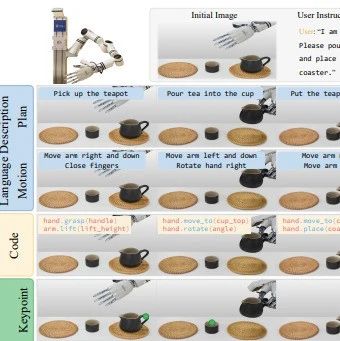
作者:InternLM、Qwen 等 LLM

本篇 ICML 2025 强化学习领域的Oral论文精选,涵盖了从基础理论到前沿应用的多个热门方向。这些研究共同推动着智能体向更强大、更安全、更协作的未来迈进。具体来看,这些论文可以归纳为以下几个细分领域:
强化学习理论与算法:深入探索了强化学习的基础问题。例如,通过引入网络稀疏性来打破深度强化学习的扩展瓶颈;在约束强化学习中,通过控制价值函数的估计偏差来实现更安全的探索;以及对高斯过程老虎机问题进行更精细的遗憾分析,在多个关键设置下达到了理论最优性。 大语言模型与推理:聚焦于提升大语言模型(LLM)作为智能体核心的推理与规划能力。例如,通过自进化和深度思考机制,让小型语言模型在复杂的数学推理任务上比肩甚至超越顶级模型;通过引入自省式推理,使模型在面对安全风险时能进行深度分析而非本能地拒绝,从而构建更鲁棒的安全防线。 人机交互与协作:致力于改善智能体与人类的交互模式,从被动的指令执行者转变为主动的协作者。相关研究通过优化多轮对话的长期回报,使模型能够主动引导、澄清和启发,显著提升了复杂任务中的协作效率和用户满意度。 奖励模型:关注如何为复杂任务提供更精确的指导信号。例如,通过合成数据构建了能够泛化到法律、生物等多个领域的通用过程奖励模型(PRM),解决了现有PRM仅限于数学领域的局限性。
【1】【rStar-Math: 小型语言模型通过自进化深度思考掌握数学推理】
论文英文标题:
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
论文链接:
https://icml.cc/virtual/2025/poster/46400
论文中文摘要:
我们提出了rStar-Math,证明了小型语言模型(SLM)可以在不依赖卓越模型蒸馏的情况下,达到甚至超越OpenAI o1的数学推理能力。rStar-Math通过蒙特卡洛树搜索(MCTS)实现“深度思考”,其中数学策略SLM在基于SLM的过程奖励模型的引导下执行测试时搜索。rStar-Math引入了三项创新来解决训练这两个SLM的挑战:(1)一种新颖的代码增强的思维链(CoT)数据合成方法,该方法执行广泛的MCTS推演以生成逐步验证的推理轨迹,用于训练策略SLM;(2)一种新颖的过程奖励模型训练方法,避免了天真的步骤级分数标注,从而产生更有效的过程偏好模型(PPM);(3)一种自我进化方案,其中策略SLM和PPM从零开始构建并迭代进化以提高推理能力。通过对74.7万个数学问题进行4轮自我进化和数百万次合成解答,rStar-Math将SLM的数学推理能力提升至最先进水平。在MATH基准测试中,它将Qwen2.5-Math-7B的成绩从58.8%提升到90.0%,超过o1-preview达4.5%。在美国数学奥林匹克竞赛(AIME)中,rStar-Math平均解决了53.3%(8/15)的问题,跻身顶尖20%的高中数学优等生之列。
核心图片:

文章推荐理由:
本文的核心亮点在于提出了一种让小型语言模型(SLM)在数学推理上实现“越级”表现的自进化框架。它不依赖于从GPT-4等更强模型进行知识蒸馏,而是通过一套精巧的“自力更生”机制,让SLM自己生成高质量训练数据并不断迭代增强自身能力。其三大创新点极具价值:1)代码增强的CoT数据合成方法,利用MCTS和代码执行来确保推理路径每一步的正确性,解决了合成数据质量低的难题;2)新颖的过程偏好模型(PPM)训练范式,通过学习偏好对而非具体分数值,有效规避了奖励标注噪声问题;3)四轮自进化配方,使得策略模型和奖励模型能从零开始、螺旋式上升。最终,7B模型在顶级数学竞赛基准上超越OpenAI o1,为构建强大而高效的专用小模型提供了全新的思路。
【2】【CollabLLM: 从被动响应者到主动协作者】
论文英文标题:
CollabLLM: From Passive Responders to Active Collaborators
论文链接:
https://icml.cc/virtual/2025/poster/45988
论文中文摘要:
大型语言模型通常使用下一轮奖励进行训练,这限制了它们优化长期交互的能力。因此,它们在处理模糊或开放式用户请求时常常被动响应,无法帮助用户达成最终意图,导致对话效率低下。为了解决这些限制,我们引入了COLLABLLM,这是一个新颖且通用的训练框架,旨在增强多轮人机-LLM协作。其关键创新是一种协作模拟,利用“多轮感知奖励”(Multiturn-aware Rewards)来评估响应的长期贡献。通过对这些奖励进行强化微调,COLLABLLM超越了简单响应用户请求的范畴,能够主动发掘用户意图并提供有见地的建议——这是迈向更以人为中心的AI的关键一步。我们还设计了一个包含文档创建等三个挑战性任务的多轮交互基准。根据LLM评判,COLLABLLM的表现显著优于基线,任务性能平均提高18.5%,交互性提高46.3%。最后,我们进行了一项有201名评判者参与的大型用户研究,COLLABLLM使用户满意度提高了17.6%,并减少了用户10.4%的时间花费。
核心图片:
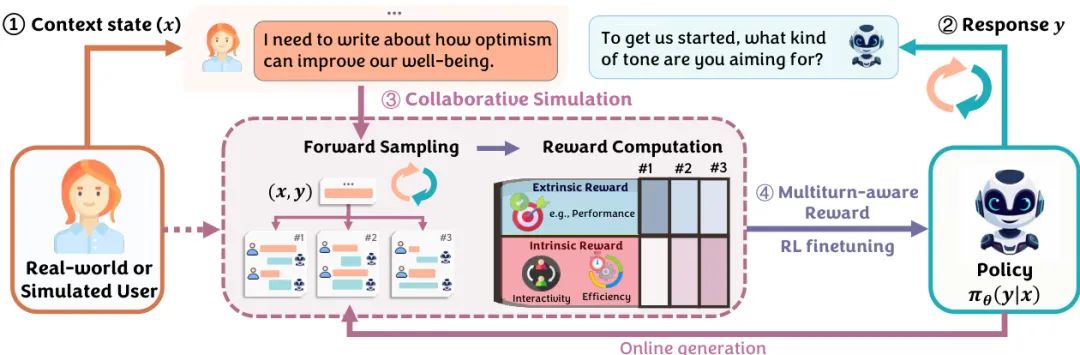
文章推荐理由:
本文直击当前LLM在复杂任务中“一问一答”式的被动交互痛点,提出了一个旨在培养LLM主动协作能力的训练框架CollabLLM。其核心思想极具前瞻性:从优化单轮回复的“近视”目标,转向优化整个对话长期价值的“远视”目标。关键创新在于“多轮感知奖励”(MR),它通过与用户模拟器进行前瞻性对话模拟,来估算当前回复对未来多轮交互的整体贡献,而不仅仅是即时效果。通过强化学习优化该奖励,模型学会了在适当的时候提出澄清性问题、提供建设性意见,从而更高效地引导用户完成任务。该研究不仅在自动化指标上表现优异,更通过大规模真实用户研究验证了其在提升用户满意度和节省时间方面的实际价值,为构建真正智能的AI协作者指明了方向。
【3】【STAIR: 通过自省式推理提升安全对齐】
论文英文标题:
STAIR: Improving Safety Alignment with Introspective Reasoning
论文链接:
https://icml.cc/virtual/2025/poster/44809
论文中文摘要:
确保大型语言模型(LLM)的安全性和无害性已变得与其在应用中的性能同等重要。然而,现有的安全对齐方法通常存在安全与性能之间的权衡,并且容易受到越狱攻击的影响,这主要是因为它们依赖于对恶意查询的直接拒绝。在本文中,我们提出了STAIR,一个将安全对齐与自省式推理相结合的新框架。我们通过利用具有安全意识的自增强思维链(CoT)推理,使LLM能够通过逐步分析来识别安全风险。STAIR首先为模型赋予结构化的推理能力,然后通过对我们新提出的安全信息蒙特卡洛树搜索(SI-MCTS)生成的步骤级推理数据进行迭代偏好优化来推进安全对齐。具体来说,我们设计了一个有理论依据的结果评估奖励,以寻求在有用性和安全性之间取得平衡。我们进一步在该数据上训练一个过程奖励模型,以指导测试时的搜索,从而改进响应。大量实验表明,与本能的对齐策略相比,STAIR有效减轻了有害输出,同时更好地保持了有用性。通过测试时扩展,STAIR在对抗流行的越狱攻击时,实现了与Claude-3.5相当的安全性能。
核心图片:

文章推荐理由:
本文深刻洞察到当前LLM安全对齐方法的“浅层”本质——即通过模板化拒绝来应对恶意请求,这种方式极易被“越狱”攻击绕过。为此,论文提出了STAIR框架,其核心思想是从依赖本能的“系统1”式快速拒绝,转向深思熟虑的“系统2”式自省推理。该框架训练模型在回答前,先通过结构化的思维链(CoT)对请求进行风险分析。其实现路径清晰且优雅:首先进行格式对齐,然后利用创新的“安全信息蒙特卡洛树搜索”(SI-MCTS)进行自我迭代提升,该搜索使用自奖励机制生成高质量的推理偏好数据,最终通过测试时搜索进一步增强效果。STAIR不仅显著提升了模型抵御复杂攻击的鲁棒性,还成功缓解了安全性和实用性之间的固有矛盾,为构建真正可信的AI系统提供了坚实的技术路径。
【4】【VersaPRM: 通过合成推理数据实现的多领域过程奖励模型】
论文英文标题:
VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
论文链接:
https://icml.cc/virtual/2025/poster/44223
论文中文摘要:
过程奖励模型(PRM)通过利用增加的推理时间计算,已被证明能有效增强大型语言模型(LLM)的数学推理能力。然而,它们主要在数学数据上进行训练,其在非数学领域的泛化能力尚未得到严格研究。为此,本研究首先表明当前的PRM在其他领域表现不佳。为了解决这一局限,我们引入了VersaPRM,一个在利用我们新颖的数据生成和注释方法生成的合成推理数据上训练的多领域PRM。VersaPRM在不同领域均实现了持续的性能提升。例如,在MMLU-Pro的法律类别中,VersaPRM通过加权多数投票,相比多数投票基线实现了7.9%的性能增益,超过了Qwen2.5-Math-PRM的1.3%增益。我们通过开源VersaPRM的所有数据、代码和模型,为社区做出进一步贡献。
核心图片:
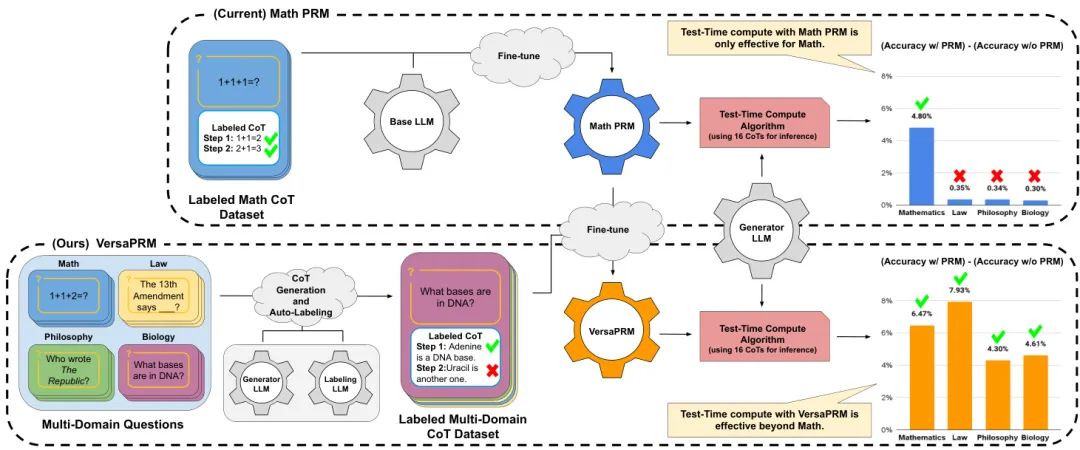
文章推荐理由:
这篇论文解决了一个非常实际且重要的问题:当前先进的过程奖励模型(PRM)大多是“数学偏科生”,无法有效评估法律、生物等其他领域的推理过程。文章首先用实验清晰地指出了这一泛化能力的短板。其核心贡献是提出了VersaPRM——一个通用的、跨领域的PRM,以及一套可扩展的合成数据生成方案。该方案利用LLM作为生成器和标注器,高效地创建了覆盖多个领域的、带有步骤级标签的思维链数据,成功绕开了昂贵的人工专家标注瓶颈。通过在这个多样化的合成数据集上对现有数学PRM进行微调,VersaPRM在多个非数学领域的推理任务上取得了显著的性能提升。这项工作不仅提供了一个强大的通用PRM,还开源了宝贵的数据集和方法,为社区构建更具普适性的推理评估工具铺平了道路。
【5】【网络稀疏性解锁深度强化学习的扩展潜力】
论文英文标题:
Network Sparsity Unlocks the Scaling Potential of Deep Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/44160
论文中文摘要:
有效扩展深度强化学习模型一直以来都因训练过程中的网络病态问题而异常困难,这促使了各种针对性干预措施的出现,如周期性重置和层归一化等架构进步。我们没有寻求更复杂的修改,而是表明,仅引入静态网络稀疏性就能够解锁超越其密集对应模型(即使是采用最先进架构)的进一步扩展潜力。这是通过简单的一次性随机修剪实现的,即在训练前一次性随机移除预定百分比的网络权重。我们的分析表明,与简单地扩展密集的DRL网络相比,这种稀疏网络在网络表达能力方面实现了更高的参数效率,并对可塑性损失和梯度干扰等优化挑战具有更强的抵抗力。我们进一步将评估扩展到视觉和流式RL场景,证明了网络稀疏性的一致性优势。
核心图片:

文章推荐理由:
这篇论文挑战了深度强化学习(DRL)中一个普遍的困境:模型并非越大越好,盲目增加网络规模常导致性能下降。其核心发现既惊人地简单又十分强大:在训练开始前,仅通过一次性的随机剪枝引入静态稀疏性,就能突破当前最先进的密集网络架构(如SimBa)的扩展瓶颈。作者通过实验证明,随着模型规模的增大,稀疏网络能更有效地抵抗可塑性损失、梯度干扰等DRL训练中的常见“病症”,从而实现更高的参数效率,让性能随规模增长而持续提升。这项工作的巧妙之处在于其干预措施的极简性——仅在初始化时进行一次剪枝,无需复杂的动态调整。这一发现为DRL社区提供了一个极具实践价值的启示,为如何有效扩展并提升RL智能体的能力指明了一个更高效的新方向。
【6】【控制约束强化学习中的欠估计偏差以实现安全探索】
论文英文标题:
Controlling Underestimation Bias in Constrained Reinforcement Learning for Safe Exploration
论文链接:
https://icml.cc/virtual/2025/poster/44096
论文中文摘要:
约束强化学习(CRL)旨在最大化累积奖励的同时满足约束条件。然而,现有的CRL算法在训练过程中常常出现严重的约束违反,限制了它们在安全关键场景中的应用。在本文中,我们确定成本价值函数的欠估计是导致这些违规的关键因素。为了解决这个问题,我们提出了记忆驱动的内在成本估计(MICE)方法,该方法引入内在成本以减轻欠估计,并控制偏差以促进更安全的探索。受人类通过生动回忆危险经历以规避风险的“闪光灯记忆”启发,MICE构建了一个记忆模块,存储先前探索过的不安全状态以识别高成本区域。内在成本被表述为当前状态访问这些风险区域的伪计数。此外,我们提出了一个结合内在成本的内外在成本价值函数,并采用偏差校正策略。利用该函数,我们在信任区域内构建了一个优化目标,并提供了相应的优化方法。理论上,我们为所提出的成本价值函数提供了收敛性保证,并为MICE更新建立了最坏情况下的约束违反界限。大量实验证明,MICE在保持与基线相当的策略性能的同时,显著减少了约束违反。
核心图片:

文章推荐理由:
本文精准地指出了约束强化学习(CRL)在训练中频繁违反安全约束的一个核心却易被忽视的根源:对成本价值函数的欠估计。这种欠估计会误导智能体认为高风险行为是安全的,从而导致灾难性后果。论文提出的MICE算法,其灵感源于人类心理学的“闪光灯记忆”——对危险经历的深刻印象。MICE为智能体建立了一个记录高成本状态的记忆模块,当智能体再次接近类似危险区域时,会产生一个“内在成本”。这个内在成本作为一种前瞻性的安全信号,补偿了被低估的外在成本,从而引导智能体进行更谨慎、更安全的探索。该方法不仅构思巧妙、符合直觉,而且具备坚实的理论基础,包括收敛性保证和约束违反上界。通过从根源上解决不安全探索问题,MICE为开发更可靠、能部署于安全关键应用的RL智能体迈出了重要一步。
【7】【高斯过程老虎机中的改进遗憾分析:在无噪声奖励、RKHS范数和非平稳方差下的最优性】
论文英文标题:
Improved Regret Analysis in Gaussian Process Bandits: Optimality for Noiseless Reward, RKHS norm, and Non-Stationary Variance
论文链接:
https://icml.cc/virtual/2025/poster/43519
论文中文摘要:
我们研究了高斯过程(GP)老虎机问题,其目标是在某个再生核希尔伯特空间(RKHS)中的未知奖励函数下最小化遗憾。最大后验方差分析对于分析近乎最优的GP老虎机算法(如最大方差缩减(MVR)和分阶段消除(PE))至关重要。因此,我们首先展示了最大后验方差的新上界,该上界改进了对GP噪声方差参数的依赖性。利用这一结果,我们改进了MVR和PE,以获得(i)在无噪声设置下近乎最优的遗憾上界,以及(ii)在奖励函数的RKHS范数方面最优的遗憾上界。此外,作为我们提出的界限的另一个应用,我们分析了时变噪声方差设置下的GP老虎机,这是具有异方差噪声的线性老虎机的核化扩展。对于这个问题,我们表明基于MVR和PE的算法实现了依赖于噪声方差的遗憾上界,这与我们的遗憾下界相匹配。
文章推荐理由:
本文对高斯过程(GP)老虎机这一经典问题做出了重大的理论贡献。其核心突破在于推导出了一个更紧的最大后验方差上界,这是分析GP老虎机算法性能的关键。这一项技术性的改进,如同一把钥匙,解锁了一系列先前难以解决的问题。作者基于此,对现有算法(MVR和PE)的分析进行了深化,并在三个具有挑战性的场景中取得了最优或近乎最优的遗憾界:(1)无噪声环境;(2)遗憾界对奖励函数RKHS范数的最优依赖性;(3)首次系统分析了带有非平稳(时变)噪声的GP老虎机问题。尤其在第三点,作者不仅提出了近乎最优的算法,还推导出了匹配的理论下界,完美地解决了该设置下的理论空白。这项工作极大地加深了我们对GP老虎机问题的理解,并将其理论分析推向了新的高度。
-- 完 --
机智流推荐阅读:
1. AI时代,你的速度决定了你的高度:吴恩达YC创业学校万字干货
2. ICCV25 | AI终于分清照片中的前景和背景了!探索南开DenseVLM在密集预测中的区域-语言对齐策略
3. 发个福利,可以免费领WAIC2025(世界人工智能大会·上海)单日门票
4. ICML 2025最佳论文花落谁家?120篇Oral前沿一网打尽!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
在「机智流」公众号后台回复下方标红内容即可加入对应群聊:
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群