Disco-RAG团队 投稿
量子位 | 公众号 QbitAI
RAG(检索增强生成)已经成为大模型落地的标配技术。但用过的人都知道一个痛点:明明搜到了对的文档,模型给出的答案还是离谱。
这到底是怎么回事?
德国萨尔大学×腾讯优图×交大×复旦×浙大组成的研究团队给出了一个狠准的诊断:问题不在搜索,而在阅读理解。现有RAG把检索到的段落当“散装零件”直接投喂给模型,段落里的主次关系、段落间的逻辑脉络全部被抹平了。模型看到的不是一份有条理的参考资料,而是一锅“信息乱炖”。
为此,研究团队提出了Disco-RAG——一种在“搜”和“答”之间加入“读懂”环节的新型RAG框架。该工作已被ACL 2026主会录用为长文。在三个权威基准上取得多项最优,而且全程零训练。

先看一个例子:传统RAG是怎么“答错”的
用户问:“补充维生素D能预防流感吗?”系统搜回了两段文献:
段落A:“在冬季维生素D水平偏低的成年人群中,额外补充维生素D后流感发病率下降了12%。”
段落B:“大规模随机对照试验未发现维生素D补充与流感风险之间存在统计学上的显著关联。”
传统RAG把A和B一股脑拼在一起交给模型。模型一看“下降12%”,直接输出“维生素D有效”——完全没理会A前面那个至关重要的限定条件(“冬季+偏低人群”),更没看出A和B其实是在“打架”。

这背后是传统RAG的两个致命盲区:
段落内部看不到主次——哪句是结论、哪句是前提条件,模型完全分不清。
段落之间看不到关联——两段文献究竟是互相支持还是互相打脸,模型一无所知。
换句话说:RAG的短板不是“搜不到”,而是“搜到了读不懂”。
现有方法不是没试过
这个问题其实行业早就有感知。过去几年,研究者们提出了各种补救思路:重新排序检索结果,把最相关的段落排到前面;改写用户查询,让搜索更精准;压缩冗余段落,减少无关信息干扰;甚至让模型多轮迭代检索,逐步逼近答案。
这些方法确实有效,但它们优化的始终是“搜”这个环节——背后有一个隐含假设:只要把更好的内容送到模型面前,模型自然就能给出好答案。
然而现实是,很多时候内容已经“够好”了,问题出在模型拿到这些内容之后不知道怎么组织。当多个段落之间存在复杂的逻辑关系——比如一个给出了限定条件下的结论,另一个给出了相反的大规模实验结果。单纯把它们排个序或者压缩一下,并不能帮助模型理解这些段落之间到底是什么关系。
这正是Disco-RAG要攻克的核心问题:不是让模型看到更好的内容,而是让模型真正读懂已有的内容。
Disco-RAG怎么解?三步让模型学会“读”文档
思路很直接:在“搜”和“答”之间插入一个“读懂”环节,用语言学里经典的修辞结构理论(RST)解析文本逻辑,再让模型动笔。
全程三步,不改模型一个参数:
第一步:给每个段落画一棵“论证树”。利用LLM将段落拆解为最小语义单元(EDU),然后标记每个单元是“核心内容”还是“辅助说明”,同时识别单元之间的关系类型(如因果、对比、展开等)。这样一来,模型就能区分“12%的下降”和“仅限特定人群”哪个才是这段话的重心。
第二步:给所有段落织一张“关系网”。对检索回来的全部段落做两两配对分析,预测它们之间是支持、反驳、补充还是无关,最终形成一张有向图。上面那个例子中,系统会在A和B之间标注“对比”关系。
第三步:先列提纲,再写答案。综合用户的提问、原始段落、论证树和关系网,Disco-RAG先自动生成一份“写作提纲”。提纲里标明了要引用的关键证据、叙述的先后顺序、以及如何协调矛盾信息。最后,模型以提纲为指导,产出最终回答。

回到维生素D的例子
Disco-RAG处理前面那个“维生素D能不能预防流感”的问题,具体会发生什么?
首先,论证树会解析段落A的内部结构,把“冬季维生素D水平偏低的成年人群中”标记为限定条件(辅助单元),把“流感发病率下降了12%”标记为核心结论(核心单元)。这意味着模型不会再把一个有前提的局部结论当成普适事实。
接着,关系网会在段落A和段落B之间建立一条“对比”关系的边——明确告诉模型:这两段文献的立场存在冲突,不能简单取其中一个当答案。
最后,写作提纲会据此规划回答策略:先分别介绍两项研究的发现和各自的适用范围,再指出二者之间的矛盾,最后给出一个有条件的综合判断。
这样一来,模型的最终回答就不再是简单粗暴的“有效”或“无效”,而是一个有层次、有条件、有依据的分析。这恰恰是用户们对高质量回答的期待。
成绩单:三大基准全面领跑
团队在三个覆盖不同场景的权威基准上做了全面评测,使用多款开源模型,全部不做任何训练。
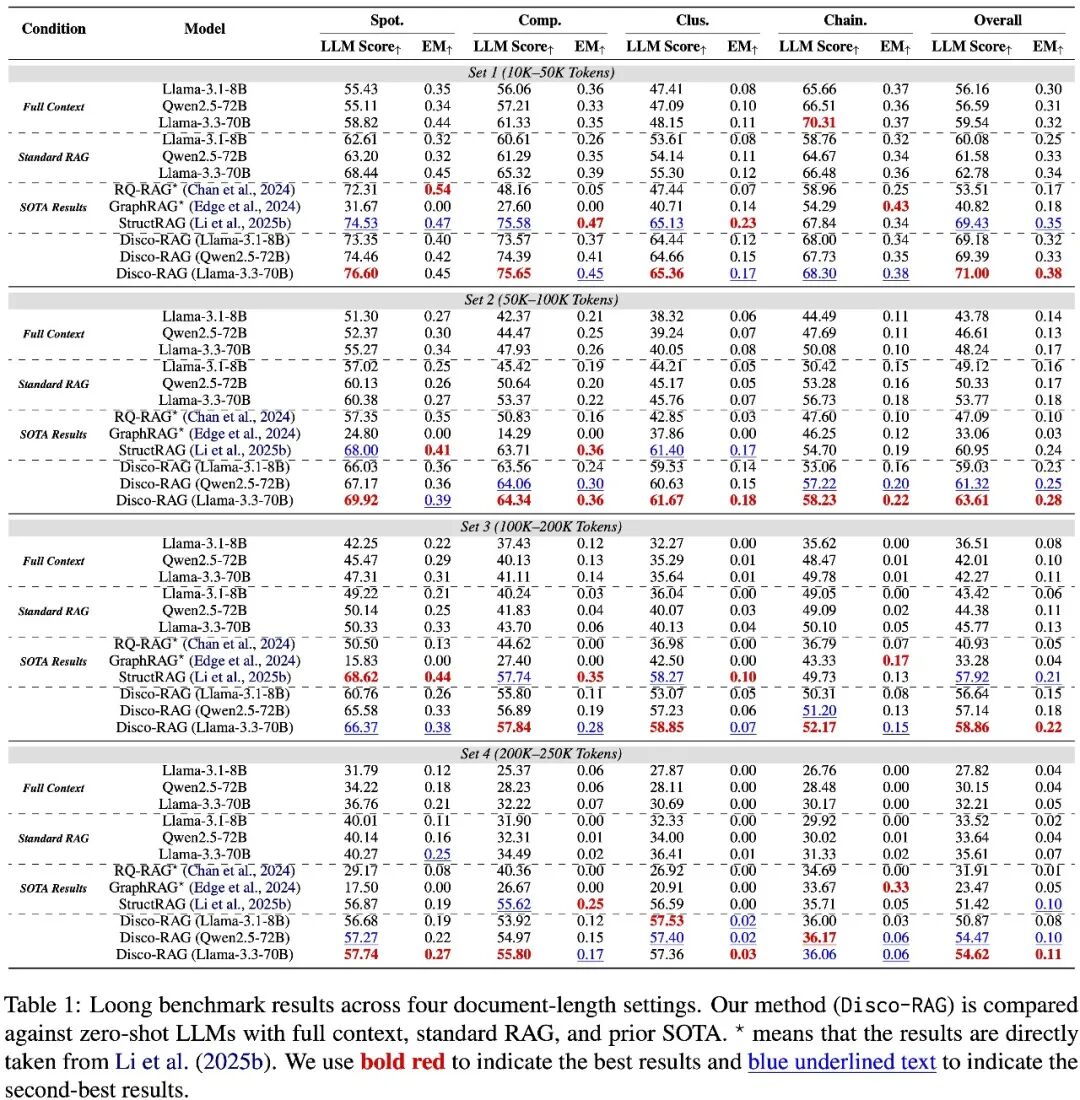
长文档推理(Loong)
这个基准测试模型在超长文档上的推理能力,文档长度从1万到25万tokens不等。核心发现:文档越长,Disco-RAG的优势越大。在最长的25万tokens档位,普通RAG几乎完全失效,而Disco-RAG依然能给出有效回答。更值得一提的是,Disco-RAG的整体表现甚至超过了需要专门训练的方法。
歧义问答(ASQA)
面对含义模糊的问题,Disco-RAG在核心指标上均刷新了最佳记录。更值得注意的是,即使只用参数量很小的模型,Disco-RAG也能达到此前各种专门设计的系统的水平。

科学摘要(SciNews)
把学术论文改写成通俗新闻摘要——这个任务很考验综合理解与表达能力。Disco-RAG在四项评测指标中拿下三项第一,事实一致性排名第二。

提升真的来自“读懂了结构”吗?
团队做了一系列对照实验来验证这一点:
三个模块各有分工,缺一不可。分别去掉论证树、关系网、提纲步骤后,性能都会出现明显下滑,说明三者各自承担了不同的角色。
光加规划没用,必须加结构。给普通RAG加一个通用规划步骤(不含篇章结构),提升很有限。而Disco-RAG的大幅提升主要来自“论证树+关系网”这套结构化表示。说明模型确实在利用文本的逻辑结构,而不是单纯因为输入变长了。
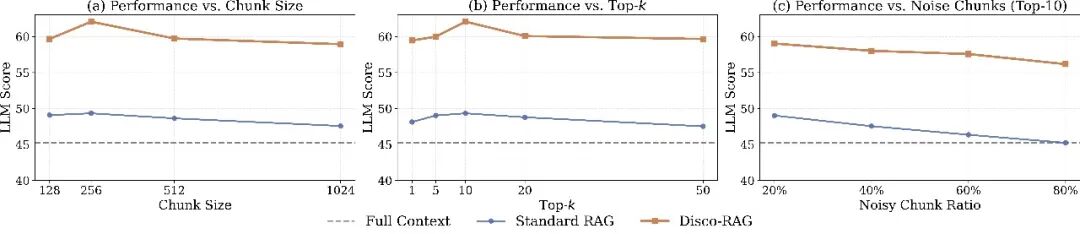
面对噪声和粒度变化,依然稳健。即使把大量检索结果替换成无关内容,或者大幅调整段落切分粒度,普通RAG波动剧烈,Disco-RAG始终保持稳定表现。

实际部署:小模型做分析,大模型做生成
Disco-RAG的三个模块(论证树、关系网、提纲)和最终的答案生成是解耦的,可以用不同大小的模型来分别承担。团队做了一组混合部署实验:用参数量较小的Llama-3.1-8B负责所有结构分析模块,只在最后的生成环节调用Llama-3.3-70B。

结果表明,用小模型做结构分析、大模型只负责最终生成,就能恢复绝大部分性能增益。甚至全部用8B小模型跑Disco-RAG,效果也远超用70B跑普通RAG。这意味着Disco-RAG的落地成本可以很灵活。结构分析模块可以“降配”部署,核心收益依然保留。
与训练结合:篇章结构和微调并不冲突
既然Disco-RAG不用训练就能提效,那如果叠加训练会怎样?团队在SciNews摘要任务上做了对比:

两个关键发现:第一,不训练的Disco-RAG已经超过了经过微调的普通RAG,这说明结构信息的价值不可小觑。第二,当微调与篇章结构结合使用时,效果进一步提升,说明两者带来的收益是互补的,而非重叠的。这为实际应用指出了一条清晰的路径:先用Disco-RAG免训练拿到即时收益,再根据需要叠加微调,还能进一步提升。
总结
Disco-RAG给出了一个清晰的思路:与其一味优化“搜”,不如先教模型学会“读”。
在检索和生成之间加入一层篇章结构解析。让模型看懂段落内部的主次关系、理清段落之间的逻辑脉络、再列好提纲动笔。不需要训练、不需要改模型,就能让RAG的回答质量大幅提升。尤其在长文档和噪声场景下,效果尤为明显。
从更大的视角来看,这项工作揭示了一个被长期忽视的事实:自然语言文本不是一堆句子的简单堆砌,它有自己的逻辑骨架——有主次、有因果、有转折、有呼应。当我们把这个骨架还给模型,模型对信息的理解和组织能力就会产生质的变化。
这个思路不仅适用于RAG场景,也可能为更广泛的多文档推理、长文本理解等任务提供新的启发。对于正在做RAG系统落地的团队来说,Disco-RAG提供了一个轻量、即插即用的增强方案,值得关注。
论文:
Disco-RAG: Discourse-Aware Retrieval-Augmented Generation
链接:
https://arxiv.org/abs/2601.04377