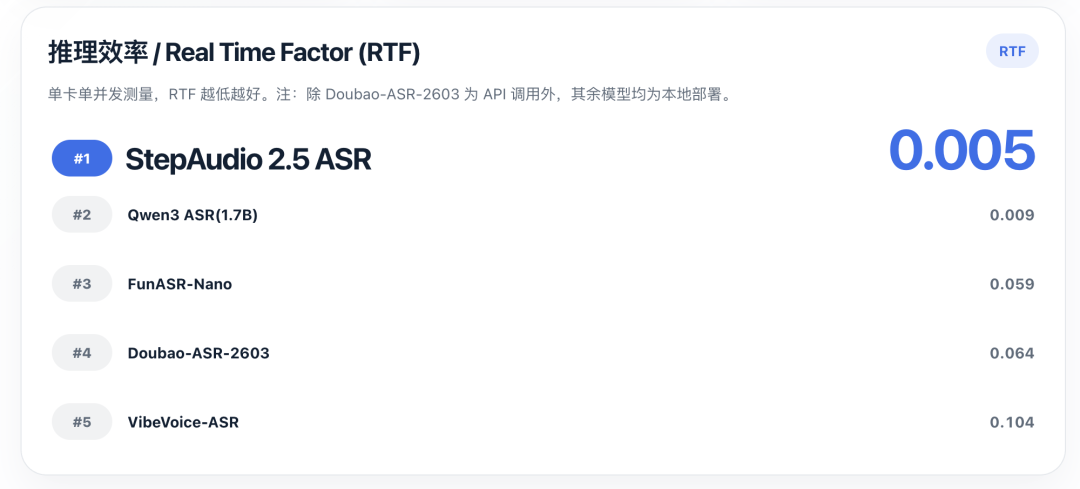
推理速度提升约400%、时延降低60%、成本下降80%。作者 | 佳扬编辑 | 云鹏智东西4月24日报道,阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。官方数据显示,其推理速度提升约400%,时延降低60%,推理峰值达500tokens/s,成本下降80%,并在多项公开测试集中取得较低错误率。精度方面,阶跃星辰称StepAudio 2.5 ASR在多项主流评测基准上达到业内领先水平;在效率上,约5分钟音视频可在较短时间内完成转写,支持最长30分钟音频的一次性完整转写。定价方面,StepAudio 2.5 ASR为0.15元/小时,仅为上代Step ASR 2的1/10。不过,在实际测试中,模型对不同音频输入的适应性存在差异:部分上传音频未能成功识别,而在实时录音场景下表现较为稳定,整体转写准确度较高。01.不同模式下语音识别效果存在差异官方演示场景下,面对大段连续口述内容,StepAudio 2.5 ASR可实现长时间连贯输出,在识别过程中保持文本还原稳定、语义完整,长音频转写质量表现均衡。与此同时,模型具备更强的复杂语境适配能力,针对日常高频的中英混杂表达以及绕口令这类发音紧凑、咬字复杂的特殊语句场景,均能稳定完成精准识别与完整转写,抗干扰能力与语言包容性进一步提升。▲阶跃星辰官方演示我们也依托阶跃星辰在线体验平台开展了实测,选取张雪峰高考志愿填报课程录音作为测试素材,着重检验该模型在长音频场景下的实际识别能力。该模式主要面向会议纪要整理、采访录音转写、课程内容归档、语音备忘提取及客服录音质检等场景,支持 WAV、MP3、OGG、PCM 等主流音频格式,单文件大小不超过20MB,同时支持中文、英文及中英混合识别。不过,在多次上传该音频后,系统均提示未检测到清晰语音,未能完成有效转写,相关原因尚不明确。随后,我们改用现场录音进行测试。该模式主要面向快速语音备忘、现场会议纪要、口述转写及语音笔记等场景,支持中文、英文及中英混合识别,单次录音时长上限为2分钟。识别结果如下:在这一场景下,模型能够完成正常识别,整体转写结果较为准确,对口语内容的还原度较高。细节上,模型在说话人出现较长停顿时,会自动插入额外的逗号;同时算法完整保留了日常口语中的自然重复、口头复述等表达特征,还原了原始说话的语言状态。02.Multi-Token Prediction优化推理效率StepAudio 2.5 ASR将Multi-Token Prediction技术引入语音识别赛道,沿用Step 3.5 Flash同款技术方案,依托Audio Encoder+Linear Adapter+LLM+MTP-5融合架构,打破传统串行输出限制。该模型可单次预判多组候选Token,并结合并行验证机制快速输出识别结果,从底层架构优化推理效率。官方实测数据显示,相较传统识别方案,该模型推理速度提升400%,整体时延压缩60%,推理运行成本下降80%,峰值推理速率可达500 tokens/s,大幅提升音视频转写的实时性与性价比。推理效率方面,阶跃星辰官方数据显示,StepAudio 2.5 ASR高于Qwen3 ASR(1.7B)、FunASR-Nano、Doubao-ASR-2603。长音频处理是语音识别的长期行业痛点。目前主流方案多采用音频切片、分段识别、后期拼接的处理模式,切割后的片段相互独立,易造成上下文信息割裂,长时长内容识别时易出现语义断层、信息遗忘等问题。对此,StepAudio 2.5 ASR复用LLM原生32K上下文窗口能力,支持端到端一次性处理最长30分钟的连续音频,无需分段切割,全程保留完整上下文关联,保障长时段对话、会议、访谈等场景的识别连贯性。识别精度层面,该模型在多组权威公开数据集当中表现稳定。在LibriSpeech clean/other等五组主流英文开源测试集里,词错误率优于同期同类模型,能够以更低算力消耗实现更高质量的转写效果。针对30分钟满负荷长音频开展专项测试,模型识别精度始终维持在行业顶尖水平,未出现长文本识别常见的精度逐级衰减问题,长时序内容识别稳定性显著提升。03.结语:关键指标提升真实场景仍是考场整体来看,StepAudio 2.5 ASR的改进主要集中在推理效率与长上下文建模能力上,这也是当前语音识别系统的关键指标。但从实测情况来看,其在不同音频输入条件下的稳定性仍有提升空间,尤其是在复杂或非标准音频的适配能力方面,仍有待更多实际场景与第三方评测进一步验证。