
搞脑科学的人,和搞人工智能的人,长期以来有点像“鸡同鸭讲”。一边手里攥着fMRI、脑电图、神经元放电数据,另一边抱着HuggingFace上的大模型,两边都想看看“大脑和神经网络到底谁像谁”,结果第一步——数据格式——就卡住了。
最近,Meta FAIR联合巴黎高师、罗斯柴尔德基金会医院等机构,在arXiv上放出了一个叫NeuralSet的Python框架。它的野心很大:把从fMRI到视频,从脑电波到大语言模型,全部塞进同一个PyTorch DataLoader里。换句话说,它想给神经AI领域铺一条“统一的高速公路”,让搞模型的和搞脑科学的,终于能坐在同一张桌子前说话。
01.碎片化有多离谱?每个实验室都在重复造轮子
先来说个常识:神经科学的开源工具其实不少。分析脑电和脑磁的,有MNE-Python、EEGLAB;玩fMRI的,有Nilearn、fMRIPrep;搞深度学习的,有PyTorch和HuggingFace。每一款都是各自领域的“金字招牌”。
但问题是——它们互相不认识或者不兼容。
这些工具大多是二十年前“前深度学习时代”设计的,默认数据集能一股脑塞进内存。可现在公开数据集动辄上TB,实验刺激也从简单的闪光方块变成了连续的电影、对话、自然场景。研究者想把GPT-2的词嵌入和MEG信号对上时间轴?对不起,你得自己写脚本、手动对齐、手动缓存,甚至手动管理内存。
结果就是:全世界几百个实验室,每年都在重复写同一批“数据搬运”脚本,像一座无形的墙,大家说着不同的数据语言。
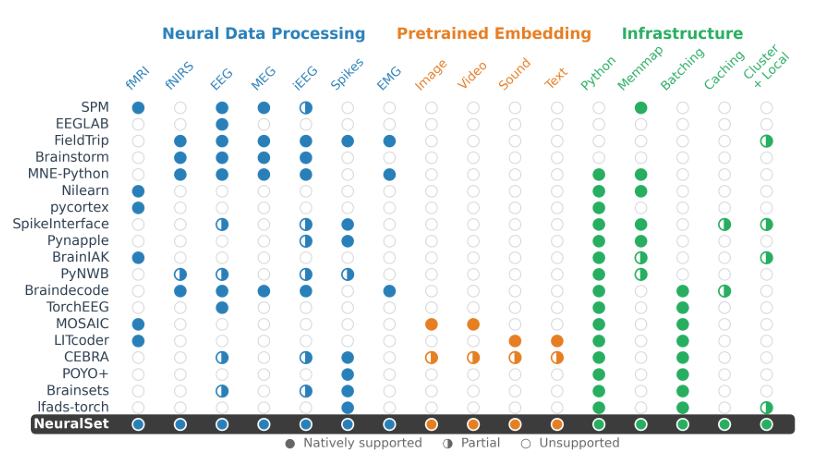
图1 现有工具生态对比。
02.把“结构”和“数据”彻底分开
NeuralSet最核心的思路,用行话叫“结构-数据解耦”。
它设计了一个叫Events(事件)的轻量级层。实验里的一切——一次fMRI扫描、视频里出现的某一帧、 narrator说出的某个单词——都被记成一行简单的元数据:什么时候开始、持续多久、属于哪条时间线。所有这些信息拼在一起,就形成pandas表格,你可以在笔记本电脑上秒开、筛选、重组,根本不需要碰那些几十GB的原始信号文件。
等你真正要训练模型了,NeuralSet才派出Extractors(提取器)去取数据。fMRI的提取器调用Nilearn做空间平滑,MEG的提取器调用MNE-Python做滤波,文本的提取器直接对接HuggingFace里的GPT-2或LLaMA。你想换种模态?改一行配置就行,不用重写整个pipeline。

图2 NeuralSet全流程示意图。
03.一个“万能转接头”,通吃所有模态
NeuralSet最夸张的地方,是它的“接口”几乎覆盖了神经科学和AI的全部主流数据类型。
神经记录端:fMRI、MEG、EEG、iEEG、fNIRS、EMG、Spike放电,全都能接。实验刺激端:文本、音频、视频、图像,也全都能接。而且它不是简单读个文件,而是能把这些刺激直接送进预训练大模型拿到嵌入向量——比如用DINOv2处理视频帧,用Wav2Vec处理语音,用GPT-2处理文本。
更关键的是时间对齐。神经数据是连续的时间序列,但一个单词的嵌入向量本质上是个“静态”的东西。NeuralSet能把静态的向量展开成任意频率的时间序列,让它和脑电波的采样率严丝合缝地对上。这就像给不同轨道的火车,铺了一套统一的时刻表。
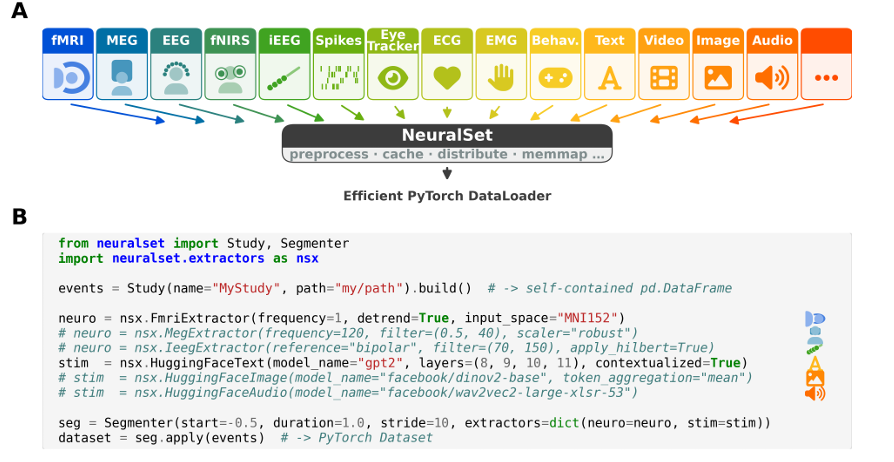
图3 NeuralSet统一处理架构。
04.静态还是动态?它都能
这里有个特别反直觉的设计,NeuralSet把数据分成静态和动态两种玩法。
静态提取:一个单词、一张图片,提取出一个固定的D维向量。适合那种“这个刺激长什么样”的场景。
动态提取:一段音频的梅尔频谱、一段fMRI的时间序列,输出的是D×T的矩阵,随着时间连续变化。
另外,NeuralSet允许你互相转换。比如一段音频本质上是动态的频谱图,但你可以把它“压扁”成一个静态向量送给分类器;反过来,一个单词的静态词嵌入,也可以按时间轴展开成动态序列,和脑电信号逐帧对齐。
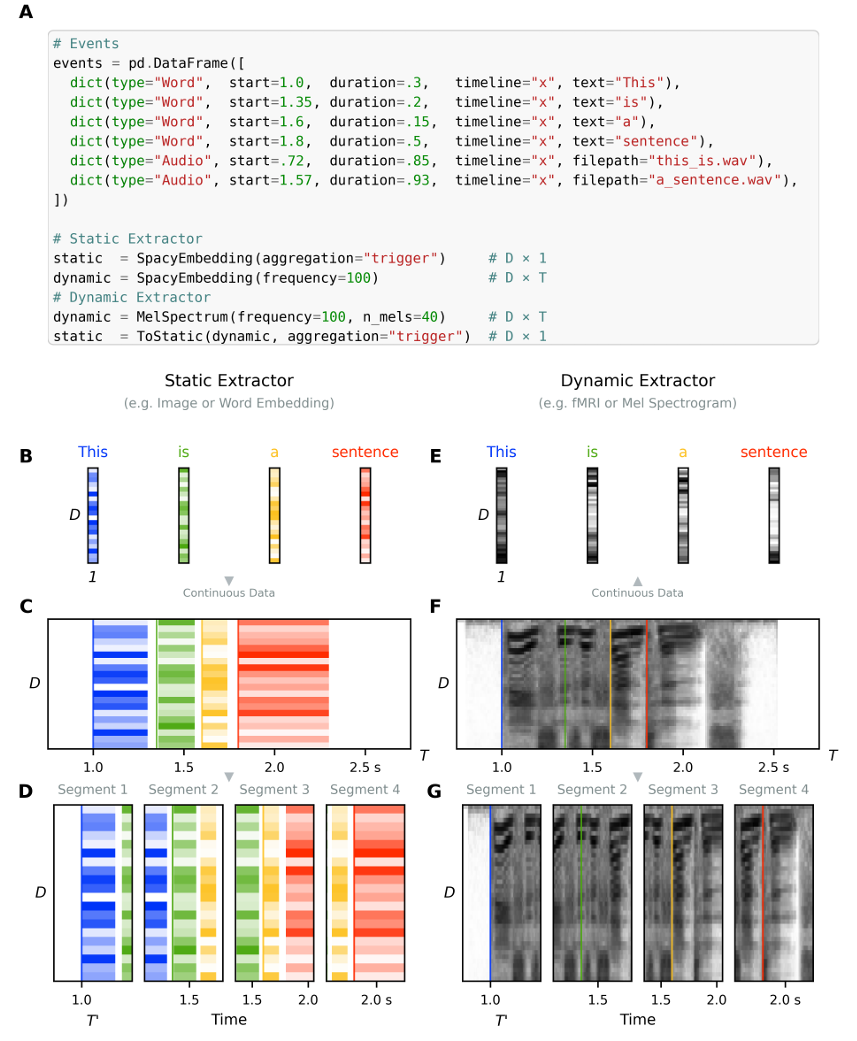
图4 静态与动态提取器对比。
05.从笔记本到超算集群,只改一个配置
搞过大规模神经数据的人都知道,最崩溃的不是写代码,而是“跑了一晚上才发现参数写错了”。NeuralSet用Pydantic做了一层严格的配置校验,负频率、非法路径这种错误,在代码初始化阶段就直接弹窗报错。
它还搭了一套确定性缓存。你改了一个平滑核的参数,只有下游依赖这个参数的步骤会重新计算,其他分支完全不受影响。还有它的硬件抽象:同一套脚本,本地跑就是本地跑;把配置里的cluster改成slurm,框架自动帮你拆任务、提交作业、同步环境。你可以在笔记本上用一个被试调试通,然后一键把剩下100个被试甩给学校超算中心,代码一行不用改。
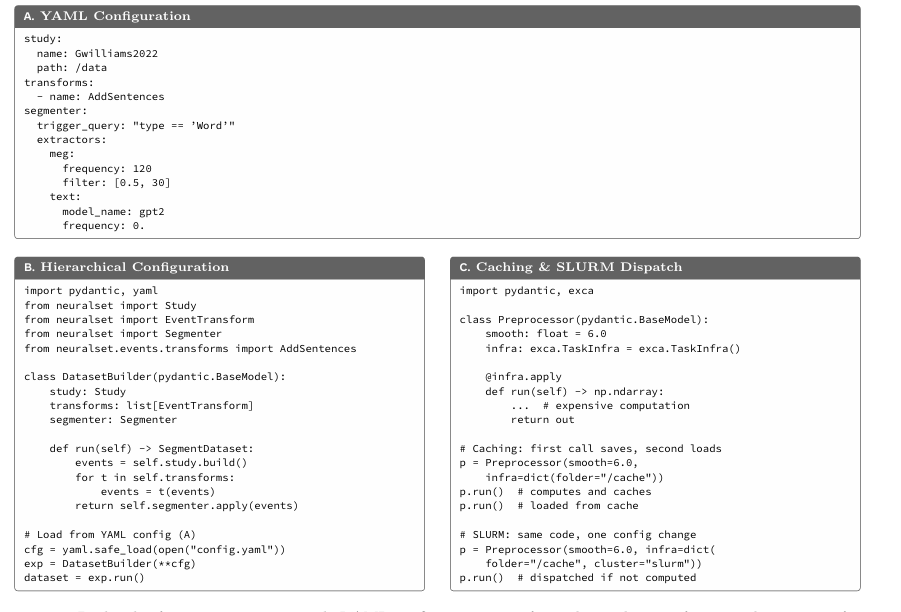
图5 NeuralSet后端架构。
06.它不是来砸场子的,是来当“指挥”的
看到这儿你可能会问:NeuralSet这么全能,那MNE-Python、Nilearn这些老牌工具是不是要下岗了?
答案是:恰恰相反。NeuralSet没有重新发明任何信号处理算法,fMRI的平滑还是Nilearn在做,脑电的滤波还是MNE-Python在做。现有库的维护者甚至可以通过一个轻量适配器,把自己的流程注册成NeuralSet的后端,直接获得惰性加载、缓存和集群能力。
说白了,NeuralSet填补的是一个生态位:预处理栈和深度学习框架之间的“断层”。
未来可期:当数据不再是壁垒
NeuralSet目前也不是没有短板。它依赖底层库,所以底层库的性能瓶颈它也会继承;另外,对那种需要跨会话、跨时间线的结构数据(比如用T1核磁给MEG做溯源定位),现在的支持还比较初级,未来可能会引入类似Polars的关系型数据框架来解决。
但这些都不妨碍它指向一个更大的图景:神经AI的瓶颈,正在从“缺数据”变成“缺一条打通数据的管道”。当fMRI、脑电、大模型词嵌入、视频帧特征能在同一个PyTorch batch里并肩出现,下一个关于“智能本质”的发现,也许就藏在某次训练迭代里。
参考: https://github.com/facebookresearch/neuroai/

脑机接口社区是国内首家脑机接口(BCI)产业服务平台。主要为企业、科研团队、投资机构和从业者提供以下服务:
宣传报道:图文、短视频、直播形式报道企业动态、技术解读、产品介绍等内容,提升曝光和行业影响力。
资源对接:根据需求匹配资本、供应链、临床机构、渠道方等资源,完成真实对接,促进合作。
成果转化:协助技术团队寻找产业方、投资人及落地场景,推动技术到产品的转化。
活动策划执行:承接线上线下路演、沙龙、论坛等活动的策划与执行。
其他定制需求:包括报告定制、市场调研、人才招聘支持等个性化服务。










