

在数字化浪潮中,光学字符识别(OCR)技术早已超越了简单的“看图识字”,演变为对复杂文档(如学术论文、财务报表、法律文书)进行结构化解析的核心工具。现代OCR系统需要从一张图片中,精准地提取出文本、表格、公式、版面布局乃至阅读顺序,并将其还原为机器可读、可处理的格式。
近年来,基于视觉-语言大模型(VLM)的端到端方法已成为主流,它们通常采用“视觉编码器+自回归语言解码器”的架构(如MinerU2.5和),将图像编码后,像人类阅读一样从左到右、逐词逐句地生成文本序列。
尽管这种自回归范式取得了显著成功,但其内在的“顺序生成”特性,正成为制约文档OCR迈向更高效率与更强鲁棒性的关键瓶颈。想象一下,解析一份长达数十页、包含复杂表格和数学公式的报告,自回归模型必须严格地一个接一个地预测token,这不仅导致推理速度与输出长度线性相关,带来难以忍受的延迟,更严重的是,一旦在生成长序列的早期出现错误,这个错误会像多米诺骨牌一样向后传递和放大。此外,这种从左到右的生成模式,无形中让模型过度依赖其从海量文本中学到的“语言先验”和“常识”来“猜测”后续内容,而非纯粹基于图像视觉证据。当文档内容语义混乱(如经过随机打乱)或视觉质量不佳时,模型的性能便会急剧下降。
那么,文档内容的生成,其本质真的必须是严格从左到右的吗?
近日,上海人工智能实验室与北京大学的研究团队对此提出了根本性质疑,并在论文《MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding》中给出了颠覆性的答案。他们指出,自回归的顺序生成只是将二维文档结构序列化的一种“人为约定”,而非文档内容本身的内在属性。文档OCR更应该被看作一个“逆渲染”问题:给定一个渲染好的文档图像(结果),去反推其背后的结构化文本序列(源头)。这个过程天然是全局的、并行的。
基于这一深刻洞见,团队提出了 MinerU-Diffusion——一个统一的、基于扩散模型的文档OCR解析框架。它毅然抛弃了传统的自回归解码,转而采用在视觉条件控制下的并行扩散去噪过程。这一转变带来了革命性的优势:在保持甚至提升识别精度的同时,实现了高达3.2倍的解码加速,并显著降低了对语言先验的依赖,增强了模型的纯视觉OCR能力。
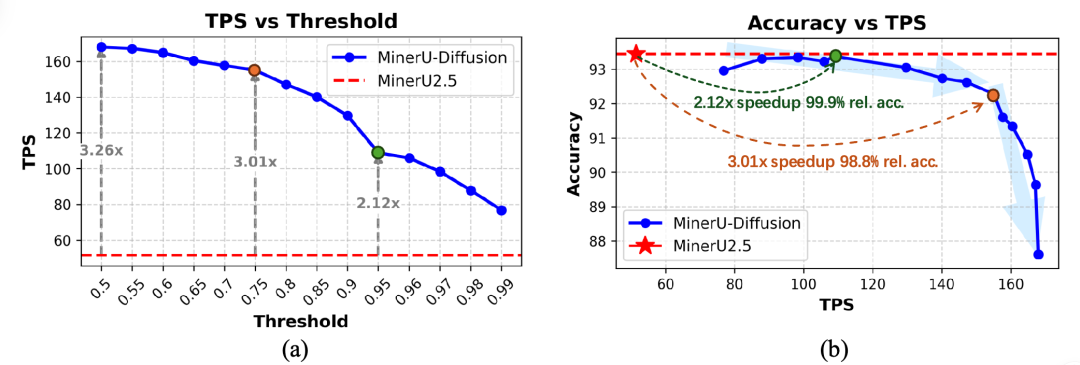
图1:MinerU-Diffusion的解码效率对比。(a) 通过置信度阈值控制解码并行度,相比MinerU2.5实现最高3.26倍加速。(b) 在精度-效率权衡曲线上表现优异。
论文链接:https://arxiv.org/pdf/2603.22458 代码仓库:https://github.com/opendatalab/MinerU-Diffusion 模型下载:https://huggingface.co/opendatalab/MinerU-Diffusion-V1-0320-2.5B PaperScope 解读:https://www.paperscope.ai/hf/2603.22458
自回归之殇:效率与鲁棒性的双重瓶颈
当前主流的文档OCR VLM模型,如MinerU2.5、PaddleOCR-VL等,其核心解码过程与ChatGPT生成对话并无二致:基于之前已生成的所有token,来预测下一个token。这种模式在创作开放性文本时是合理的,但对于文档OCR这一任务,却存在天然的错配。
首先,效率瓶颈显而易见。解析一个包含数千token的长文档,模型需要进行数千次顺序前向计算,无法利用现代硬件的并行计算能力,导致耗时随文档长度线性增长,难以满足实际应用中对实时性或高吞吐量的需求。
其次,也是更本质的问题,在于任务形式的错配。高质量的OCR本应极度依赖图像中的视觉证据来进行字符级识别。然而,自回归范式在无形中将OCR任务“包装”成了一个语言模型条件下的文本续写任务。模型在解码时,强大的语言模型先验会不自觉地“脑补”内容。当图像模糊、排版奇特或内容本身不符合常规语义时(例如,一份被随机打乱单词顺序的文档),模型更容易“相信”自己基于语言知识的猜测,而非真实的图像信号,从而导致幻觉错误和错误的累积传播。
论文中提出的“语义打乱”基准测试证实,当语义结构被破坏时,自回归OCR系统的性能会大幅下降,这暴露了其脆弱性根植于自回归解码固有的因果分解方式,而非仅仅是数据或训练策略的问题。
逆渲染新视角:用扩散模型重塑OCR
上海AI实验室与北大的团队重新审视了OCR的任务本质。他们将一个文档视为一个由文本、布局标记、表格分隔符、数学运算符等组成的统一结构化token序列。这个序列虽然以一维形式表示,但其背后对应的是二维的文档空间结构。token之间的依赖关系主要源于空间排列、版式规则和格式约束,而非一个内在的、不可违背的因果生成顺序。
因此,他们将文档OCR重新定义为 “视觉条件下的逆渲染” 。这是一个贝叶斯推理问题:在给定文档图像(作为部分且可能含有噪声的证据)的条件下,推断最有可能的潜在结构化token序列。自回归解码只是对这个后验分布的一种参数化方式(强加了一个固定的因果顺序),而扩散模型提供了另一种更自然、更结构契合的近似方法。
扩散语言模型(如Masked Diffusion)的工作方式截然不同:它从一个完全被[MASK]标记覆盖的序列开始,通过多轮迭代,逐步根据视觉条件和已预测的部分内容,并行地更新所有被掩码的位置,最终还原出完整序列。这与“逆渲染”的思想完美契合——从一团混沌(全掩码)开始,在视觉蓝图的指引下,逐步、并行地恢复出整个结构。

图2:扩散解码过程示意图。模型在视觉条件指导下,并行地、迭代地重构结构化文本。黑色为已确认token,红色为正在更新,黄色仍被掩码。这与自回归从左到右的解码形成鲜明对比。
更重要的是,对于OCR任务,图像内容与文本之间通常存在近乎确定性的映射关系,语义歧义有限。这使得扩散模型所依赖的“条件独立性”假设(给定输入和部分已观察序列,每个token可以被独立预测)变得非常合理,从而为安全、高效的并行解码奠定了理论基础。
MinerU-Diffusion的核心创新:块注意力与课程学习
然而,直接将标准的全注意力扩散模型应用于长文档OCR会面临计算复杂度过高、长程位置不稳定等问题。为此,研究团队设计了精妙的MinerU-Diffusion架构。
1. 块注意力扩散解码器:兼顾并行与稳定
MinerU-Diffusion没有采用计算成本高昂的全注意力机制,而是引入了块注意力。它将整个输出序列划分为连续的块。在块与块之间,它保留了一种粗粒度的自回归结构(即前一个块作为后一个块的条件),这为解码过程提供了结构锚点,防止了长序列对齐漂移。而在每个块内部,则进行完全并行的扩散去噪。这种“块间自回归,块内扩散”的混合因子化设计,在保持并行效率优势的同时,确保了生成的稳定性和结构性。
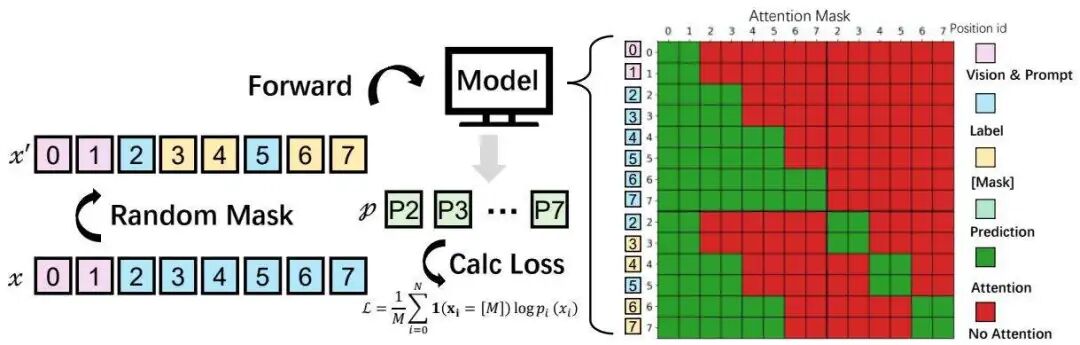
图3:MinerU-Diffusion的训练示意图。左:目标序列被随机掩码,模型仅预测掩码位置。右:结构化块注意力掩码,允许块内双向注意力,块间因果注意力。
2. 不确定性驱动的两阶段课程学习
扩散模型的“任意顺序”建模特性使其训练比自回归模型更不稳定,对数据噪声更敏感。为此,团队提出了一套两阶段课程学习框架。
第一阶段:多样性驱动的基础学习。在大规模、多样化的基础数据集上进行训练,旨在建立稳健的跨领域泛化能力和视觉-语义对齐。 第二阶段:不确定性驱动的边界细化。在模型收敛后,通过多次随机推理,筛选出那些模型预测不一致、不确定性高的“困难样本”。这些样本往往包含拥挤的版面、模糊的边界或复杂的结构。随后,通过AI辅助人工流程对这些硬样本进行高精度标注,并以此为核心,结合一部分基础数据,对模型进行精细化微调。这个阶段显著提升了模型在挑战性案例上的边界精度和鲁棒性。
实验验证:更快、更准、更鲁棒
研究团队在多个权威基准上对MinerU-Diffusion进行了全面评估,包括OmniDocBench(全文档解析)、CC-OCR/OCRBench(表格识别)和UniMER-Test(公式识别)。
在OmniDocBench上,MinerU-Diffusion在完全自动(无真实布局先验)的设置下取得了极具竞争力的总体分数。当提供真实布局信息时,其性能与当前顶尖的自回归模型(如MinerU2.5、PaddleOCR-VL)并驾齐驱,证明了其强大的内容识别能力。

如下图所示,通过动态置信度阈值调节解码并行度,MinerU-Diffusion在保持93%以上精度的同时,实现了2.1倍的解码加速;在精度超过90%时,更可达到最高3.2倍的加速。这彻底改变了长文档OCR解析的速度格局。

在团队提出的“语义打乱”基准测试中,随着文档语义被破坏的程度加深,自回归模型的性能直线下降,而MinerU-Diffusion的性能则保持基本稳定(图4)。这强有力地证明了,MinerU-Diffusion减少了对语言先验的依赖,其识别能力更多地扎根于对视觉信号本身的忠实解读。
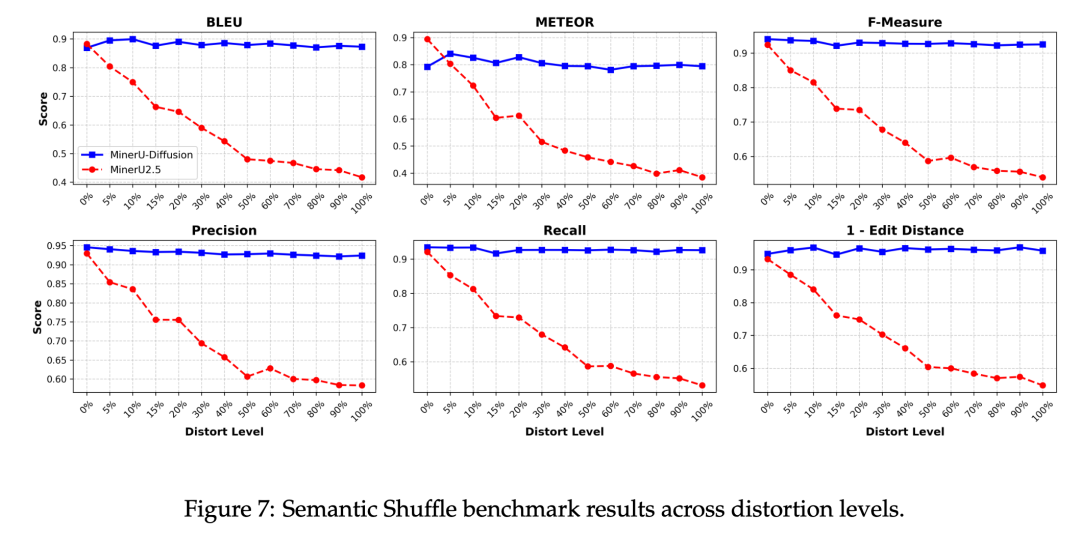
图4:语义打乱基准测试结果。随着语义失真程度增加,自回归解码器性能急剧下降,而扩散解码器保持稳定,显示出更强的视觉识别能力。
未来展望与开源贡献
MinerU-Diffusion的工作标志着文档OCR领域的一个重要范式转变。它挑战了“顺序生成是OCR唯一解”的固有观念,并通过严谨的论证和扎实的实验,展示了扩散并行解码在这一领域的巨大潜力——不仅是效率的提升,更是朝着更本质、更鲁棒的“视觉理解”迈出的关键一步。
这项工作由上海人工智能实验室和北京大学的研究者共同完成,相关代码和模型已在开源社区发布:
论文链接:https://arxiv.org/pdf/2603.22458 代码仓库:https://github.com/opendatalab/MinerU-Diffusion 模型下载:https://huggingface.co/opendatalab/MinerU-Diffusion-V1-0320-2.5B
随着扩散模型在语言和视觉领域的持续发展,我们有理由相信,像MinerU-Diffusion这样的创新框架,将推动文档智能处理技术进入一个更高效、更可靠的新时代,为数字化办公、档案管理、金融分析等众多下游应用注入强大动力。
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群










