点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
过去一年,具身智能圈子里最热的词是 VLA。
一个 VLA 模型想要跑起来,并不只是加载权重、输入图像、输出动作这么简单。它背后还需要数据采集、数据存储、训练调度、仿真交互、RL 后训练、模型评测、推理部署、真机闭环。任何一个环节不稳,最后都会变成一句熟悉的话:论文看起来很好,代码跑不起来;仿真能跑,真机不稳;单任务能跑,多任务一上来就崩。
所以,具身智能正在进入一个新阶段。第一阶段卷模型,第二阶段卷数据,第三阶段卷 Infra。
这里的 Infra,不是普通意义上的机器人仿真平台,也不是某一个模型仓库,而是支撑具身模型持续训练、评测、部署和迭代的系统底座。今天挑五个代表性项目,分别对应五个关键方向:RL 后训练系统、VLA 工程平台、模块化研发框架、统一评测系统、机器人大数据管理。
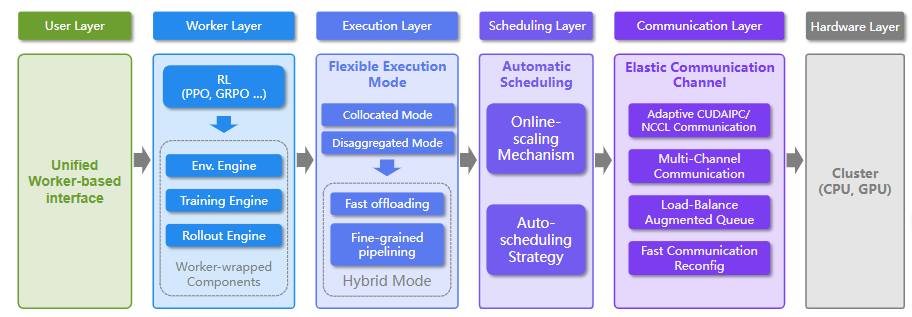
1.RLinf:VLA 后训练的“调度中枢”
如果说模仿学习解决的是“机器人学会照着人做”,那么 RL 后训练要解决的就是“机器人能不能在环境反馈里越做越好”。
RLinf 的重要性就在这里。它不是一个 VLA 模型,而是一个面向基础模型强化学习后训练的系统框架。对具身智能来说,这件事很关键。因为 VLA 不可能永远只靠静态数据集训练,真正部署到仿真和真机之后,模型一定会遇到失败、卡顿、误抓、误放、长程任务中断等问题。这个时候,系统要能把环境交互、rollout、奖励、训练、模型更新串起来。
传统 VLA 训练更像“离线做题”:给模型一堆示范数据,让它学会模仿。RLinf 代表的是另一个方向:把模型放回环境里,让它在任务执行中学习。这里最大的难点不是算法公式,而是系统工程。仿真要跑,模型推理要跑,训练也要跑,GPU、CPU、环境进程、模型服务之间要协调,否则训练吞吐很快就会被拖垮。
这也是为什么 RLinf 更像“训练操作系统”,而不是一个普通训练脚本。它真正想解决的是:当 VLA 进入强化学习和在线优化阶段,谁来管理这些复杂的执行流?
未来具身智能如果要从“会模仿”走向“会改进”,RL 后训练系统会越来越重要。
2.FluxVLA:把 VLA 从论文代码变成工程平台
FluxVLA 更像是国内具身模型 Infra 里很典型的工程化代表。
很多 VLA 项目刚开源时,代码结构往往服务于论文复现:数据怎么读、模型怎么训、推理怎么跑,都围绕某一个实验设计展开。但工程团队真正要用的时候,需求完全不一样。他们需要统一配置、统一接口、模块解耦、多机多卡训练、部署链路、真机接入,还要能把不同模型和不同机器人平台串起来。
FluxVLA 想做的就是这件事:把 VLA 研发从“单个模型实验”推进到“全流程工程闭环”。
它的价值不在于又提出一个新模型,而在于把数据、训练、评测、推理和真机部署放进同一个工程体系里。对于高校和企业团队来说,这类平台的意义很直接:减少重复造轮子,把精力从环境配置和代码适配中释放出来,转向模型改进、任务设计和真实部署。
这类项目的出现说明一个趋势:VLA 不再只是算法同学的事情,也变成了工程系统问题。未来团队比拼的,不只是有没有一个好模型,而是谁能更快完成从数据到真机的闭环。
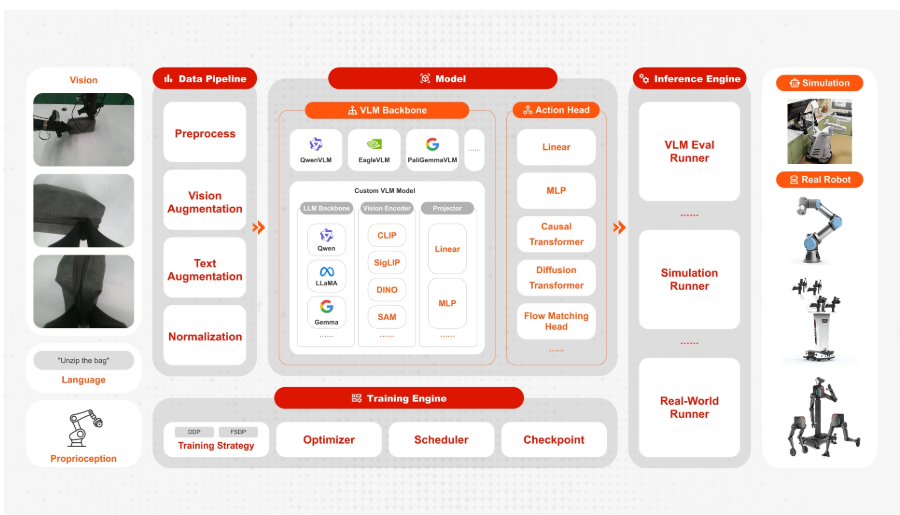
3.StarVLA:VLA 开发正在变成“乐高积木”
StarVLA 的关键词是 Lego-like。
这其实是一个很形象的比喻。过去做 VLA,很多东西是绑在一起的:换一个 backbone,代码要改一堆;换一个 action head,数据和训练逻辑也要跟着动;换一个 benchmark,又要重新写评测脚本。最后每个项目都像一个定制化机器,能跑,但不好拆,也不好复用。
StarVLA 想把这件事拆开。
它把 VLA 研发拆成更清晰的模块:模型 backbone、action head、数据加载、训练流程、benchmark 评测、部署接口。这样一来,研究者可以更容易地比较不同变量:同一个数据和训练框架下,换 FAST、OFT、flow matching 或 GR00T-style action head,到底会带来什么变化?同一个 action head 下,换不同 VLM backbone,又会发生什么?
这对行业很重要。因为 VLA 现在最大的问题之一,就是大家很难判断一个模型变强到底来自哪里。是数据更多?backbone 更好?action 表达更合理?训练 recipe 更稳定?还是评测设置更友好?
模块化框架的价值,就是让这些变量被拆开。它不一定立刻带来最强模型,但能让研究和工程迭代变得更清楚、更快、更可复现。
如果说 FluxVLA 更像工程闭环平台,那么 StarVLA 更像一个 VLA 研发工作台。

4.vla-eval:没有统一评测,模型比较就是玄学
VLA 领域还有一个长期痛点:评测太乱。
同样一个模型,在不同 benchmark、不同代码分支、不同依赖版本、不同 observation 格式下,结果可能差很多。更麻烦的是,很多团队为了跑某个 benchmark,会维护自己的私有 fork。久而久之,bug 修复不能共享,实验设置不透明,复现别人的结果变成一件很费时间的事。
vla-evaluation-harness,也就是 vla-eval,想解决的就是这个问题。
它的思路很简单:模型和 benchmark 解耦。模型只需要按统一接口提供预测能力,benchmark 也按统一接口运行任务。中间通过标准协议连接。这样一来,一个模型接入一次,就可以跑多个 benchmark;一个 benchmark 接入一次,也可以评测多个模型。
这件事听起来不性感,但非常关键。
因为具身智能越往后走,单个 demo 的说服力会越来越弱。真正有价值的是可复现、可比较、可扩展的评测体系。否则每个团队都在自己的环境里说自己效果好,行业就很难形成真正的共识。
vla-eval 代表的是 VLA 进入“基础设施化评测”的阶段。未来模型发布时,大家可能不只看论文视频,而是看它能不能在统一评测系统里稳定跑过一组任务。

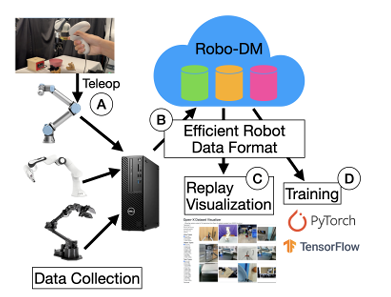
5.Robo-DM:机器人数据管理,可能是被低估的底座
最后一个项目是 Robo-DM。
很多人聊具身智能数据,第一反应是“数据量够不够大”。但真正做过机器人数据的人会知道,问题远不止数据量。
机器人数据非常麻烦。它不是简单的图文对,而是多相机视频、深度图、机器人状态、末端位姿、关节角、夹爪状态、语言指令、动作序列、时间戳等多模态数据的组合。不同传感器频率不同,不同设备格式不同,采集、压缩、传输、加载、回放都可能出问题。
Robo-DM 的价值就在这里:它把机器人轨迹数据当成一个需要专门管理的系统问题,而不是简单塞进文件夹。
它关注的是大规模机器人数据如何高效存储、共享和加载。对未来 VLA 训练来说,这可能是非常底层但非常重要的一环。因为当数据规模从几千条轨迹变成几十万、几百万条轨迹后,训练瓶颈不一定在模型,也可能在数据读取、视频解码、云端传输和时间同步上。
换句话说,机器人数据不是“有了就行”,而是要能被高效管理、稳定复用、快速加载。没有好的数据系统,再大的数据集也可能变成工程负担。
结语:具身智能的竞争,正在从模型走向系统
这五个项目放在一起看,会发现一个很明显的变化:
具身智能不再只是在卷单点能力,而是在补整套系统。
RLinf 解决的是后训练和交互学习的问题;FluxVLA 解决的是 VLA 工程闭环的问题;StarVLA 解决的是模块化研发的问题;vla-eval 解决的是统一评测的问题;Robo-DM 解决的是机器人数据管理的问题。
它们分别站在不同位置,但共同指向同一个趋势:
未来真正有壁垒的,可能不只是某个模型权重,而是一整套能持续产生模型、验证模型、部署模型、改进模型的基础设施。
VLA 让机器人开始具备“看懂指令并输出动作”的能力。但要让这种能力真正进入工厂、家庭、商业场景,还需要更扎实的系统底座。
具身智能的下一场竞争,可能不在单个 demo 里,而在这些看起来不那么耀眼、却决定模型能不能真正跑起来的 Infra 里。
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀










