点击下方卡片,关注“具身智能之心”公众号
化工厂控制室里,一面墙上挂着几十个压力表。老工程师扫一眼,就知道哪条管路可能有问题。
让机器人干同样的活?Google DeepMind之前试过,最好的模型成功率23%——四次读数里错三次。
2026年4月14日,Google DeepMind发了一篇博客,宣布Gemini Robotics-ER 1.6能以93%的成功率读取工业压力表。
13个月前,同一个团队发布第一代ER模型时,机器人零样本控制的平均成功率只有27%。连桌上的工具都数不准。
如今ER1.6发布,三个版本,三次跳跃。
一切的起点:Gemini能不能理解物理世界?
2025年3月,Google DeepMind发布了第一代Gemini Robotics家族,包含两个模型:Gemini Robotics(VLA,直接输出机器人动作)和Gemini Robotics-ER(具身推理模型,只做感知和推理)。
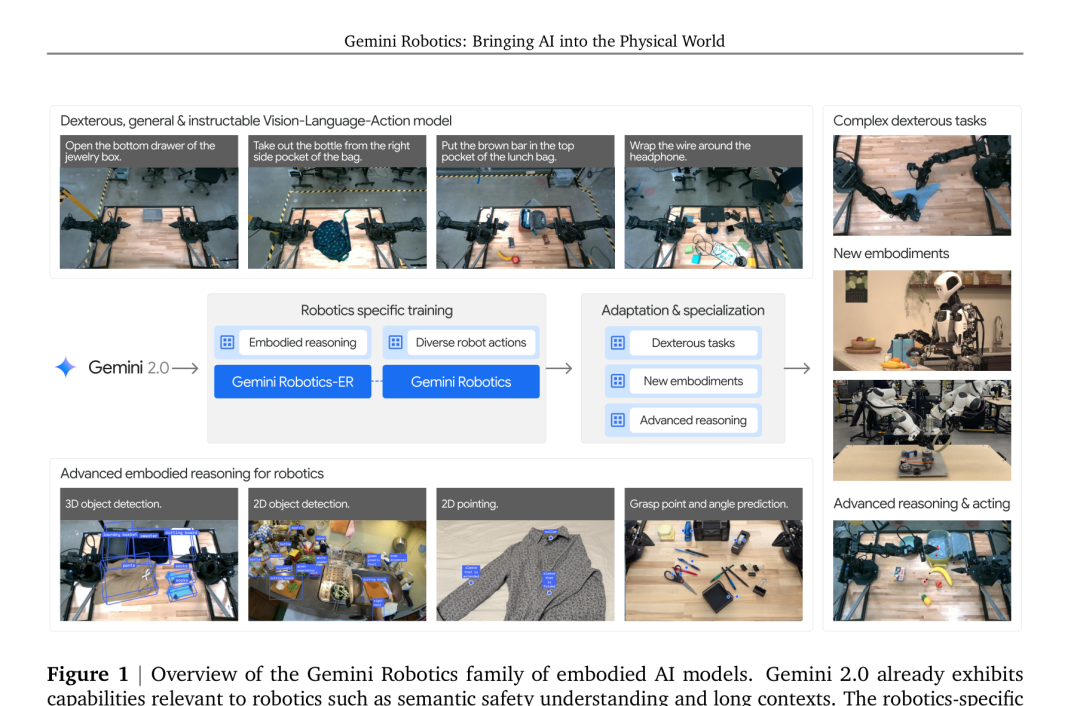
这两个模型都基于Gemini 2.0构建,经过了robotics-specific的训练增强。但它们之间的关系相对松散——ER管看,VLA管动,各做各的。
团队同时发布了一个叫ERQA的基准测试,400道视觉问答题,专门考VLM的具身推理能力:空间推理、轨迹预测、动作推理、状态估计、多视角理解。
这是行业里第一次有人系统性地量化VLM到底能不能理解物理世界。
第一代ER的底层能力:能看懂,但还不够精
在ERQA上,Gemini 2.0 Pro Experimental跑出了48.3%的准确率,加上Chain-of-Thought提示后提升到54.8%,两个数字都是当时的最优。GPT-4o在同一基准上只有50.5%(CoT),Claude 3.5 Sonnet为45.8%。
Pointing能力是ER的另一个亮点。在Paco-LVIS(物体部件指向)上达到71.3%,Pixmo-Point(开放词汇指向)上达到49.5%,都超过了GPT和Claude系列。
3D感知同样给了惊喜。在SUN-RGBD 3D物体检测基准上,ER拿到了48.3 AP@15,超过了专门的3D检测专家模型ImVoxelNet(43.7)。
一个通用VLM,在3D检测上打赢了专用模型。这件事本身就说明,Gemini 2.0的视觉-空间理解能力确实有料。
看懂是一回事,能不能指挥机器人干活是另一回事。
团队用ER生成代码来零样本控制ALOHA 2机械臂。ER的平均成功率53%,Gemini 2.0 Flash只有27%。换成ICL(给几个示范样例)模式后,ER提升到65%。

数字在上升,但绝对值不算高。更关键的问题是:对于需要精细操作的任务——叠衣服、折纸——成功率是0%。
ER和VLA是两个独立模型。ER看完场景生成一段代码,代码再驱动VLA执行。中间的信息损耗很大,ER的推理结果到了VLA那边,很多语义细节丢失了。
第一代证明了Gemini具备具身推理的潜力,但也暴露了一个结构性问题:感知和行动之间缺少一条打通的思考链路。
第二代ER 1.5:三个架构级的跳跃
2025年10月,Google DeepMind发布了Gemini Robotics 1.5家族,核心贡献集中在三个架构级别的变化上。
跳跃一:Embodied Thinking——让模型想了再做
第一代的问题是ER和VLA各想各的。第二代的解法是:让两个模型都学会thinking。
ER 1.5在推理时会生成自然语言的thinking trace——先分析场景中的关键特征,再逻辑推导,最后给出判断。这和数学领域的Chain-of-Thought类似,但落到了物理世界的视觉-空间推理上。
更重要的是,VLA 1.5也获得了thinking能力。执行动作之前,模型会先在内部生成一段思考过程:下一步该做什么、手臂该怎么移动、预期的运动轨迹是什么。然后才输出实际的机器人动作。
论文把这个叫做Thinking VLA。
在多步任务基准上,开启thinking的VLA比不开thinking的版本,进度分数从0.29提升到0.36(ALOHA)、从0.55提升到0.60(Franka)。意义在于:这是第一次在VLA模型里实现了「想了再做」的机制。

thinking还带来了一个副产品:可解释性。机器人的内部思考过程是自然语言,人类可以直接读,知道它在想什么、打算做什么。出了问题能查思考日志。
跳跃二:Motion Transfer——让不同机器人的经验互通
第一代的VLA只能用单一机器人的数据训练。ALOHA的数据只能给ALOHA用,Franka的数据只能给Franka用。
ER 1.5引入了Motion Transfer(MT)机制——一套新的模型架构和训练方法,让VLA能同时从ALOHA双臂机械臂、Franka单臂机械臂、Apollo人形机器人三种完全不同形态的机器人数据中学习。
关键结果:ALOHA机器人成功执行了只在Franka上采集过训练数据的任务,反过来也一样。
更硬的数据来自消融实验。单机器人数据训练 vs 多机器人数据+MT训练,在ALOHA的Task Generalization上从0.41提升到0.70,在Franka上从0.02提升到0.50。Franka的提升尤其夸张,几乎从零起步。
这意味着机器人行业长期面临的数据稀缺问题有了一条新的突破口:不同机器人采集的数据可以互相借力。
跳跃三:Agentic System——ER成为总指挥
第一代里ER和VLA各干各的。第二代把它们组装成了一套完整的Agent系统。
ER 1.5担任Orchestrator(调度器),负责理解用户指令、把复杂任务拆成子步骤、调用外部工具(搜索引擎、代码执行、自定义函数)、判断每个子任务是否完成。VLA 1.5担任Action Model(执行器),负责把自然语言指令翻译成机器人动作。
这套架构的威力在长程任务上体现得最清楚。
团队设计了8个需要工具使用、记忆、规划和灵巧操作的长程任务。用ER 1.5做Orchestrator时,系统总失败率22%。换成Gemini 2.5 Flash做Orchestrator,总失败率44.5%——几乎翻倍。
差距最大的地方是规划能力。ER 1.5的规划失败率9%,Flash的规划失败率25.5%。
这组数据说明了一件事:通用大模型的推理能力和针对物理世界优化的具身推理能力之间,差距仍然很大。
团队在15个学术基准上同时评估了具身推理能力和通用能力(图像理解、科学推理、编程等),画出了一张Pareto前沿图。
ER 1.5在这张图上占据了右上角——同时在具身推理和通用能力两个维度上达到最优。开启Thinking后,具身推理分数从约53跳到约60,同时通用能力不降反升。
作为对比,Gemini 2.5 Pro虽然通用能力更强,但具身推理分数明显落后。GPT-5的具身推理分数更低。
这张图的含义是,具身推理不是通用能力的子集。一个模型在MMMU和编程上跑分很高,不代表它理解物理世界。反过来,专门优化具身推理也不必然牺牲通用能力。

第三代ER 1.6:让具身模型的推理能力赋能真实场景
2026年4月,ER 1.6以一篇博客的形式发布,不再是学术论文。只有2位作者署名,模型直接上API供开发者调用。
发布形态本身就是信号——技术从研究阶段进入产品阶段。
看一眼不够,那就多看几眼
ER 1.6的核心架构升级是Agentic Vision:把视觉推理和代码执行融合成一条多步推理链。
以仪表读数为例,传统模型看一眼图片就输出答案。Agentic Vision的做法是:第一步放大仪表关键区域,第二步用Pointing锁定指针位置,第三步根据刻度间距做比例估算,第四步调用代码执行精确计算,第五步结合世界知识解读读数含义。
五步下来,仪表读数成功率从ER 1.5的23%提升了93%。
拆开看这个数字:ER 1.6基础模型本身贡献了86%,Agentic Vision额外提升了7个百分点。从86%到93%,失误率减半。


仪表读数的突破它依赖一个更底层的能力——Pointing,精确指向。
Google DeepMind把Pointing定义为空间推理的基座能力(foundation of spatial reasoning)。
在一个工具识别的演示里,模型准确数出了2把锤子、1把剪刀、1把画笔、6把钳子,以及若干园艺工具。
同时,它没有报告现场并不存在的独轮车或Ryobi电钻。在视觉语言模型领域,能说对的同时不说错,这件事本身就不容易。
精确指向支撑的不只是计数。关系逻辑比较、运动推理与轨迹映射、物理约束合规推理,都建立在Pointing的基础上。
判断"做没做完"这件事,比想象中难
任务完成检测(Success Detection)被Google DeepMind称为自主性的引擎(engine of autonomy)。
考虑一个任务:把蓝色笔放进黑色笔筒。
从头顶视角看,笔可能已经出现在笔筒正上方。但只有切到侧面视角,才能确认笔是否真正插入了笔筒。
这要求模型同时处理多个摄像头画面——头顶摄像头和机械臂手腕摄像头,在遮挡和弱光条件下做出准确判断。
多视角成功检测的准确率从74%提升到了84%。单视角成功检测从82%提升到90%。

安全和能力一起迭代
第一代在论文的第5节讨论了安全原则,发布了ASIMOV基准的初版,是安全原则的起步。
第二代ASIMOV-2.0升级为包含真实伤害事故报告的评估套件,覆盖文本、图像、视频三种模态。ER 1.5在风险识别(text)上从初代的76%提升到90%,干预预测(video)从62%提升到84.1%。
而第三代,在ASIMOV对抗性空间推理基准测试中,Gemini Robotics-ER 1.6的文本准确率、点位准确率、边界框准确率全面超越前代。
受伤风险感知能力的大幅度提升。相比Gemini 3.0 Flash,文本模态下提升了6%,视频模态下提升了10%。

这意味着模型在处理涉及人员安全的场景时——比如识别工人靠近高温管道的风险——给出的判断更可靠。
Boston Dynamics已经准备好了
Boston Dynamics副总裁Marco da Silva说:「仪表读数和更可靠的任务推理等能力,将使Spot能够完全自主地看到、理解并应对现实世界的挑战。」
Spot四足机器人已经在能源设施和建筑工地上跑了一段时间。但此前的巡检主要靠远程操控或预设路线。
93%的仪表读数准确率,给了自主巡检一个可操作的技术底线。
从三代模型看Google的野心
把三代ER的技术演化打开来看,这不只是数字上的跃迁。更根本的变化是,他们逐步回答了一个底层问题:通用大模型怎样变成能在物理世界干活的机器人大脑?
第一条线:推理范式的三级跳。
ER 1.0是单次前向推理,看一遍图片出一个答案,加CoT能提升一些,但是天花板有限。ER 1.5引入了Embodied Thinking,模型能在推理过程中生成多层自然语言思考,类似人类的「让我想想」。ER 1.6更进一步,Agentic Vision把推理拆成多个执行步骤,每一步都可以调用工具,执行代码,重新观察。
先证明大模型具备理解物理世界的潜力。再让模型学会在行动之前思考,并建立感知与行动之间的系统级协同。最后用多步推理+代码执行的方式,把实验室里的能力对接到真实工业场景上。
从「看一眼」到「想一想」到「分步看、分步算」——推理深度每一代都在提升。仪表读数从23%到93%的跃迁,本质上是推理范式升级带来的。
第二条线:ER和VLA从分离到融合。
第一代是两个独立模型,各管各的事。第二代用Agentic System架构把它们组成了一套调度器+执行器的系统。第三代在Agentic Vision中进一步模糊了感知和行动的边界——推理过程本身就包含了工具调用和代码执行。
这个趋势指向的终局是:ER和VLA最终可能融合成一个统一的模型,既能深度推理又能直接输出动作。
第三条线:从学术验证到工业落地。
第一代是发布ERQA基准,做基础研究。第二代是推系统架构和多本体迁移。第三代是则是发布API,对接Boston Dynamics。
Google并不想做一个全栈公司,它想用模型能力赋能真实落地。

推荐阅读 :










