点击下方卡片,关注“具身智能之心”公众号
一直以来,具身大脑的相关研究最的核心就是数据问题,具身数据不像文本数据一样,可以从海量互联网信息上获得。
过去有很多工作试图通过仿真合成数据来解决这个问题,但是仿真引擎本身和真实世界的巨大差距限制了这些方法。UMI方法大大降低了数据采集的难度,但仍然依赖于专门的数采人员进行采集。Egocentric数据相关的研究现在很热门,但它也面临着人和机器人因为结构不同导致的一系列retargeting问题。
行业的一个共识是,机器人本体的动作数据是最珍贵的,然而过去的方法普遍依赖于遥操员人工采集,效率太低而且价值不菲。工业界很多人重视的一件事是怎么让数据飞轮转起来,让机器人自己就在真实的场景中去收集数据。一旦这个飞轮转起来,它就会越转越快,过去珍贵的这部分数据也会变得越来越多,铸成企业真正的“护城河”。
LWD就是这样的一篇工作,它专注于解决这个硬核且重要的问题。近期,具身智能之心同LWD的负责人 —— 智元首席科学家罗剑岚老师,进行了线上的采访,在此一并将访谈中的一些问题和回答进行汇总,希望对更多人有所帮助,共同促进整个具身智能行业的进步。本文的后一部分也提供了对于LWD这篇工作的解读,方便读者更详细地了解LWD的细节。

LWD的一个重点是数据飞轮,要让飞轮转起来,主要的瓶颈是什么?
机器人本身是一个系统工程,单独拆开来看,数据、基建、算法、机器人数量和人工干预都很重要。但如果只看当前阶段,最核心的瓶颈还是 cost,也就是大规模真实部署背后的经济问题。
如果真的有足够多的机器人在真实场景里持续干活,比如有上万小时、上万台机器人级别的真实交互数据,那么即使现有算法不能直接“拿上去马上用”,其中很多 incremental improvement 的部分也是可以工作的。换句话说,谁能部署更多机器人、让更多真实数据持续回流,谁就更有机会把数据飞轮真正转起来。
当然,在 scale up 的过程中,还会继续遇到数据质量、基础设施和算法层面的新问题。但这些问题更像是随着部署规模扩大逐步暴露、逐步解决的问题,而不是在一开始就能完全预先解决的问题。
如果在真实场景里部署,让这个数据飞轮转起来,哪些落地场景会比较好?
家庭这类场景过于开放,语义、环境和任务都非常开放,对泛化能力的要求很高,现阶段未必是最容易跑通数据飞轮的地方。但如果场景过于结构化,比如完全固定流程的工业场景,又会弱化具身智能本身的泛化价值。
比较合适的场景介于这两者之间,可能是商超、药店、便利店这类半结构化场景。它们的 layout 和物品类别有一定规律,不是完全不可控;但同时又存在丰富变化,对泛化性和性能都有要求。因此这类 middle ground 场景比较适合展示“高性能通用机器人系统”的价值。
具身智能的技术研究会逐渐平民化,还是会逐渐大厂化,变成只有大厂和少部分顶级实验室能参与的研究?
学术界资源比工业界少,这件事一直存在,只是在 AI 时代这个 gap 会被进一步放大。但这并不意味着普通开发者、高校和学术界就没有参与空间。相反,越是在资源差距明显的时候,越应该重视基础研究。例如LWD 中的 QAM 算法就借鉴了其他团队的一项基础算法工作,这类工作并不一定需要特别贵的机器人或大规模资源,很多时候可以先在仿真里验证,但它依然可能对后续大规模机器人系统产生很大影响。
所以两类路线会长期并行:工业界有更多资源,可以推动大规模系统和影响力更大的工程;学术界和自由开发者资源少一些,但自由度更高,可以做很多基础、开放和探索性的工作。历史上很多重要突破,比如 DDPM,也是在大厂拥有大量 GPU 的时代由学校做出来的。
为什么LWD奖励函数使用的是稀疏奖励?
核心原因是 dense reward 容易带来 reward hacking。稠密奖励确实可能让模型学得更快,因为它提供了 shaping 信号;但手写 reward function 往往很难和真实物理系统、智能体真正应该完成的行为一一对应。
一个典型例子是仿真里用 RL 学走路。如果奖励只写成“重心速度越快越好”,模型可能会找到一种不符合常识的“前进方式”,比如把头放在地上、腿朝上,用奇怪姿态让重心快速移动。为了修正这些问题,又要不断增加脚朝地、头朝上、姿态合理等额外项,最后 reward function 会变得非常复杂,而且仍然不一定和真实目标完全一致。
机器人操作也是类似的。manipulation 任务里,很难一次性把所有细节奖励都写对;只要没写对,就可能被模型 hack。因此稀疏奖励的好处是,它至少能保证最终行为符合预期:成功就是 1,不成功就是 0。
而尽管如此,稀疏奖励的问题也很明显:长程任务中信号很少,backup 不稳定,很难把正确信号传回前面的步骤。LWD 用 distributional value learning 来缓解这个问题,把原本的标量价值信号建模成分布,通过备份这个分布来保留更多统计信息。
未来LWD这种能边部署边去有数据回流的技术普及开来之后,会对整个数据采集、标注、训练的链路带来哪些改变?
具身智能行业的发展可以参考一下自动驾驶,自动驾驶没有办法在真实道路上随意在线试错,所以会发展出世界模型、高保真仿真器和离线评测体系;从产业链看,它也经历了从少量试采车、离线数据采集,逐渐转向部署数据回流、处理回流数据、再训练、再推送模型的迭代过程。
机器人如果能形成 LWD 这样的部署闭环,数据链路也会从“先采集、再训练、再部署”的离线管线,转向“部署中持续回流数据,云端持续训练,再把新模型推回机器人”的过程。区别在于,机器人场景如果允许在线学习和试错,这套在线闭环的效率可能会更快。
如何看VLA和世界模型两条路线的未来走向?世界模型会取代VLA吗?
这取决于怎么定义 VLA。如果 VLA 指的是 vision-language-action model,即同时包含视觉、语言和动作,那么它不太可能被简单取代。机器人要做动作,一定需要 vision,也一定需要 action。
真正有争议的部分更多是 language 是否必要。如果机器人要在开放世界中完成复杂操作、长程任务拆解和类似人的推理,那么 language 是需要的,因为语言模型是目前实现这类推理能力最好的工具之一。
但这不意味着现在的 VLA 形式一定会固定下来。比如是不是一定要把 action 当成若干 token 接到 VLM 后面、对齐到某个 latent space,这些都不一定。现在大家说的 VLA、world model 或 video prediction model,更多是在讨论预训练路线。LWD 强调的是另一点:预训练要和部署结合,形成预训练和后训练共同驱动的部署闭环。部署不是训练的终点,而是机器人智能持续提升的起点。
最近半年真机强化学习的方向可能会比之前的进展会更多一点,这是为什么?
强化学习本质上是一种优化方法。机器人要真实部署,就必须达到一些具体指标;只要要优化这些指标,就需要一种优化工具,而强化学习目前是很合适的工具。
预训练更像是 learning,帮助模型从数据中找到 pattern;而部署阶段还需要 search 或 optimization,在已有模型基础上进一步优化到目标指标。只要机器人要进入真实世界部署,就需要形成数据闭环,并用类似 LWD 的在线提升系统持续优化这些 metrics。
所以这不只是最近半年的短期现象。从底层逻辑看,只要目标是真实部署,强化学习就会是非常重要的一类方法。
有没有观察到一些“涌现”现象?
LWD 是在预训练模型基础上做后训练,一个明显观察是后训练对数据的利用效率很高:即使用的数据量不算特别大,也能看到性能提升。同时也观察到,随着后训练时间增加,模型性能会在多个任务上同时提升。更大规模实验中,未来可能会看到类似 test-time scaling 的现象。
但目前还没有明确的“临界点”结论。机器人不完全等同于语言模型,语言模型的 scaling 往往可以通过 pretraining loss 和下游 benchmark 建立比较清晰的关系;机器人还需要先把问题定义清楚,包括在哪些部署场景、优化哪些指标,然后才能进一步讨论 scaling 或涌现。
LWD方法中部署后收集的那些数据是百分百拿来利用吗?还是说会有一些自动化的数据过滤机制?
LWD 是强化学习框架,部署后的数据会全部回流使用,没有人工筛选步骤。系统是在线、分布式地把数据拿回来训练。
对于人工干预数据,处理方式也不是简单地一律当成成功示范。如果人工干预后任务最终成功,就标记为 1;如果干预后仍然失败,就标记为 0。随着机器人自主性提升,人工干预的比例应该逐步下降。
原论文:Learning while Deploying: Fleet-Scale Reinforcement Learning for Generalist Robot Policies 项目页:https://finch.agibot.com/research/lwd
以下是LWD原文的解析。
过去两年 VLA 的主流做法是先用大规模离线机器人数据做预训练,再通过 SFT 或任务级 post-training 把模型推到真实任务上。RT-2、Octo、OpenVLA、 这类工作已经证明了这条路线的上限:一个 generalist policy 可以从多源数据里获得相当宽的机器人基础能力。但真实部署不是一个固定测试集。机器人进入商店、家庭和工作空间后,会不断遇到预训练数据没有覆盖的新物体、新摆放、新指令偏好和长尾失败。
已有工作已经从不同角度出发来解决这个问题。 用离线价值学习和 iterative offline RL 改进单个真实任务,RLDG 用 specialist RL 生成数据再蒸馏回 generalist policy;VLA-RL、RIPT、RL、Flow-GRPO、ReinFlow 则尝试直接用在线 rollout 微调 VLA。这些方法说明 RL 确实能把任务结果转成策略改进,但它们往往更接近单任务 post-training、specialist policy 或 on-policy 更新。换句话说,它们回答了“一个任务能不能通过 RL 变强”,但还没有完整回答“一个共享 generalist VLA 能不能在多任务部署中持续变强”。
这篇工作提出Learning While Deploying (LWD) 的核心动机正来自这个缺口:部署本身不应该只是评测和数据记录,而应该成为 generalist VLA 的持续训练机制。作者把 16 台真实双臂机器人在执行中的成功、失败、恢复和人工干预汇入共享 replay buffer,再用同一套 offline-to-online RL 目标更新 policy、critic 和 value model,使一个 pretrained flow-based VLA 能随着 fleet experience 累积而持续改进。
LWD的核心方法包括 Distributional Implicit Value Learning(DIVL) 和 Q-learning with Adjoint Matching (QAM) ,核心方法部分涉及到的公式较多,需要读者有一定的强化学习基础。
问题定义
LWD 要做的不是单任务 RL,而是让一个共享 generalist policy 在多任务真实部署中持续变好。论文把机器人控制写成马尔可夫决策过程:
其中 是状态空间, 是动作空间, 是环境转移, 是奖励函数(任务最后一步成功则r为1,否则为0), 是折扣因子。任务用 索引,一个状态写作 ,其中 是机器人观测, 是任务语言指令。对于长程任务, 只是 “Make Tea” 这类高层指令,而不是分解好的低层步骤。
VLA policy 每次不输出单步动作,而是输出一个 action chunk:
这里 是参数为 的策略, 是 chunk 长度, 是从当前时刻开始的一段动作序列。对应的 chunk reward 写成:
LWD 的 replay 样本不是单步 ,而是 chunk-level transition:
这个设定很关键。长程任务持续 3-5 分钟,包含 5-8 个标注子步骤,终止奖励又很稀疏。如果只把部署中的人工干预片段当作模仿学习标签,模型只能学到“人此时怎么纠正”,却不能系统利用失败轨迹告诉它“哪些动作路径没有通向成功”。LWD 作者认为,部署数据里最有价值的部分包括失败、部分恢复、成功前的长路径和偶发人工干预,这些都需要 RL 目标来吸收。

LWD 的训练流程分成两段。第一段是 offline RL pre-training,用已有离线 buffer 初始化 policy、critic 和 distributional value model。第二段是 continuous online post-training,把当前 policy 部署到机器人 fleet 上,收集 autonomous rollouts 和可选人工干预,再和 offline buffer 混合训练。

核心方法
LWD 的方法由两部分组成:Distributional Implicit Value Learning(DIVL)负责从混合 replay 中学习价值,Q-learning with Adjoint Matching(QAM)负责把 critic 的动作梯度转化成 flow policy 可以稳定学习的局部监督。
先看论文作为出发点的Implicit Q-Learning(IQL)。IQL 不显式做 ,而是把状态价值拟合到 dataset action-values 的高期望:
这里 是标量状态价值函数, 是 EMA target critic, 控制乐观程度。当 时,价值估计会偏向数据集中更高价值的动作。 是非对称二次损失, 是 critic value 和 state value 之间的差。
这个非对称损失可以理解成“把 往数据动作里的高价值一侧推”。当 ,说明当前 低估了某个数据动作的价值,损失权重是 ;当 ,说明当前 高于这个动作的价值,损失权重是 。如果 ,低估高价值动作时被罚得更重,最终 会靠近数据动作 分布的高分位,而不是均值。这也是 IQL 能在不显式求 的情况下做 policy improvement 的关键。
IQL 的 critic target 写作:
是 chunk reward, 是跨过一个 action chunk 后的折扣, 是执行 chunk 后的状态。IQL 的好处是避免在离线数据之外找动作,但问题是它最后仍然把同一状态下可能多峰的回报压成一个标量。
这里的 也值得单独看。policy 一次不是输出单步动作,而是输出一个 action chunk,所以 TD backup 也从 直接跳到 。这意味着 critic 学的不是“一个控制周期后会怎样”,而是“执行完这一段动作 chunk 后会怎样”。对长程任务来说,这样能减少时间步数量,但也让奖励传播更依赖 value bootstrap 的质量。
LWD 认为机器人集群数据不适合这种压缩。不同机器人、不同任务、不同 policy 版本、成功和失败轨迹、人工干预片段混在一起,同一个状态附近的回报可能不是单峰平均值。于是 DIVL 不直接拟合标量价值,而是拟合回放动作-价值的分布:
这里 表示在状态 下,回放中动作 对应 critic value 的分布; 是条件在该状态上的经验回放动作分布。注意, 在 DIVL 里不是一个标量,而是一个分布模型。
这一步和 IQL 的差异可以这样理解:IQL 直接问“这个状态应该有一个什么数值 ”;DIVL 先问“这个状态附近的 replay 动作会产生哪些不同的价值”。对于 fleet replay,这个差别很重要。同一个厨房台面状态下,历史 policy 可能失败,人工接管可能成功,新 policy rollout 可能只完成一半;把这些结果平均成一个 会损失结构,而分布 至少保留了“低价值失败模式”和“高价值成功模式”同时存在这一事实。
DIVL 用 EMA critic 给出监督,最小化负对数似然:
直观上,这一步是在问:在状态 下,当前 replay 动作的 target critic value 应该落在价值分布的哪里?论文实现中使用了分类离散化,附录给出的真实机器人实验设置是 个 atoms,support 为 。
因为 是一个离散分布,这个负对数似然本质上就是分类学习:先把 投到 的某个 atom 或相邻 atoms 上,再让 value distribution 给这个位置更高概率。这样训练出来的 不是直接输出“平均价值”,而是输出一整条价值直方图。
得到价值分布后,DIVL 不取均值,而是取 -分位数 作为 bootstrap 统计量:
是由 诱导的 CDF。 越大,取到的分位点越乐观; 越小,bootstrap 越保守。critic target 因此变成:
这个公式的作用是把 IQL 的高价值action保留下来,但不再用单一标量期望,而是先保留价值分布,再从分布中抽取分位数。
如果 是单峰且很尖,取均值、取分位数差别都不大;但如果它是多峰的,分位数就会体现策略偏好。比如一个状态下 70% 的历史动作失败、30% 的动作成功,均值可能落在一个没有真实含义的中间值,而较高 分位数会更接近成功模式。
论文进一步把非对称损失写成统一形式:
对应 IQL 的期望形式, 对应 DIVL 使用的分位数形式。Proposition 1 说明,在理想条件下,直接用非对称损失回归标量,和先拟合价值分布再提取对应非对称统计量,两者得到的最优标量值一致。
简单来说,如果只关心最后取出来的一个统计量,那么“直接回归这个统计量”和“先学完整分布再从分布里读这个统计量”在理想条件下可以得到同一个最优值。DIVL 的实际好处在于,完整分布还能提供不确定性、熵和多峰结构,后面的 adaptive 正是利用了这一点。
的值控制了该目标的乐观程度:较大的 τ 值会选择更高的分位数,从而产生更乐观的目标;而较小的 τ 值则会产生更保守的目标。在混合任务回放中,并非所有状态都适合采用相同的乐观程度,因此我们利用学习到的价值分布中的不确定性来调整 τ 。这里 DIVL 用价值分布的归一化熵作为不确定性信号:
是类别数, 是第 个类别上的概率。分布越散,熵越高,说明模型对该状态价值越不确定。于是论文设置:
是目标乐观度, 控制对不确定性的敏感度。熵高时 被压低,减少过估计;熵低时保留更乐观的 target。
这相当于给每个状态单独调节“乐观程度”。如果价值分布很散,说明当前状态在 replay 里对应的结果很不一致,直接取高分位可能把偶然成功当成稳定能力;此时降低 更保守。如果分布很集中,说明 value model 对这个状态比较确定,就可以取更高分位,鼓励 critic 和 policy 往高价值动作靠。
而QAM 解决的是另一个问题:怎么用这个 critic 来更新 flow-based VLA。Flow Matching 把动作生成写成从噪声到数据动作的连续向量场。给定真实动作 chunk 和高斯噪声 ,插值为:
模型训练条件向量场 去匹配速度 。 是 flow 时间, 是插值路径上的动作。
如果直接把 反传过完整多步 denoising 过程,会很慢并且也不稳定。QAM 的做法是定义 KL-regularized improvement target:
其中 是固定 reference policy, 是 temperature。价值越高的动作,在改进后的目标分布里权重越大; 越大,更新越保守。
这个目标可以看成一次受 KL 约束的 policy improvement:新策略 既要偏向高 动作,又不能离 reference policy 太远。问题在于, 和 都是 flow policy,它们的动作概率密度和采样结果都由一整段 denoising/ODE 轨迹隐式决定。如果直接优化 ,梯度必须从终点动作 反穿整个 flow 积分过程(而这这样做太慢了)。
QAM 把这个目标改写为 reference flow 轨迹上的局部回归:
终端 adjoint state 为:
这里 是固定 reference flow, 是要更新的 policy flow, 表示当前 policy 相对 reference 的向量场改变量, 是沿 flow 反向传播的 adjoint state。 由 critic 的动作梯度初始化,所以 QAM 本质上是在不直接穿过完整 ODE 反传的情况下,把“价值希望动作往哪里改”转成每个 flow step 的监督信号。
更具体地说,正常做法会把最终动作写成:
然后让 穿过每一个 denoising step。QAM 则固定 reference flow ,先沿 reference 轨迹得到 ,再用 critic 在终点给出方向:
这里有负号,是因为推导里通常把 policy improvement 写成最小化 cost 。 不是动作本身的目标,而是梯度信息。adjoint 的作用就是把这个终点梯度沿 reference flow 反向传播到每个中间时刻,得到 。
QAM loss 里的平方项可以直接展开:
最后一项和 无关,可以看成常数;前两项分别对应“不要偏离 reference flow 太多”和“沿 critic 希望的方向改动作”。这个局部二次目标的最优解满足:
因此:
这就是adjoint matching的意义:不直接把 的梯度穿过完整 denoising ODE,而是把终点的价值梯度通过 adjoint 分配到 reference flow 轨迹上的每个 ,再让 去拟合这些局部速度场偏移。

offline-to-online 数据飞轮和 fleet-scale 部署
LWD 的训练不是先离线再完全换一个在线目标,而是 offline stage 和 online stage 共用同一套 learner。算法 1 先用演示数据做一次预训练,再固定 reference policy ,初始化 和 target critic 。offline stage 从 采样训练,online stage 则让 robot actor 异步执行当前 policy,把 transition 写入 ,central learner 从 混合采样。

长程任务的稀疏奖励传播很慢,所以 offline stage 使用 n-step chunk-level TD target:
这里 控制跨越多少个 action chunk 做 TD backup。论文设置短任务如 grocery restocking 用 ,长程任务用 。如果 episode 在 n-step window 内终止,就截断回报并移除 bootstrap 项。online stage 使用 1-step chunk-level TD,论文给出的原因是在线轨迹可能混合 policy transitions 和 human interventions,长 backup 更容易跨过不同数据来源,使 TD path 不再对应单一 policy execution。
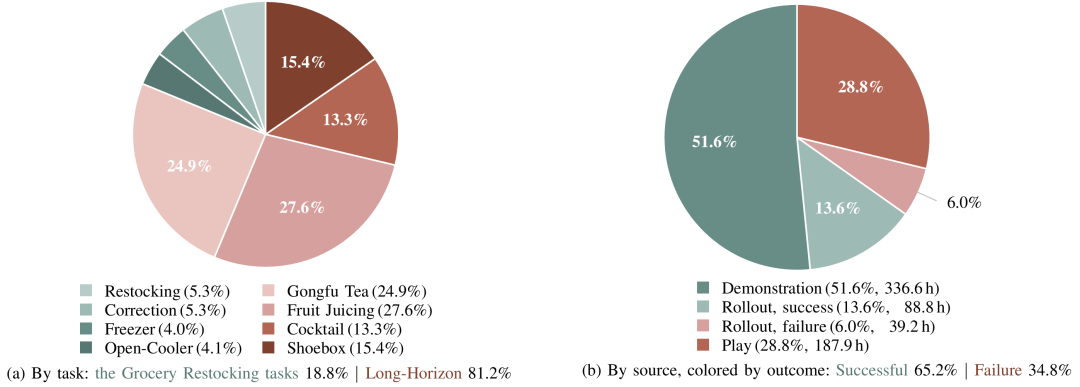
离线数据由三类组成:expert demonstrations、historical policy rollouts 和 play data。Demonstrations 都是成功轨迹,rollouts 包含成功和失败,play data 是人工引导探索失败模式和边界情况。总量是 652.5 小时,其中 demonstration 336.6 小时,successful rollout 88.8 小时,failed rollout 39.2 小时,play data 187.9 小时。

模型结构上,policy 和 value/critic 是分开的。 和 使用共享 Gemma3-SigLIP VLM backbone,但有不同预测头;policy actor 使用 的 flow-based VLA 架构,包含 PaliGemma vision-language backbone 和 Gemma-300M action expert。offline RL 阶段 actor 和 value/critic 都 fully fine-tune;online QAM 更新时冻结 policy VLM backbone,只更新 action expert,而 value/critic 继续 fully fine-tune。
实验平台是 Agibot G1 双臂机器人,每台有两个 7-DoF 机械臂、parallel-jaw grippers 和三个 RGB 相机。在线训练使用 16 台机器人并发采集:4 台用于 grocery restocking,四个长程任务各 3 台。每个在线实验给每种方法 4 小时 wall-clock budget,相当于整个 fleet 约 60 小时在线数据。

系统层面,actor 会把 episode 上传到 object storage,再通过 message queue 通知 cloud side。Coordinator 提交版本化 snapshot,multi-host SPMD JAX learner 通过 DRB Reader 读取一致的数据视图,训练后再把新 policy 发布给所有 robot actors。

论文报告的 operational latency 如下:episode produced 到 available to learner 的 P50/P99 为 41 秒/148 秒,model published 到 received by actor 的 P50/P99 为 38 秒/55 秒。作者也强调绝对值依赖网络配置和链路拥塞。

实验结果:真实任务收益、消融与系统代价
论文评测了 8 个真实任务:四个 grocery restocking 任务,以及四个长程任务 Make Cocktail、Brew Gongfu Tea、Make Fruit Juice 和 Pack Shoes。grocery restocking 采用二元成功率;长程任务采用 step-wise success score,每个标注子步骤按 1、0.5、0 评分,再对步骤平均。

主结果非常直接。LWD Online 在平均分上达到 0.95,高于 SFT 的 0.76、RECAP 的 0.85、HG-DAgger 的 0.85 和 LWD Offline 的 0.88。更关键的是长程任务:Gongfu Tea 从 SFT 的 0.64 提升到 0.89,Fruit Juice 从 0.66 提升到 0.90,Cocktail 从 0.70 提升到 0.93,Shoebox 从 0.70 提升到 0.92。


这个结果说明 LWD 的收益并不只是“更会做短任务”。grocery restocking 上多数 post-training 方法已经接近饱和,但 LWD 仍然保持接近最优;真正拉开差距的是需要多阶段执行、接触丰富操作和错误恢复的长程任务。
价值函数可视化也支持这一点。在成功的 Gongfu Tea episode 中,distributional value 的分位数value 会随着关键子步骤完成而上升;失败 episode 中,value 有局部波动,但在执行不再推进后保持较低。也就是说,即使奖励只在终止成功时给出,DIVL 学到的价值仍然能在一定程度上反映任务进度。

论文的第一个关键消融是 value learning design。把 DIVL 换成 scalar期望regression 后,短任务差异不大,但长程任务差距明显:offline setting 下从 0.72 到 0.79,online setting 下从 0.78 到 0.91。作者的解释是,fleet replay 中存在多种成功、失败和干预轨迹,标量价值会把这些异质结果压成平均值,而分布式价值可以保留 rare but reproducible high-return modes。

附录中的完整 per-task ablation 也保持同样趋势:online DIVL 在八个任务平均 0.95,而 online期望regression 为 0.88。

第二个消融是 adaptive 。论文把 adaptive schedule 和固定 对比,其他组件不变。adaptive 让 offline LWD 平均分从 0.84 提升到 0.88,尤其在 Restocking、Correction 和 Cocktail 上更明显。这个结果对应前面的公式:当价值分布熵高时降低 ,可以让 bootstrap 更保守;当分布更集中时提高 ,则鼓励策略选择高价值解。

附录还给出动态 和 normalized entropy 的训练曲线。entropy 在 offline-to-online 两个阶段都下降,说明价值估计逐渐更确定;相应地, 逐渐上升,训练目标更倾向于高价值解。

预测价值分布的可视化进一步说明,成功 episode 中分布保持单峰且 mode 从约 0.4 增长到 1.0;失败 episode 中 mode 只从约 0.5 到 0.6 后停滞。这虽然无法直接证明 value function 完美,但说明它确实捕捉到了成功进展和失败停滞之间的差异。

总结
LWD 这篇论文的公式很多,理解起来需要一定的基础。和 HG-DAgger 这类交互式模仿学习相比,LWD 的关键差异是没有把人工干预当成唯一监督。它显式使用失败 rollout、play data 和稀疏任务奖励,通过 DIVL 学价值,再用 QAM 改进 flow action expert。和 RECAP 这类离线 post-training 相比,LWD 在在线阶段继续以同一套 RL objective 混合 offline buffer 和 online buffer,而不是停留在 collect-train-deploy 的离线迭代。
总体上,LWD 给出的方向是清晰的:generalist robot policy 不应该只在离线数据上变大,而应该在真实部署中持续变准。对于真实机器人系统,这可能比单次 benchmark 上的分数更重要。具体方法上,LWD方法表现出了比包括RECAP在内的一系列RL算法更强大的能力,DIVL方法也给笔者带来了新的思考——或许我们要重新审视“拟合标量价值”这件事。










