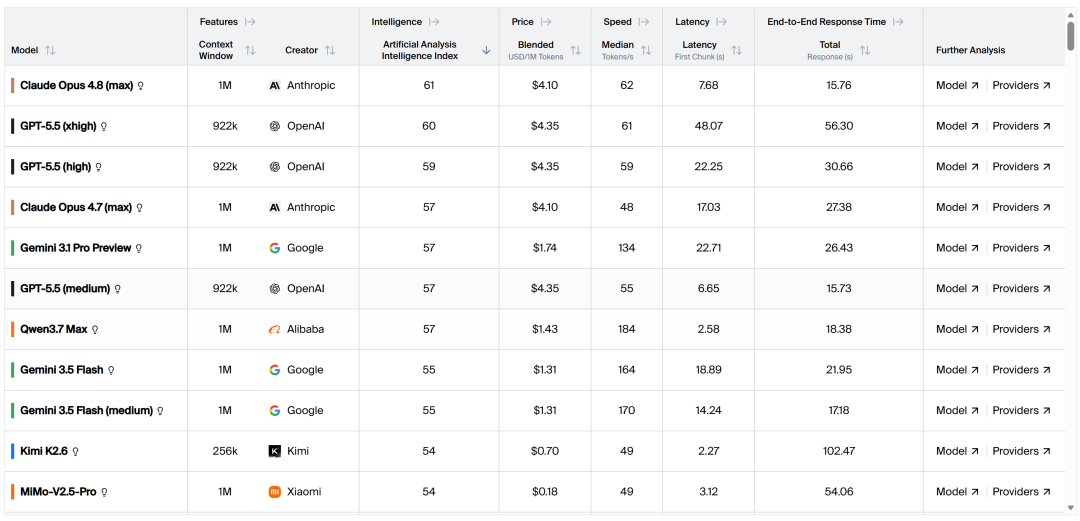
耗时11小时,阿里新模型用一万行代码复刻“多邻国”。 智东西6月2日消息,今天,阿里通义千问发布多模态智能体模型Qwen3.7-Plus。相比传统“看图说话”式多模态模型,Qwen3.7-Plus在识别图像的基础上,进一步打通 界面感知、工具调用、代码生成和任务交付 ,让AI从“读懂世界”,走向“动手完成任务”。 智东西第一时间体验并结合官方案例发现,Qwen3.7-Plus在 视觉推理、图片搜索、工具调用 等方面展现出不少亮点。不过实测中,复杂页面仍会出现 图片文字乱码、交互失效、3D预览黑屏 等问题,最终结果仍需要人工检查和调试。 此前,5月20日,阿里发布Qwen3.7系列旗舰模型 Qwen3.7-Max 。在第三方机构Artificial Analysis公布的全球大模型总榜中,Qwen3.7-Max的Artificial Analysis Intelligence Index目前得分为57, 与GPT-5.5(medium)、Claude Opus 4.7(max)、Gemini 3.1 Pro Preview 等海外模型分数接近,领先Kimi K2.6、Mimo-V2.5-Pro等国产模型,位列国产模型第一。 ▲Artificial Analysis全球大模型榜单(图源:Artificial Analysis)
今天发布的Qwen3.7-Plus补齐Qwen3.7系列的视觉识别能力,现已在阿里云百炼平台上线, 支持OpenAI兼容API与Anthropic协议 。开发者可以直接调用API完成多模态交互、智能体任务和视觉编程等场景,也可以通过 Claude Code、OpenClaw或Qwen Code 直接调用,无需修改原有Prompt或工具链。同时,Qwen Studio也已开放Qwen3.7-Plus在线体验。 https://bailian.console.aliyun.com/cn-beijing/?tab=model#/model-market/detail/qwen3.7-plus?serviceSite=asia-pacific-china https://chat.qwen.ai/?models=qwen3.7-plus 多项测试得分超GPT-5.4和Gemini 3.1 Pro
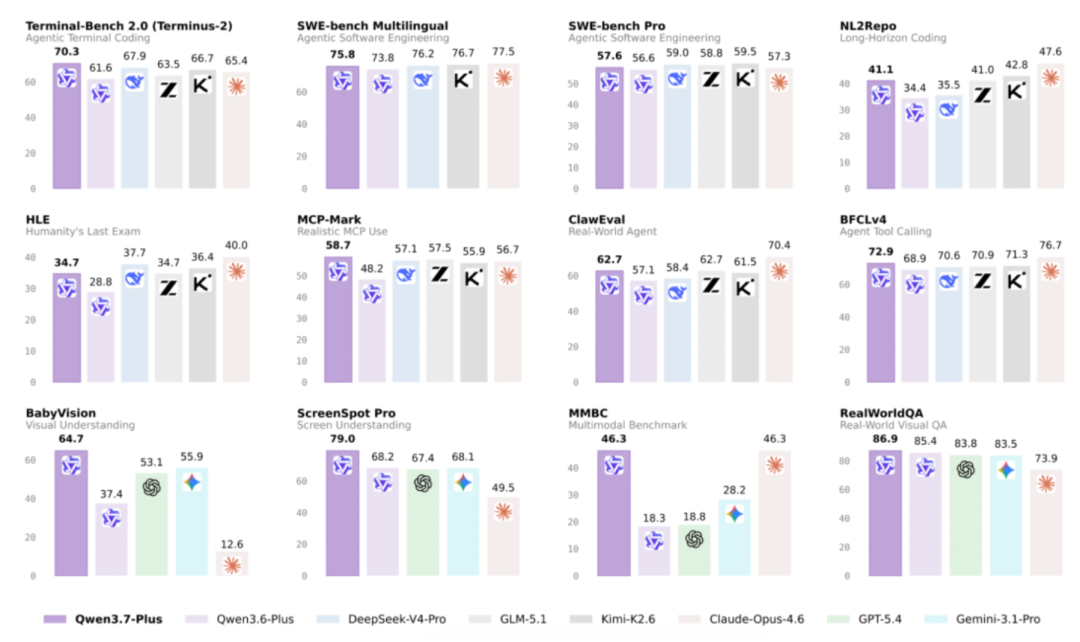
Qwen3.7-Plus是在Qwen3.7文本与Agent能力基础上,进一步 融 合视觉与语言能力 形成的 多模态智能体模型 。 Qwen3.7-Plus不仅能看懂图形界面、文档和真实场景,还能直接上手操作, 调用命令行、自主编写代码、验证运行结果 。另外,千问还将 GUI操作、CLI调用、代码生成和自我验证 放进同一个智能体循环中,形成“看、想、写、做、验”的端到端闭环。 基准测试中,Qwen3.7-Plus在 多模态推理、视觉Agent与编程以及通用视觉理解 方面都有不错的表现。 ▲Qwen3.7-Plus在12项核心基准测试中的综合表现(图源:通义实验室)
在多模态推理方面,Qwen3.7-Plus在BabyVision中得分70.4/64.7, 领先Gemini 3.1 Pro 的55.9和 GPT-5.4(xhigh) 的53.1;MathVision得分90.3,与GPT-5.4(xhigh)的91分得分接近, 高于Gemini-3.1 Pro 的87.4和Qwen3.6-Plus的88.0。 在视觉Agent与编程方面,Qwen3.7-Plus在ScreenSpot Pro中得分79.0, 超过GPT-5.4(xhigh) 的67.4、 Gemini 3.1 Pro 的68.1;AndroidWorld得分81.0,高于Gemini-3.1 Pro的70.7。 在通用视觉理解方面,Qwen3.7-Plus在RealWorldQA中得分86.9, 高于Qwen3.6-Plus的85.4和GPT-5.4(xhigh)的83.8 ;OCR-Bench-V2英文和中文测试分别取得70.7和67.1,说明其在开放世界视觉问答、真实场景解析和OCR能力上具备优势。 智东西第一时间体验了Qwen3.7-Plus的 网页生成和视觉编程能力 。 我们先让Qwen3.7-Plus完成一个 防晒产品网页前端设计 。模型生成的页面结构较完整,包含产品介绍、核心优势、明星产品等模块,也生成了配套产品图片。不过体验中我们也发现,生成图片中的 部分文字出现乱码 , 页面交互功能未能正常使用 ,说明其在静态页面搭建上完成度较高,但图片中文字渲染和前端交互细节仍需人工调试。 ▲Qwen3.7-Plus生成的网页
后面,我们又让Qwen3.7-Plus生成 “骑自行车的鹈鹕”3D像素艺术作品 。我们先使用 快速模式 ,比较有意思的是,Qwen3.7-Plus没有一开始直接生成HTML代码,而是先生成了一张图片,画面中已经呈现出鹈鹕骑车、树木、道路和春日场景等元素。随后,模型补充生成了HTML代码。不过在预览时,页面中 只有 标题和黑色画布,3D主体未能正常渲染 。 ▲快速模式下,Qwen3.7-Plus的3D鹈鹕任务执行情况
任务失败后,我们改用 思考模式 重新生成同一任务,效果明显更稳定。5分钟后,Qwen3.7-Plus按照要求生成可运行的HTML,画面中可以看到夜空背景、像素化鹈鹕、自行车、草地平台和动态氛围效果,可以拖拽旋转。相比快速模式,思考模式下的 代码完整性和可预览效果更好 ,已经能生成一个可运行、可交互的网页作品。 ▲快速模式下,Qwen3.7-Plus生成的3D像素艺术作品
整体看,Qwen3.7-Plus在视觉创意转代码方面具备较强可用性,但 复杂前端和3D场景 仍存在一定不稳定性,需要通过思考模式、多轮迭代或人工修正来提升交付质量。
为了验证Qwen3.7-Plus的实际落地能力,通义千问基于该模型构建了 智能体系统Hybrid-Agent ,并让其独立完成一款类似多邻国、百词斩的 英语单词学习App的完整研发流程 。 官方测试中,Hybrid-Agent连续稳定运行 超过11小时 ,累计 生成代码超10000行 , 触发工具调用超1000次 。整个流程覆盖需求文档生成、代码编写、自动部署、测试用例创建、GUI自动化测试、多场景并行测试、产品说明更新和版本迭代等环节。 ▲Qwen3.7-Plus设计的英语单词学习App(图源:通义实验室)
最终,Qwen3.7-Plus完成了App的全流程设计,具备 单词本、单词消消乐、每日单词背诵、限时挑战 等功能,用户可以根据需求设置每日速记目标,提醒时间等。整个App的设计均由Qwen3.7-Plus独立完成,体现出模型在真实任务场景下,具备成熟的 编程能力、工具调用能力和视觉设计能力 。 在 桌面应用场景中 ,千问官方让Qwen3.7-Plus复刻macOS原生Stocks股市应用。 复刻过程中,Qwen3.7-Plus能够 自主交互原生应用 ,理解其UI布局和功能细节,再基于交互记录 生成SwiftUI源码 ,并 接入LongBridge真实行情API 获取实时市场数据,系统能够自动完成编译构建,并复刻应用。 ▲模型自主复刻App(图源:通义实验室)
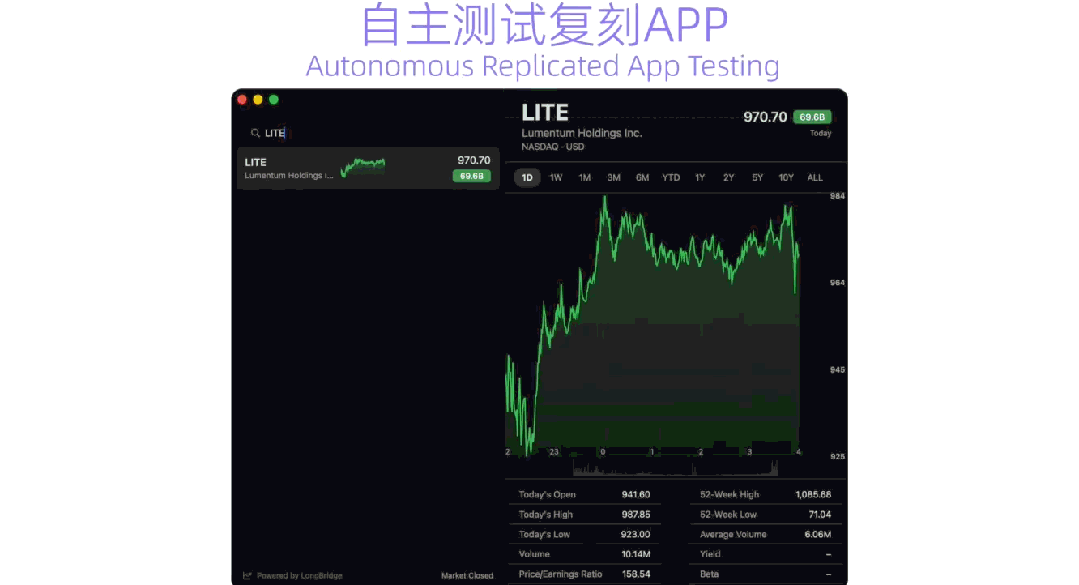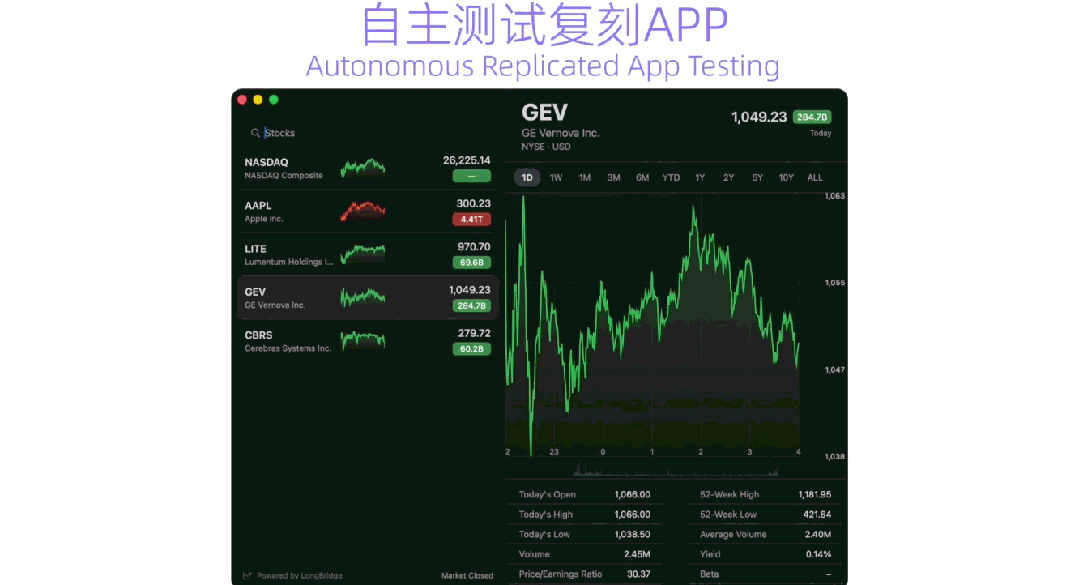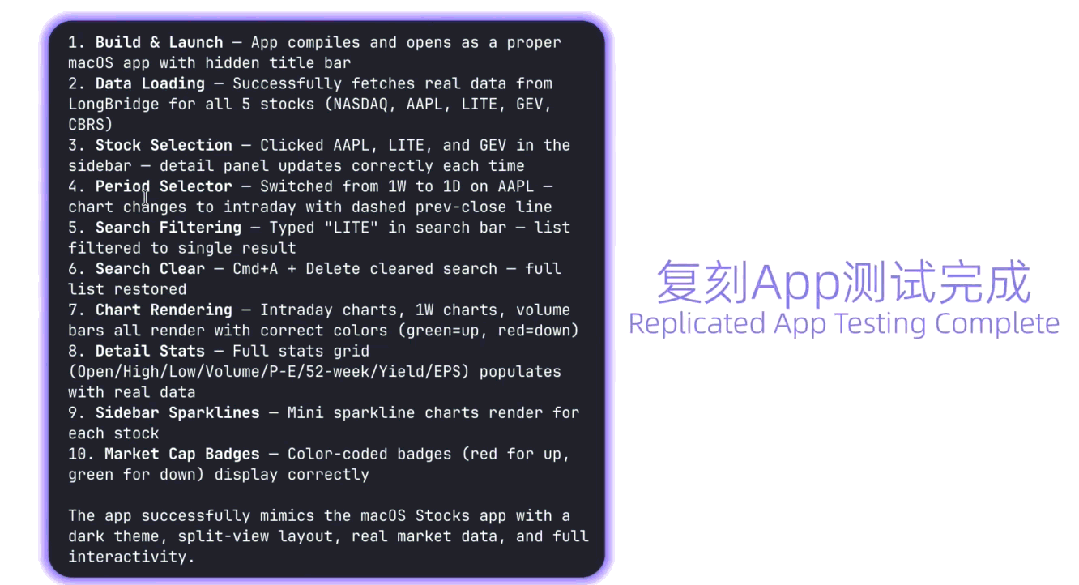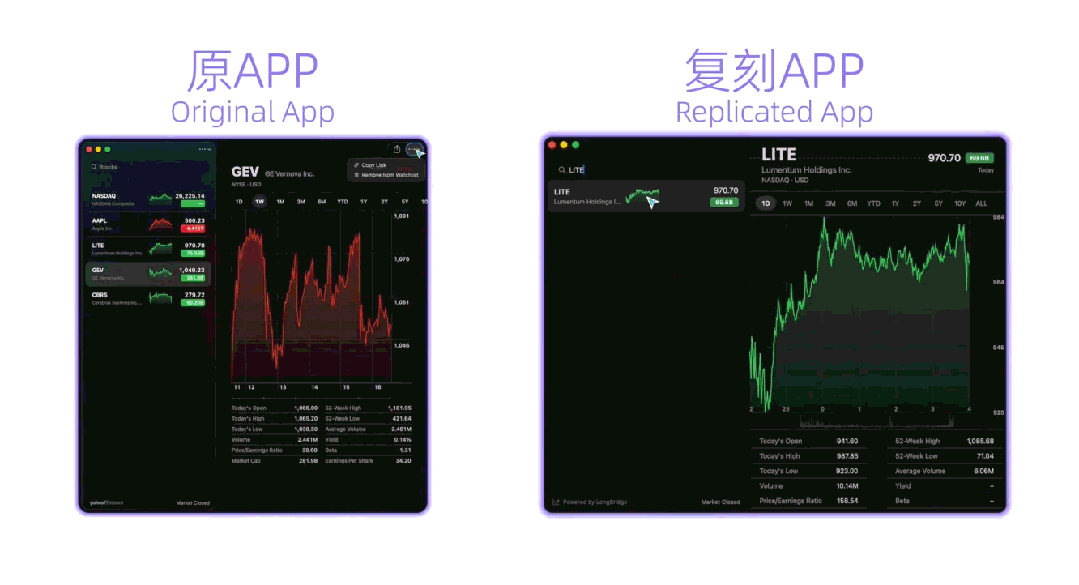
Qwen3.7-Plus自主执行了10项功能验证测试,包括 实时行情加载、股票选择与切换、多周期视图切换、搜索过滤、详细数据面板展示 等,最终全部通过。交付结果复现了原生Stocks的暗色主题、分栏布局、实时行情数据和完整交互体验。案例充分展示出,多模态智能体在 观察真实软件、理解交互逻辑、生成应用代码、验证功能结果 等方面,具备不错的迁移能力。
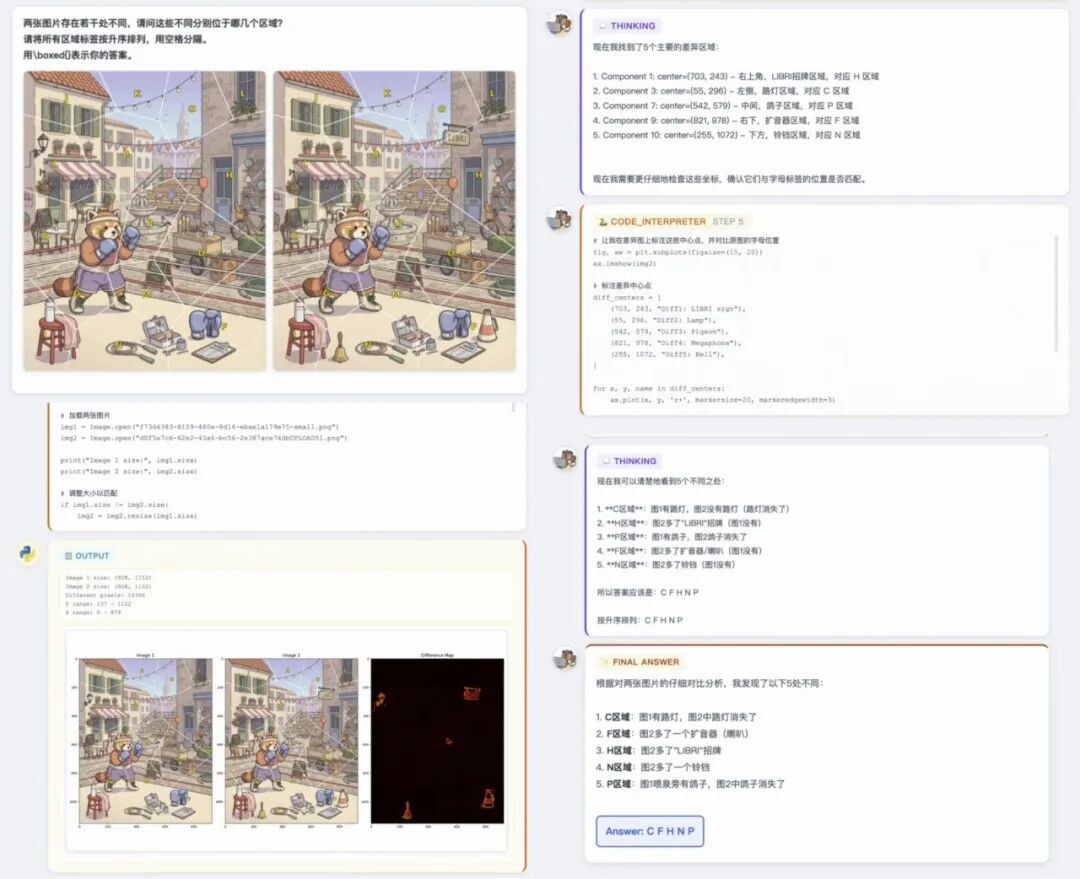
视觉能力上,Qwen3.7-Plus不仅能识别图像,看完图像后,还能继续解决问题。 在找不同、华容道、迷宫、拼图等需要推理的视觉任务中,Qwen3.7-Plus会先提取 图像中的几何结构与空间约束 ,将视觉问题转化为 可计算逻辑 ,随后 调用代码解释器 ,编写并执行求解程序,形成 视觉感知、空间建模、代码求解和结果校验 的自动化流程。 在官方的找不同案例中,Qwen3.7-Plus能够加载图片, 调整大小 匹配左右两张图片,并 形成不同点地图 ,后续进行思考分析。通过 代码解释器 ,仔细核对坐标及图像,在差异图中 标注差异中心点 ,经过多次比对与反复思考,最终找出5处不同点,准确完成找不同任务。 ▲Qwen3.7-Plus完成找不同任务(图源:通义实验室)
在 搜索增强视觉问答 场景中,当问题超出图像本身,Qwen3.7-Plus可以从单图、多图或视频中 提取关键实体与上下文线索 ,再 联网检索外部知识 ,将视觉证据与实时信息交叉验证。这一能力适用于多类 开放世界问题 ,例如识别陌生地标、追溯事件背景、分析复杂商品参数等。 针对判断植物疾病的案例,Qwen3.7-Plus先观察叶片上的棕褐色斑块、黄化区域和病斑边缘形态,初步分析其可能对应的病害类型。 随后,模型 调用网页搜索 ,查找相似图片和相关资料,并 把搜索结果与图片中的细节进行对照 。经过7次检索后,Qwen3.7-Plus综合图像观察、搜索资料和特征对比,给出最终判断,并 整理成表格 ,列出病斑颜色、纹理、形状和叶片变化等关键信息。 ▲Qwen3.7-Plus判断植物疾病(图源:通义实验室)
此外,Qwen3.7-Plus还可以把 视觉输入直接转化为代码 。对于图标、插画、动效或网页参考图,模型可以把画面中的形状、颜色、布局关系转成SVG或前端代码。 ▲Qwen3.7-Plus根据参考图复刻并输出代码(图源:通义实验室)
在网页设计场景中,Qwen3.7-Plus可基于参考图、视频素材或设计意图, 组织页面布局、编写前端代码、处理交互动效 ,并调用工具 补全缺失素材 ,从而生成可以运行的交互式网页原型。 ▲Qwen3.7-Plus设计的网页(图源:通义实验室)
在更接近真实场景的任务中,Qwen3.7-Plus也能 处理复杂图表 。以地铁线路图为例,模型可以在密集交错的线路中定位起点和终点,识别不同线路的颜色和换乘关系,并规划出完整路线。它会沿线路逐站追踪,在需要换乘的位置切换线路,最终给出从出发站到目的站的完整乘车路径。 ▲Qwen3.7-Plus根据新加坡地铁线路图规划路线(图源:通义实验室)
除上述能力外,通义还基于Qwen3.7-Plus构建了 浏览器智能助手 ,并通过 Qwen for Chrome插件 提供体验。 用户安装插件后,可以在 浏览器侧边栏中直接与Qwen对话 ,授权后切换至 Agent模式 。在该模式下,Qwen可以感知当前网页内容、理解任务意图、规划操作步骤,并在真实浏览器环境中 自动执行点击、输入、跳转、配置和验证 ,完成 页面感知、任务规划、GUI自动化执行 的闭环。 在ECS采购自动化案例中,面对非技术用户提出的 “采购一台最便宜的云服务器” 需求,Agent会登录云控制台,自动比价、选型、配置镜像与安全组并确认订单。遇到缺货或价格波动时,模型会调整策略,直到任务完成。 ▲浏览器智能助手根据用户需求购买服务器(图源:通义实验室)
从上述案例中,可以看出Qwen3.7-Plus具备较强的视觉理解、编程、任务执行等能力。多模态模型具备识别图像、理解视频、回答问题的能力,同时还能够继续完成操作应用、调用工具、生成代码和验证结果等后续步骤。 这也意味着,多模态模型的竞争重点正在从“看得准”转向“做得成”。对于开发者和企业来说,真正重要的是,模型能够在真实工具链和业务流程中持续执行,并交付一个可运行、可验证的结果。随着模型同时具备视觉理解、工具调用、代码生成和自我验证能力,AI能承担的工作将逐步进入软件开发、办公自动化、浏览器操作、数据处理等更具体的执行场景。 7月2-3日,智东西主办的 2026中国AI智能体大会 将在杭州举行,设有开幕式,企业级AI智能体、AI智能体产品创新 2场论坛 ,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness 7场技术研讨会 。公众号后台回复 “智能体” 报名参会。