相似度超越Seed-TTS、MiniMax-Speech等知名模型。
智东西4月2日报道,昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。
这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。
此外,美团LongCat团队还在LongCat-AudioDiT中做了两个关键改进,一方面识别并纠正了一个长期存在的“训练-推理不匹配”问题,另一方面用自适应投影引导(APG)取代了传统的无分类器引导(CFG),从而大幅提升了最终的语音生成质量。
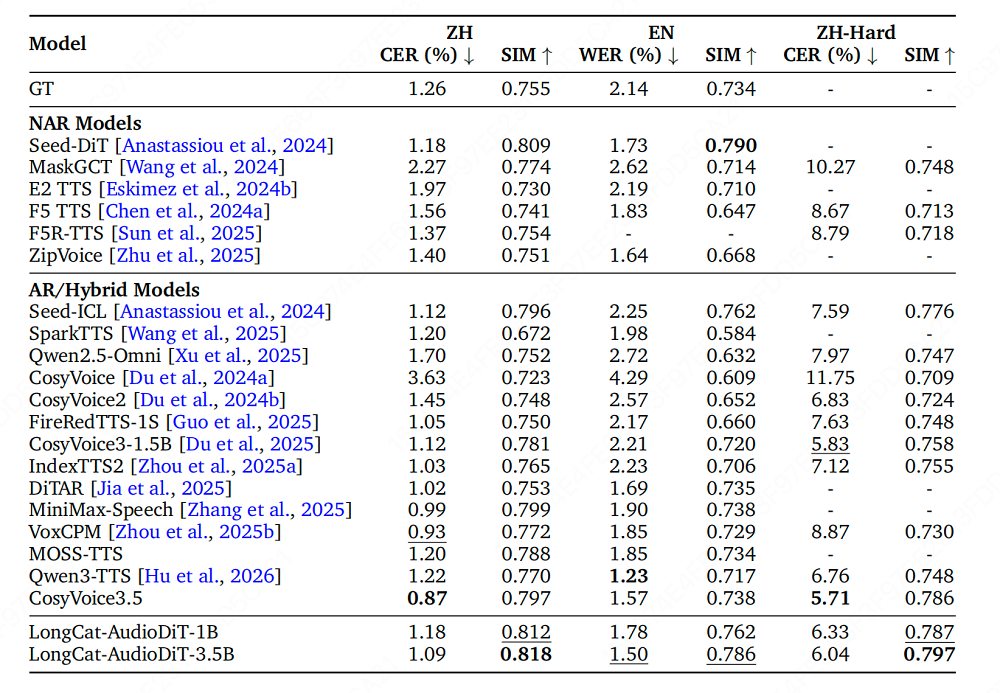
结果表明,LongCat-AudioDiT在Seed基准测试中取得SOTA的零样本语音克隆性能。LongCat-AudioDiT-3.5B模型在Seed-ZH测试集的说话人相似度(SIM)指标提升至0.818,Seed-Hard测试集达到0.797,超过了Seed-TTS、CosyVoice3.5、MiniMax-Speech等知名模型。
值得一提的是,LongCat-AudioDiT并没有使用高质量人工标注数据和多阶段的训练,仅仅通过ASR转写的预训练数据和单阶段预训练就取得了目前的效果。
美团还用多个案例分享了LongCat-AudioDiT的生成效果,以下是6个中文、英文TTS案例的合集:
https://arxiv.org/abs/2603.29339v1
https://github.com/meituan-longcat/LongCat-AudioDiT
https://huggingface.co/meituan-longcat/LongCat-AudioDiT
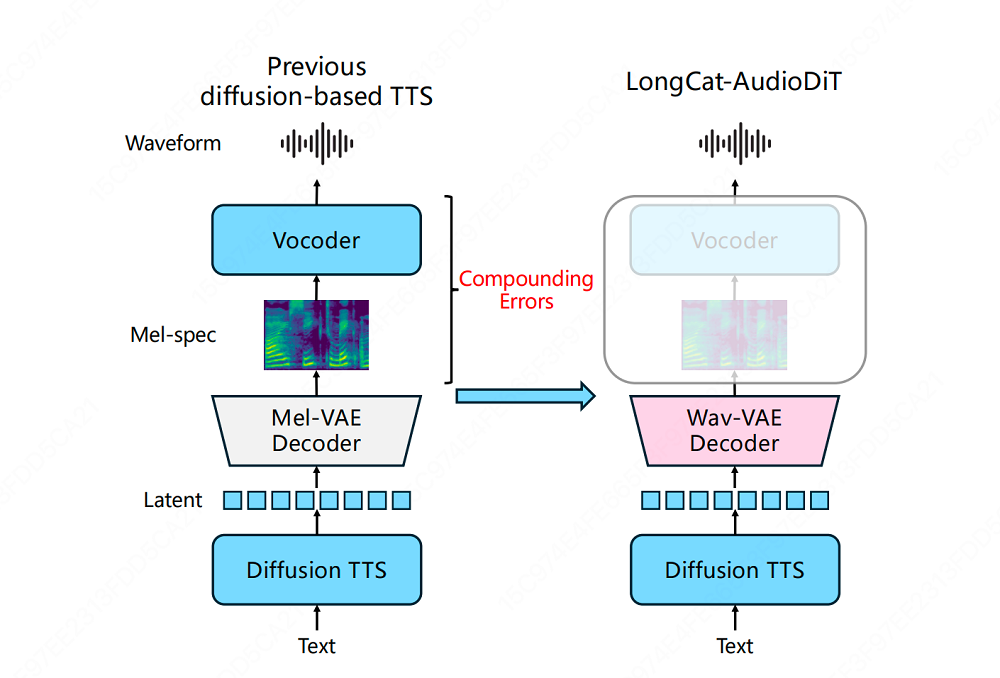
业界传统的文本转语音系统长期面临一个根本性问题:阶段过多。这类系统通常先预测梅尔频谱等中间声学特征,再借助独立的神经声码器将其转换为最终波形。
这种“先预测、后翻译”的架构,本质上是在两个不同的表示空间之间反复传递信息,每一次转换都会引入误差,累积下来,最终合成出的音频往往损失了高保真度与个性化细节。而这些,恰恰是实现零样本语音克隆所最需要保留的关键信息。
针对这一痛点,美团LongCat团队提出了全新LongCat-AudioDiT架构。其设计理念是通过一个波形变分自编码器(Wav-VAE)与一个扩散Transformer(DiT)模块,在波形潜空间内完成声音的压缩、建模与重建全流程。
这一新架构不再拆分为多个阶段,也不再依赖独立的声码器,所有操作统一在同一表示空间中进行,缓解了误差累积的问题。
这个系统的核心,是从头构建一个干净、可控的波形潜空间。为此,美团LongCat团队设计了一个叫做Wav-VAE的全卷积音频自编码器,负责把原始波形压缩成紧凑的连续潜向量。
它的编码器通过多级Oobleck块逐层下采样,每一块里都堆叠了带空洞卷积的残差单元,能同时捕捉局部和全局的时序依赖,最终把24kHz的波形压缩到帧率只有大约11.7Hz,压缩比超过了2000倍。
为了在激进的下采样中还能稳定训练,每个编码器或解码器块里都加了一条非参数的“空间到通道”或“通道到空间”的捷径分支,相当于给梯度留了一条直通的线性通道,大幅提升了收敛的稳定性。
而在训练目标上,Wav-VAE而是融合了多分辨率STFT损失、多尺度梅尔损失、时域L1损失、KL散度,再加上多尺度STFT判别器的对抗损失和特征匹配损失,这一套组合拳下来,既保证了重建波形的时频结构准确,又让听感足够自然。
有了这样一个高质量的潜空间,接下来的任务就是在里面做生成。美团LongCat团队使用的生成模型是扩散Transformer(DiT),文本编码用的是UMT5。
研究中,团队发现只取最后一层隐状态生成效果不好,于是把第一层词嵌入和最后一层合并、再经过LayerNorm,提升了生成结果的可懂度。并通过轻量的ConvNeXt V2系列模块来细化文本表征,让对齐收敛更快。
DiT的骨干也做了几处优化,包括用全局自适应层归一化来注入时间步信息,用QK-Norm加RoPE稳定注意力,还用长跳跃连接直接把输入加到输出上,对质量有稳定提升。最后用REPA,借助mHuBERT的特征引导中间层,加速了收敛。
如果说波形潜空间解决的是“在哪个空间里建模”的问题,那美团LongCat团队在推理阶段做的两处改进,则是要优化“生成路径”和“质量纯度”。
他们首先发现了一个在流匹配TTS里长期存在但未被关注的问题:训练和推理的不匹配。在标准CFM训练里,模型只在掩码区域算损失,而作为条件的音频提示区域是不参与优化的。
但到了推理阶段,这些提示区域却会随着扩散的常微分方程自由演化,导致它们的分布轨迹偏离了训练时的约束,最终结果就是说话人音色漂移、稳定性下降。
他们为此提了一个双重约束机制。一是在每一步推理迭代里,强制把提示区域的潜变量强制重置成理论真值,让提示区域的演化轨迹和训练时完全对齐,从而给生成部分提供一个干净、稳定的声学条件。
二是在计算无条件速度场的时候,直接把提示区域的潜变量移除,算出真正意义上的无条件速度,避免信息泄漏。
另一个改进是针对无分类器引导(CFG)的。传统扩散模型普遍用CFG来放大条件预测和无条件预测的差异,从而提升生成质量,但副作用是引导强度越大,频谱就越容易“过饱和”,音质变差,听感也不自然。
美团LongCat团队提出的自适应投影引导(APG)换了个思路。引导信号里真正有益的部分和导致劣化的部分,在几何上是正交的。APG把引导信号分解成平行和正交两个分量,只保留正交的那部分(有益部分),同时抑制平行分量(劣化部分),这样既提升了自然度,又避免了音质损失。
这两项推理优化加在一起,让生成语音在保持高说话人相似度的同时,自然度和声学质量都明显更好。
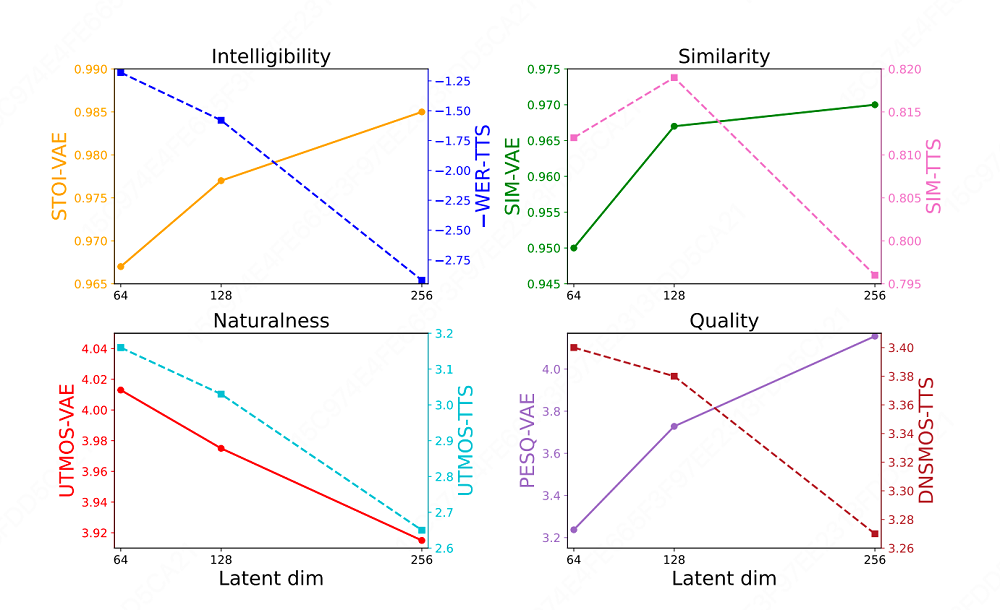
在Wav-VAE的实验阶段,美团LongCat团队还观察到一个有意思的现象:VAE的重建质量并不是越高越好。单纯追求高重建分数,会让潜空间的维度膨胀,反而让下游的扩散模型学不动,整体表现反而下降。
为了解决问题,美团LongCat团队对比了不同潜空间维度和帧率配置下的建模表现,确定了64维潜在维度加上11.7Hz的帧率最优配置。这个配置既给生成模型留出了足够的学习空间,又保留了必要的声学细节,在重建保真度和生成质量之间找到了一个平衡点。
LongCat-AudioDiT以纯粹的波形潜空间建模,证明了绕开中间表征的扩散TTS路线的可行性。美团LongCat团队认为,这套“波形潜空间直通”的设计范式将为高保真语音合成与多模态音频生成提供新的思路。
在论文中,美团LongCat团队称,他们判断未来有前景的研究方向包括通过无需对齐的强化学习(音频领域的 RLHF)来进一步提升性能上限,以及通过知识蒸馏技术加速推理速度,以实现实时部署。