点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
世界从来不是均匀展开的。有些瞬间决定一切,有些瞬间无关紧要。但今天的世界模型,却在用同一种节奏预测所有时刻。
固定频率的预测,让模型在大量无关紧要的瞬间反复“刷新”,却又频繁在帧与帧的"空隙"里,错过真正关键的事件。它们看似在预测未来,实则从未学会分辨什么值得被预测。
自变量机器人推出WALL-WM——首个具备"事件级预测能力"的世界模型,跳出"按时间均匀采样"的旧范式,模型不再机械地预测每一帧,而是判断哪些瞬间真正重要。
一个被忽视的根本问题
目前的行业中主流VLA几乎都在做同一件事:以视频或多模态基础模型为起点,直接预测固定长度的动作集合。
但自变量团队在WALL-WM中明确指出了这套范式的隐性代价——文本、视觉、动作根本不在同一个流形上。文本是低熵离散的语义意图,视觉是高维连续的观测流,动作则受物理与接触约束。三者既不共享"邻域",也不共享时间尺度,直接联合优化,会让继承自视频基础模型的基础能力在适配中被悄悄扭曲。
这就是为什么很多VLA在真机上的表现,远不如其底座VLM应有的水平,因为先验在迁移中被损耗了。
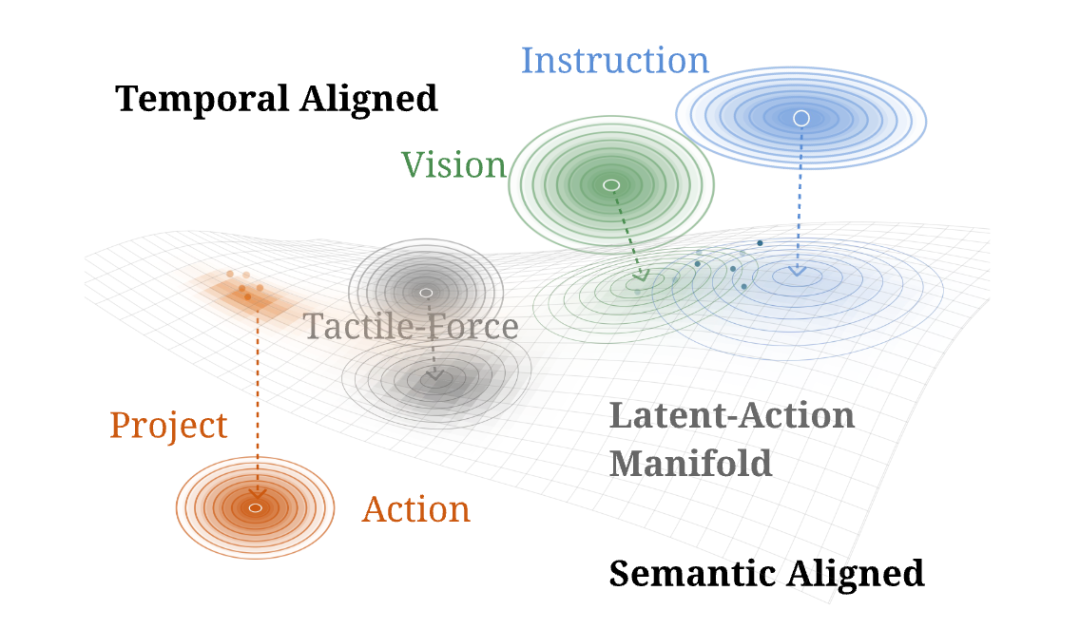
WALL-WM的底层范式革新:把"事件"作为对齐的原子单位
视频-动作学习的最小语义单元,到底应该是什么?
主流答案是"固定时间长度动作块",但动作块是时间上的人为定义,可能横跨"接近"与"接触"两个截然不同的物理阶段,模型被迫在歧义中学习。
Wall-WM的答案是Action-GroundedSemantic Event(以动作为中心的语义事件):伸手、抓取、提起、移动、放置,一段时间上连贯、可执行的行为片段。它可被语言精确描述、可被视频时序覆盖、可被动作轨迹执行,是连接三种模态的天然枢纽。
更关键的是,事件级世界预测让模型学到的不再是"指令 → 动作"的反应式映射,而是在此事件下,物理世界将如何演化、模型应当如何执行,这才是世界模型应有的形态。

从底层洞察到架构设计:三个关键动作
1、先验对齐的视频-动作联合去噪。
视觉模块承载互联网规模的视觉动态先验:动作模块随机初始化,与视频模块在每一层做单向耦合;跨视角融合分支的输出投影则零初始化,保证训练起步等价于原单视角先验。
动作流读取视觉语言表征,梯度不会反向污染视频先验。这套共享的隐空间,相当于一种宽度可调的隐式动作表示:无需事先猜测码本,通过大规模训练时同时达到“保持先验”与"动作能力持续增长"。这是绝大多数 VLA 在大规模训练时做不到的。

2、Multi-view attention用来让模型在多路相机之间交换信息,而不是把每个视角当作彼此独立的视频流处理。
具体来说,模型先保留Wan原有的单视角时空注意力,用它继承已有的视频生成先验;随后在每个DiT block中加入cross-view attention,把同一时间帧下来自不同相机的空间token放到一起做信息交互。这样既能利用多视角之间的几何互补性,又不会破坏预训练backbone的单视角能力。
训练时还会配合sight-cone mask约束跨视角token只在几何上可能共视的区域通信,从而减少无意义的跨相机混合。整体作用是提升多视角一致性、3D 感知和机器人操作场景中的遮挡鲁棒性。
几何感知的多视角融合。真实机器人通常配备头部 + 双腕多相机视角,朴素的跨视角注意力容易退化为"通用特征混合器"。Wall-WM提出了一对互补机制:视锥掩码与管状掩码
视锥掩码是基于相机标定的视锥相交关系,从拓扑层面禁止物理不可能的关联;
管状掩码随机掩盖某视角的时空管状区域,强迫模型经由其他视角恢复。
视锥掩码约束注意力能去哪,而管状掩码则逼迫它必须去。跨视角注意力由此从"欠拟合的潜在能力"锻造为"被频繁使用的几何对应关系"。配合可学习的相机旋转位置编码,天然支持多本体多视角的大规模训练。

3、StaircaseDecoding(阶梯式思维链解码)。
CoT能提升决策质量,但逐 token 解码太慢,机器人操作等不起。主流的Latent CoT把思考压成连续向量换速度,代价是再也看不到模型在想什么。WALL-WM的做法是底层只跑一次、高层像阶梯一样并行展开。
CoT仍是离散可读的文本(冻结LLM就能完整还原),但解码延迟大幅下降,原生兼容 KV-Cache,兼顾可解释性与实时性。

同一个基座,两种推理模式
WALL-WM 在同一套权重上支持两种部署模式,对应不同的使用场景:
事件模式(Event Mode):以"下一个事件描述"为条件,输出变长的动作块。适合上层已有规划器、能把任务拆成清晰子事件的场景。一次预测一个完整动作单元,自然贴合事件边界。
统一模式(Unified Mode):由视觉语言模型配合阶梯式思维链解码在线生成中间推理,并以固定长度的动作块为条件输出。适合没有外部规划器、需要恒定控制频率的端到端实时部署。
两种模式共享同一套权重,可在执行过程中按动作块逐段切换,无需任何重训。这意味着同一个模型,既能作为底层执行器配合高层规划器工作,也能脱离规划器独立跑完整闭环。部署形态由场景决定,而不是由模型决定。
数据与基础设施:事件级生态的系统性配套
金字塔式数据结构:最底层的是百万量级的网络通用视频,收窄人类操作类视频和第一人称公开数据,接下来逐层分别是UMI 风格的无本体采集(来自于自变量全自研的XRZero-G0无本体数采设备)、异构遥操作数据、几何一致的自采数据,而位于金字塔顶端的是事件级的接管与纠错数据。每一层都是对上一层某条约束的可控放松,越往上越贴近真机部署,越往下越接近开放世界的视觉先验。

数据map:训练数据组织为覆盖不同视角与动作可用性的 data-source map。数据来源包括通用互联网视频、第一人称/人类操作视频、UMI 风格的无本体采集数据(来自于自变量全自研的XRZero-G0无本体数采设备),以及异构遥操作和开放机器人数据。通用视频提供大规模视觉与时序动态先验;此外接管与纠错数据作为中心恢复数据源,用于补充接触密集区域和失败恢复行为,并可与多个来源组合采样。
四级层级化标注 + 双聚类采样:每条轨迹都在任务、子任务、动作、片段四个粒度上被标注。报告中有一个值得注意的发现:当文本描述按动作边界切分后,语言分布与视觉-语言联合分布都显著更均衡了。长尾的稀有指令-场景组合会被自然地暴露给训练采样器。这是事件级范式在数据工程层面的隐性收益,并非刻意为之。
分布式Muon 优化器+ FP8 部署:训练侧,团队把 Muon 优化器做了分布式改造,让它在大规模训练里的额外开销从"瓶颈"降到了可以忽略的水平,并将这套分布式实现命名为 DMuon;同时采用"多事件打包成一条序列"的方式喂数据,避免了传统按整条轨迹训练时、因为每条轨迹长短不一而不得不补一堆空白 token 的浪费。部署侧,通过 FP8 低精度量化加上分布匹配蒸馏,把扩散模型的推理延迟压进了机器人实时控制能接受的区间:训练更省、推理更快,两端同时打通。
实验:大规模真机泛化最佳
Embodied Video Generation:相比Wan2.1/Wan2.2,WALL-WM在 Motion Quality、Semantic Consistency、Physical Plausibility三个具身相关维度全面领先;

3D Awareness(CO3Dv2):在Point Error与Depth Error上优于WAN2.1-14B、Open-Sora 2.0、V-JEPA、DINOv2;

真机Core15 L1基准:基础任务、推理任务、灵巧操作、泛化场景下取得的任务完成分数,均显著超过π0.5、DreamZero,在抽象指令设定下是当前完成度最高的L1模型之一。

结语
WALL-WM 真正的价值,不在于又一个跑分更高的 VLA,而在于它把"如何在保留多模态先验几何的同时让模型学会预测世界"这个具身基础模型的根本问题,给出了一套自洽的工程化答案:
事件,不只是一个标注粒度,而是世界模型应有的思考单位。
GitHub:
https://github.com/X-Square-Robot/wall-x
项目主页:
https://x2robot.com/pages/wm
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀











