点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享字节团队被ICCV 2025接收的大模型相关工作——Dynamic-VLM,一种用于视频大语言模型(VideoLLM)的简单动态视觉Token压缩方法,以及一个高质量的合成视频 - 文本数据集,显著提升了VideoLLM的性能与实用性。如果您有相关工作需要分享,请在文末联系我们!
论文标题:Dynamic-VLM: Simple Dynamic Visual Token Compression for VideoLLM
论文作者:Han Wang等
作者单位:字节
论文链接:https://arxiv.org/pdf/2412.09530
开源链接:https://github.com/Hon-Wong/ByteVideoLLM
突破VideoLLM瓶颈!Dynamic-VLM用动态压缩技术重新定义视频理解
你是否注意到,当用AI模型分析短视频时,细节识别精准度很高,但面对长达数小时的纪录片或直播录像时,模型常常"顾此失彼"——要么漏掉关键帧信息,要么因计算过载导致响应迟缓?
今天要分享的Dynamic-VLM论文,正是为解决这个痛点而来。作为字节团队被ICCV 2025接收的研究成果,它提出的动态视觉Token压缩技术,让大模型既能"显微镜式"解析短视频细节,又能"望远镜式"把握长视频脉络,彻底打破了VideoLLM处理不同长度视频时的性能瓶颈。
大模型的视觉进化:从图片到视频的跨越
近年来,GPT-4V、Gemini-1.5等多模态大模型掀起了视觉语言理解革命。这些模型像拥有"双瞳"的智能体,既能读懂文字,又能看懂图像和视频。但你知道吗?处理视频可比处理图片复杂得多——一段10分钟的视频就包含 thousands of frames,如何在不超出模型上下文限制的前提下,保留关键信息又不冗余,成了研究者的噩梦。
传统VideoLLM的做法相当"死板":无论视频长短,都用固定比例压缩视觉Token(如图1a所示)。就像用同样大小的容器装水,短视频装不满浪费空间,长视频装不下被迫挤压,结果要么信息不足,要么细节丢失。

图1. 现有研究成果与我们的Dynamic-VLM的对比展示。我们为视觉内容采用了灵活的Token压缩器,能够以不同的Token数量处理不同长度的视频。对于短视频,我们保持Token不压缩以提供详细信息;对于长视频,我们采用高压缩比以增强时间维度的细节。为简洁起见,图示中未包含视觉编码器。
动态压缩:让模型学会"量体裁衣"
Dynamic-VLM的核心创新,是给模型装上了"智能调节阀"(图1b):
短视频精细模式:对十几秒的短视频,保持高分辨率Token,连画面里的文字、小物体都清晰捕捉 长视频高效模式:对小时级长视频,自动提高压缩比,重点保留时间线脉络和场景转换
这种"按需分配"的策略,完美平衡了计算效率与信息完整性。打个比方,就像相机自动切换焦距——拍近处花朵用微距,拍远方风景用广角,始终让关键信息处于"清晰区"。
数据困境:视频理解的隐形天花板
除了技术架构,数据短缺是另一个"卡脖子"问题。目前图像领域已有海量高质量标注数据,但视频领域却严重不足。现有VideoLLM大多只能"吃老本",用图片数据+少量视频片段勉强训练,导致处理真实视频时常常"水土不服"。
Dynamic-VLM团队直击这个痛点,用GPT-4V和GPT-4o生成了大规模视频问答数据。

揭秘Dynamic-VLM的"智能压缩引擎":让视频理解既精准又高效

图2. 对于每个视频,我们使用视觉Transformer(ViT)为每个关键帧独立提取视觉Token。这些视觉Token在与时间戳文本和指令一同输入大语言模型(LLM)之前,会通过动态压缩器进行压缩。我们探讨了三种潜在的动态压缩器方案。
先看整体架构:三部分组成的"视频理解流水线"
就像工厂加工产品需要流水线,Dynamic-VLM处理视频也有一套标准流程。它的整体架构由三个核心模块组成:
视觉编码器:相当于"眼睛",负责把视频帧转换成计算机能理解的视觉特征(默认用CLIP-ViT-Large模型) LLM大语言模型:相当于"大脑",负责解读视觉信息并生成回答(默认用Qwen2.5系列) 模态连接器:相当于"神经突触",把视觉特征转换成语言模型能处理的Token
这套组合拳的关键,就藏在视觉特征到Token的转换环节——传统模型用"固定压缩器",而Dynamic-VLM用的是"动态压缩器",这一字之差,带来了天翻地覆的变化。
动态压缩器:给视频"智能瘦身"的三种方案
想象一下,你手机里有100张照片要传给朋友:
拍文档的照片需要高清,不然字看不清 随手拍的风景照稍微压缩一下也不影响观感
Dynamic-VLM的压缩器就像个"智能相册管家",会根据视频长度和内容自动调整压缩策略。论文里提出了三种具体方案:
1. 动态空间池化
最简单直接的方法:用自适应池化技术调整视觉Token的尺寸。比如把原本28×28的Token矩阵,根据需要压缩成4×4到28×28之间的任意尺寸。就像调整图片分辨率,短视频用高分辨率保留细节,长视频用低分辨率节省空间。
2. 动态Token合并
更智能的"相似合并":通过计算Token间的余弦相似度,把内容相似的Token合并成一个。比如视频里连续5帧都是同一场景,就自动合并成1个代表性Token。这种方法特别适合处理重复画面多的视频(比如监控录像)。
3. 动态Token修剪
最精准的"精华提取":用神经网络给每个Token打分,只保留分数最高的前K个Token。就像看电影时只挑关键剧情片段,既能抓住核心信息,又能大幅减少数据量。
这种灵活性带来两个核心优势:
细节与效率的平衡:短视频不丢细节,长视频不卡计算 场景自适应:无论是快节奏的体育比赛(需要多Token抓瞬间),还是慢节奏的讲座(少Token抓逻辑),都能完美适配
200万条视频问答数据是怎么来的?揭秘Dynamic-VLM的"训练养料"

图3. 我们合成数据中不同任务的分布情况。
训练大模型就像培育参天大树,优质数据是必不可少的"土壤"。在视频理解领域,长期存在高质量标注数据短缺的问题,Dynamic-VLM之所以能表现出众,关键在于它构建了一套规模达200万条的视频-文本数据集。
raw数据:从三大宝库精选素材
不同于有些研究直接使用现有基准测试集的视频(容易导致"刷分"嫌疑),Dynamic-VLM的原始视频全部来自三个未被基准测试用过的"处女地":
WebVid-10M:包含1000万条短视频,多来自网络创意内容 InternVid-10M:1000万条多样化视频,涵盖生活、教育等场景 HDVILA-100M:1亿条高清长视频,甚至有小时级纪录片、讲座
为保证数据质量,团队先对WebVid和InternVid做了"去重手术"——通过比对原始字幕,剔除重复内容;再用类似LLaVA的过滤流水线,筛选出信息量丰富的视频。对HDVILA则保留原始长度,最多抽取256帧,确保模型能学到长视频的时间脉络。
任务设计:5大类别覆盖视频理解全场景
就像学生需要全面的课程表,模型也需要多样化的训练任务。数据集涵盖5大类任务,每类都精准击中视频理解的核心能力:
感知任务(46.8万条):让模型识别画面中的实体、动作、位置和属性。特别要求避免"一个人""某个东西"这类模糊表述,逼模型说清"穿红衬衫的男人在挥手" 通用任务(92.8万条):包括重新字幕生成、细节描述、情感分析、故事创作,强化模型的语言表达能力 时间任务(30万条):针对视频的"时间维度"设计,比如给<Frame 5>加字幕、问"30秒时发生了什么",甚至无时间戳的"先下雨还是先打雷" 推理任务(35.3万条):最烧脑的部分,比如"为什么主角打开冰箱",需要模型结合画面细节做逻辑推导 格式化任务(2万条):专门训练模型适应考试场景,比如多选QA只输出选项字母,开放问答用简洁语言
幕后功臣:GPT-4V和GPT-4o当"出题官"
数据集的问答对不是人工标注的,而是请闭源大模型当"老师"生成:
对短视频(WebVid、InternVid):用宽泛提示词让模型自由出题,覆盖更多场景 对长视频(HDVILA):设计深度提示词,引导模型关注复杂时间逻辑和细节推理
最后经过格式清洗(比如把<Frame 3>转成"3秒处"),得到200万条高质量数据。对比现有视频数据集(大多10万级、仅覆盖短场景),这套数据在规模、时长多样性、任务全面性上都实现了突破。
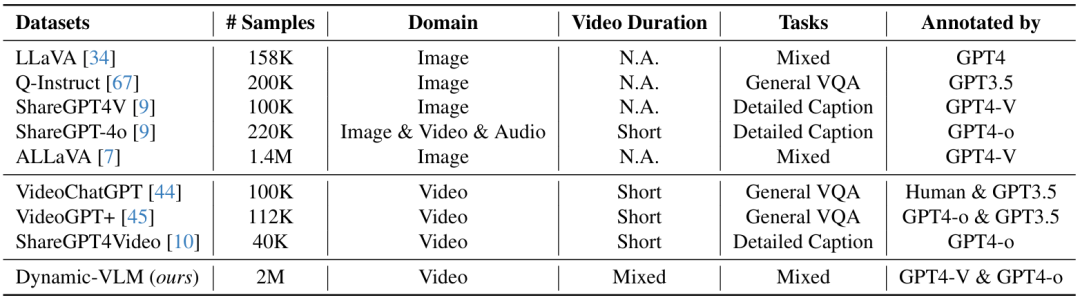
表1. 不同数据集的对比。短视频时长意味着这些数据集不包含时长为小时级别的视频。
看看数据对比表就知道:现有开源视频数据集要么规模小(如VideoGPT+仅11.2万条),要么全是短视频(如ShareGPT4Video),要么任务单一(如仅做字幕)。而Dynamic-VLM的数据集:
规模是同类开源集的10-20倍 首次纳入小时级长视频数据 任务覆盖从基础识别到高阶推理
有了这样的"营养餐",模型才能既懂细节又通全局,为后续动态压缩技术的落地打下坚实基础。
从预训练到指令微调:Dynamic-VLM的训练秘籍大公开
预训练阶段:给模型打下"视觉认知"基础
训练的第一步不是直接喂视频数据,而是让模型先掌握"看图片"的基本功:
热身训练:先用llava-558K图像数据集预训练,只解冻动态压缩器参数。这一步就像学画先练素描,让压缩器学会如何合理提取图像特征。 混合精调:接着用ALLaVA、ShareGPT4V等高质量图文数据集进行端到端训练,解冻所有参数。此时模型开始融合视觉与语言能力,比如描述图片细节、回答图像相关问题。
这个阶段的小技巧:过滤掉数据中重复的模式化标注,避免模型学"废话";统一用"You are a helpful visual assistant"作为系统提示词,保持训练一致性。
视觉指令调优:强化"看图说话"的通用能力
虽然目标是视频理解,但团队发现:先练好在图像任务上的本领,能显著提升后续视频处理能力。因此加入了大规模视觉指令调优:
通用视觉问答:整合ALLaVA、VQAv2等12个数据集,覆盖日常场景问答(如"图中有几只猫")、常识推理(如"为什么这棵树叶子黄了")。 OCR专项训练:专门加入文档问答、图表解读等数据,强化模型识别画面文字的能力——要知道,视频里的字幕、路标等文本信息,往往是理解剧情的关键。
视频指令调优:正式开启"看视频"的核心训练
在前两步基础上,模型终于开始"专攻"视频任务:
训练数据:以团队自建的200万条视频问答数据为主,混合PerceptionTest、NextQA等公开视频数据集的训练集。
输入格式:将视频转换成带时间戳的序列,比如"1s: <image>; 2s: <image>",让模型明确帧与时间的对应关系。
关键参数:设置16K上下文窗口,足够容纳长视频的处理需求;每帧的Token数从[16, 576]随机采样,强迫模型适应动态压缩逻辑。
通过随机调整每帧Token数,模型在训练时就学会"该用多少Token描述一帧",推理时自然能根据视频长度灵活决策。
训练细节里的"门道"
学习率分层:LLM和压缩器用2e-5的学习率,视觉编码器(ViT)用1/5的速率,避免预训练好的视觉特征被破坏。 batch size:固定128的批处理量,平衡训练效率和参数更新稳定性。 数据过滤:严格剔除重复标注和无意义问答,确保喂给模型的每一条数据都有"营养"。
经过这三轮训练,Dynamic-VLM就像从"看图识字"升级到"看视频写影评",既保留了图像理解的精细度,又掌握了视频特有的时间维度理解能力。
横扫各大榜单!Dynamic-VLM用实力证明:动态压缩才是视频理解的未来
三大测试维度,全面检验视频理解能力
研究团队没有选择"偏科式"测试,而是搭建了覆盖视频理解全场景的评估体系:
开放式视频问答:让模型自由回答关于视频的问题(如"视频里的人在做什么"),考验自然语言生成与视觉信息的结合能力。测试数据集包括MSVD-QA、MSRVTT-QA等公认难啃的"硬骨头"。 多选视频问答:给出问题和多个选项(如"视频中先发生的是A还是B"),更客观地衡量模型的事实性理解能力。选用VideoMME、TempCompass等权威 benchmark,其中VideoMME被称为"视频理解的高考",涵盖50+细分任务。 跨图问答(零样本):给模型多幅无时间关联的图片,让它回答相关问题。这项测试最惊艳——Dynamic-VLM从未专门训练过这类任务,却能"举一反三",证明其通用理解能力的强大。
实验结果亮点

表2. 开放式视频问答的结果。许多研究未明确说明所使用的GPT版本,因此我们在其各自的GitHub仓库中进行了检索以获取该信息。对于在论文或仓库中均无法找到版本信息的方法,我们将其版本标记为“N/A”。需要注意的是,API版本可能会对最终指标产生显著影响(根据FreeVA的研究,差异可超过10个绝对百分点)。因此,为了进行公平评估,最好使用相同的API版本对模型进行比较。

表3. 多项选择视频问答的结果。我们将我们的Dynamic-VLM与闭源模型、更大规模的模型以及同等规模的模型进行了比较。在参数规模为70亿至140亿的模型中,我们的Dynamic-VLM表现最佳,甚至超过了一些更大规模的模型,并且在VideoMME(无字幕/有字幕)上的性能与GPT-4o mini相当。“N/A”表示该模型为闭源模型。
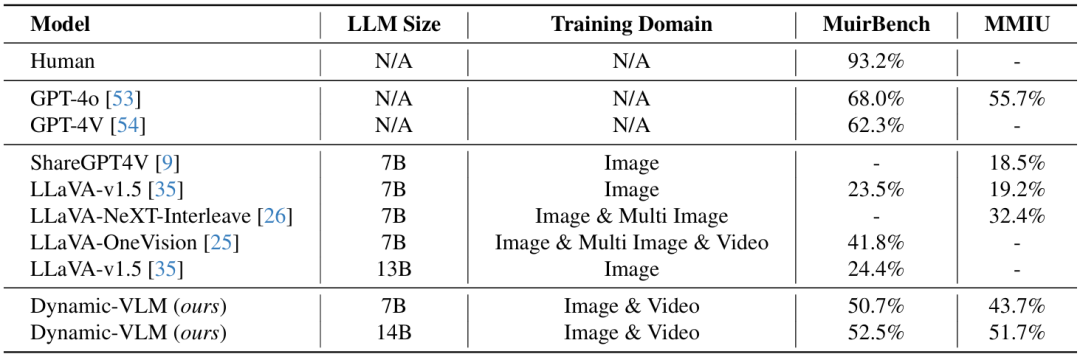
表4. 多项选择式多图像问答的结果。所有基准测试均完全超出了Dynamic-VLM的训练数据领域。尽管如此,Dynamic-VLM在这些任务上仍展现出优异的零样本性能,甚至超过了那些经过多图像数据训练的模型。
在ActivityNet-QA(长视频问答)中,7B参数的Dynamic-VLM以63.9%的准确率远超同类模型,甚至超过部分70B+大模型; 在VideoMME测试中,14B版本以64.6%的成绩超越LLaVA-OneVision(72B)2.7个百分点,这相当于中学生打败了博士生; 最意外的是跨图任务MuirBench:没经过专门训练,却比专门训练过的LLaVA-OneVision高出8.9%,甚至接近GPT-4o的水平。
更难得的是,这些成绩不是"刷出来"的——团队特别强调,所有测试都使用相同的GPT API版本评估,避免了因评测工具不同导致的"数据膨胀"。
动态压缩器:哪种设计最香?
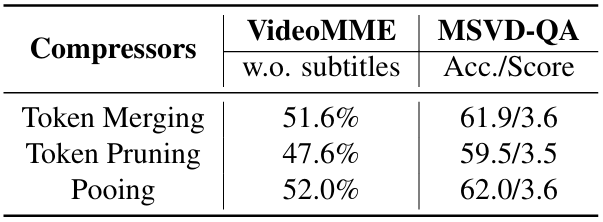
表5. 对动态压缩器架构的消融研究表明,在所考察的三种架构中,自适应池化(Adaptive Pooling)的性能最佳。

表6. 关于每帧Token数量的消融研究表明,无论最大视觉Token数量如何设置,当每帧Token数量设定为64左右或100左右时,Dynamic-VLM均能达到最佳性能。
消融实验揭开了动态压缩技术的"最优解":
三种压缩器PK:对比动态池化、Token合并、Token修剪三种方案后发现,动态空间池化表现最佳——在VideoMME中准确率比Token合并高3.3%,比Token修剪高9%。原因是它既能保留关键空间信息,又不会过度丢失细节。 每帧Token数的秘密:实验发现存在"黄金区间"——每帧用64-100个Token时,模型性能最好。太少则细节丢失(如看不清字幕),太多则冗余信息干扰判断(如长视频中重复帧的无效Token)。 帧数不是越多越好:当采样帧数超过120帧后,再增加帧数对性能提升微乎其微。这说明:盲目堆帧数不如优化单帧质量,动态压缩的"精准取舍"比"全盘接收"更高效。
一个值得思考的发现:视频训练能提升跨图能力
最意外的结论藏在跨图问答测试中:只训练过视频数据的Dynamic-VLM,在处理多幅独立图片时,竟然比专门训练过跨图任务的模型更强。这说明:视频中"帧与帧的关联学习",能意外提升模型对"图与图的关联理解"——这为多模态模型的通用训练提供了全新思路。
总结
这项工作提出了一个高质量的合成视频-文本数据集,并引入了一种能够适应不同视频长度的动态视觉Token压缩器。该数据集解决了高质量视频指令微调数据短缺的问题,为开放研究社区提供了支持。大量实验表明,Dynamic-VLM不仅在开放式视频问答和多选视频问答任务中表现出色,在多图像问答任务中也有优异表现。这些贡献促进了视频数据的更有效处理,缩小了开源模型与行业级模型之间的差距,同时为该领域未来的研究建立了新的基准。此外,研究结果表明,仅通过视频数据训练就能够提升大型视觉语言模型在多图像任务上的性能,这可能会启发未来的研究,以开发更稳健的训练策略,从而构建在各种任务上具有泛化能力的大型视觉语言模型。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!