点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
这一期 Awesome Work,我不想继续只推荐“又一个 VLA 论文列表”。这一周 GitHub 上更值得看的,是三个更像基础设施的资料项目:
Everloom-129 / Awesome-Memory-for-Robotics AIDASLab / Awesome-VLA-Data-Collection-Synthesis-Curation Noietch / Awesome-Learning-for-Manipulation
它们分别指向三个问题:机器人为什么需要记忆?VLA 的数据到底该怎么规模化?机器人操作学习该如何把 VLA、世界模型、仿真和 benchmark 串起来?
这三个问题,比“谁的模型更大”更接近真实落地。
一、Awesome-Memory-for-Robotics:机器人不是没有大脑,而是缺少连续经验
项目链接
GitHub: https://github.com/Everloom-129/Awesome-Memory-for-Robotics
这个仓库的主题非常明确:机器人记忆。它不是泛泛地整理 LLM memory,也不是做一个智能体记忆资料库,而是把范围限定在 robotics + memory。也就是说,它关心的是机器人如何存储、检索和利用过去经验,从而改进感知、规划和决策。

为什么这个项目值得关注?
现在很多 VLA 模型,本质上还是短上下文模型。它看到当前图像、当前语言指令、当前本体状态,然后输出一段动作。这个范式适合短任务,比如拿起杯子、推开抽屉、把积木放进盒子。但一旦任务变长,问题就来了。
比如,机器人上午已经看过杯子被放进柜子,下午用户说“把刚才那个杯子拿出来”。如果模型没有记忆,它只能重新搜索;如果环境有遮挡,它甚至不知道该去哪里找。再比如,机器人在整理桌面时,前面已经尝试过一次抓取失败,知道某个物体很滑、某个角度不好抓。如果没有经验记忆,下一次它可能还会犯同样的错。
更典型的是家庭和商超场景。场景不是每一秒都从零开始的。货架位置、物体分布、用户习惯、空间结构、历史失败、任务进度,这些信息都应该被机器人记住。没有记忆,机器人就是一个每次开机都“失忆”的执行器。
这个仓库把机器人记忆拆成了多个方向:上下文记忆、情景记忆、语义记忆、长期记忆,以及面向操作、导航、移动操作、空间场景、世界模型的记忆机制。这个分类很有启发性,因为机器人需要的记忆不是一种。
上下文记忆解决的是当前任务状态:我现在做到哪一步了,刚刚执行了什么,下一步应该接着做什么。 情景记忆更像经验回放:某一次抓取为什么失败,某个场景下什么策略有效。 语义记忆保存的是稳定知识:杯子通常在柜子里,遥控器通常在沙发附近。 空间记忆则和导航、3D 场景理解、物体定位有关:机器人需要知道“东西在哪里”,而不是每次重新感知整个世界。
这个方向很可能会成为 VLA 之后的一个重要补丁。因为很多真实任务失败,不是模型看不懂,也不是动作生成不出来,而是模型缺少跨时间的信息积累。它不知道过去发生了什么,不知道自己试过什么,也不知道环境中哪些东西是稳定的、哪些东西是刚刚变化的。
如果说 VLA 让机器人开始具备“看懂并行动”的能力,那么 memory 可能会让机器人具备“积累经验再行动”的能力。这也是为什么本周我把这个仓库放在第一位——它不是最热闹的,但它点到了具身智能真正走向长程任务时绕不开的问题。
二、Awesome-VLA-Data-Collection-Synthesis-Curation:VLA 的瓶颈,越来越像数据工程问题
项目链接
GitHub: https://github.com/AIDASLab/Awesome-VLA-Data-Collection-Synthesis-Curation
这个仓库很适合做工程团队的资料入口。它关心的不是单个 VLA 模型,而是 VLA 背后的 数据引擎:数据采集、数据合成、数据增强、数据清洗、预处理、benchmark,以及面向机器人基础模型的数据组织方法。
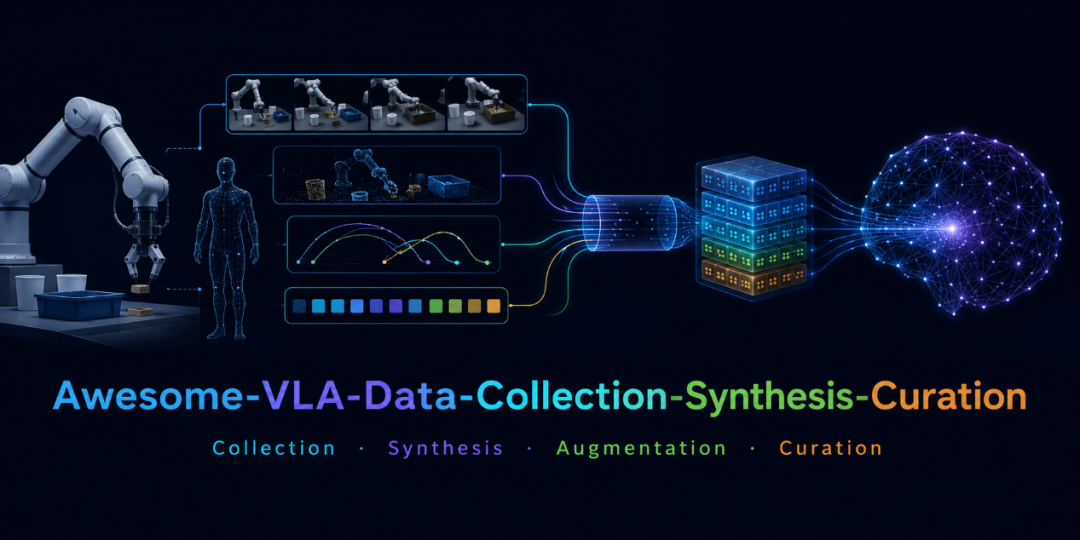
为什么这个项目值得关注?
VLA 发展到现在,瓶颈已经不只是模型结构了。过去我们讨论机器人学习,经常说“多采点数据”。但到 VLA 阶段,“多采点”已经不够了。因为数据问题变得更复杂:
不同机器人本体的数据能不能混用? 不同相机视角的数据怎么对齐? 语言指令是不是过于模板化? 失败数据要不要保留? 仿真数据和真机数据怎么配比? 合成数据会不会引入偏差? 一个数据集到底覆盖了多少物体、多少场景、多少动作模式? 数据质量差,是不是比数据量少更致命?
这些问题都不是模型论文里一句“we collect a dataset”就能解决的。VLA 数据和普通视觉数据不一样。它不是一张图配一个标签,而是一段时间序列,里面有图像、语言、动作、本体状态、任务阶段、环境变化,甚至还包含失败、暂停、纠正和人工干预。数据本身就是一个小型系统。
AIDASLab 这个仓库的意义,是把 VLA 数据看成一个完整生命周期,而不是一个下载链接。
从采集开始,就要考虑遥操作方式、机器人平台、任务设计、相机布局、动作频率和数据格式。 到合成阶段,要考虑仿真、数字孪生、跨本体增强、轨迹生成和世界模型 rollout。 到清洗阶段,要做去重、过滤、对齐、标注、质量评估。 最后还要进入 benchmark,看这些数据到底能不能提升策略泛化。
这件事对真实团队很重要。因为很多机器人项目做不起来,不是因为不知道该用什么模型,而是数据从一开始就没有组织好。采集时没有统一任务模板,动作频率不一致,相机标定混乱,语言指令随便写,失败样本不知道怎么处理,最后训练时发现数据全是噪声。
VLA 的工程能力,首先体现在数据能力上。未来的具身智能团队,很可能会出现一种新分工:有人负责模型,有人负责控制,有人负责仿真,还有一批人专门负责数据引擎。数据引擎不是简单的“采集脚本”,而是一整套系统:任务设计、采集规范、数据质检、可视化审核、自动标注、仿真补充、版本管理和训练对接。
这个仓库代表的是一个很现实的趋势:具身智能不再只是模型竞赛,正在变成数据工程竞赛。谁能更快、更稳定、更低成本地组织高质量机器人数据,谁就更容易把 VLA 真正跑到业务场景里。
三、Awesome-Learning-for-Manipulation:机器人操作仍然是具身智能最硬的考场
项目链接
GitHub: https://github.com/Noietch/Awesome-Learning-for-Manipulation
这个仓库的定位是 learning-based robot manipulation,也就是学习型机器人操作。它覆盖 VLA、video-action models、visuomotor policies、world models、simulators、benchmarks、robot datasets 和一些产业技术报告。
为什么这个项目值得关注?
不管 VLA 和 WAM 概念怎么变,机器人最终还是要落到操作任务上。拿东西、放东西、插入、拧开、折叠、整理、分拣、装配、上下料,这些任务看起来日常,但对机器人来说一点都不简单。它们要求模型同时处理视觉、语言、接触、几何、时序和控制误差。一个操作任务失败,可能不是某一个模块错,而是感知、规划、动作、夹爪、物体状态共同造成的。
所以 manipulation 一直是具身智能最硬的考场。
导航可以靠地图和规划分担很多压力;纯视觉问答可以不真正改变世界;仿真任务可以规避许多复杂接触。但操作任务不行。机械臂一旦伸出去,就要和真实物体发生接触。物体会滑,会歪,会挡住视线,会因为摩擦和重力产生非线性变化。这个时候,模型是不是“懂世界”,很快就会暴露。
这个仓库的好处,是它把几条路线放在同一个操作语境下看:
VLA 解决语言、视觉和动作的统一接口。 Video-Action Models 试图从视频中学习动作和未来变化。 Visuomotor policies 更强调从视觉到低层控制的直接映射。 World Models 关注动作之后的环境演化。 Simulators 和 Data Engines 解决训练环境和数据规模问题。 Benchmarks 则提供一个最低限度的比较标准。
这些方向单独看都很热,但如果脱离 manipulation,就容易变成概念。放到操作任务里,问题会变得非常具体:模型能不能抓住?能不能放准?能不能处理遮挡?能不能泛化到新物体?能不能在失败后恢复?能不能在真机上保持稳定节拍?
对于内容创作来说,这个仓库很适合作为长期坐标系。因为它不会只盯一个短期热点,而是围绕“机器人如何学会操作”这个核心问题不断扩展。当某个新模型出来时,我们可以回到这个 manipulation 框架里判断它到底解决了什么问题:是语言泛化?是动作表示?是长程任务?是接触鲁棒性?是真机部署?还是只是换了一个 benchmark 刷分?有了这个坐标系,写文章就不容易被新名词牵着走。
四、本周最值得关注的新基础设施
如果只用一句话总结本周 GitHub 上的具身智能 Awesome Work,我会说:具身智能开始从“模型更大”转向“系统更完整”。
Awesome-Memory-for-Robotics 提醒我们,机器人不能一直失忆。
Awesome-VLA-Data-Collection-Synthesis-Curation 提醒我们,VLA 的核心资产是数据引擎。
Awesome-Learning-for-Manipulation 提醒我们,再漂亮的模型,最终都要回到操作任务里接受检验。
这三个项目不一定是 star 最高的,也不一定是传播最广的,但它们选题很准。它们抓住的不是表层热点,而是具身智能继续往前走必须补齐的几块拼图。
如果你是研究者,可以把它们当作阅读入口。如果你是工程团队,可以把它们当作系统设计参考。如果你是在做具身智能内容,它们很适合作为后续选题池。
下一阶段,VLA 和 WAM 当然还会继续发展。但真正能拉开差距的,可能不只是模型结构,而是谁能把记忆、数据、操作、仿真、评测和部署串成闭环。机器人要进入真实世界,靠的不是一个模型名字,而是一整套能持续学习、持续修正、持续稳定工作的系统。
这可能才是本周这三个 GitHub 项目最值得看的地方。
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀