
在刚刚落幕的 COMPUTEX 2026 上,NVIDIA RTX Spark PC 芯片的亮相,让全球半导体产业的架构之争再度白热化。此前,业界对Arm提出的“短期内占据PC市场50%份额”的目标还持观望态度;而今,在一系列硬核硬件的密集轰炸下,这一目标已近在咫尺。
紧接着在6月5日,Arm在北京召开边缘AI媒体沟通会。Arm边缘AI事业部执行副总裁 Chris Bergey不仅深度解构了这场由Arm携手产业巨头引发的行业巨震,更向外界剖析了 Arm攻占PC市场的底层逻辑:这绝非一次简单的架构替代,而是一场由智能体 AI(Agentic AI)倒逼的“全面变革”。

Arm边缘AI事业部执行副总裁 Chris Bergey
智能体时代降临:PC迎来久违的底层重构
在过去数十年里,PC行业的演进遵循着高度稳定的线性规律:入门级产品追求价格,高端产品堆叠主频、核心数量与散热能力。虽然不同价位段性能有别,但“用户主动输入指令 ->硬件单次响应”的传统计算范式从未改变。
然而,智能体AI的兴起正在彻底重构PC的定义。Chris Bergey指出,未来的PC将分化为两大截然不同的品类。
一类是极致便携、随时在线的传统PC升级版(如Windows on Arm阵营与Googlebook);
另一类则是便携性偏弱,但可7×24小时在办公室或家中持续运转的“智能体专用硬件平台”。
“未来的PC不再只是一个工具,而是一个全时段处于算力输出状态的‘本地词元(Token)生成引擎’。” Chris Bergey表示。即使在用户离开屏幕后,智能体依然可以不知疲倦地调用本地数据、并发处理多项复杂任务,且无需缴纳高昂的云端服务费。
这种全天候、高吞吐的混合AI工作负载,对硬件的“算力密度”与“能效比”提出了极其苛刻的要求。这让传统x86架构在热设计功耗(TDP)上的劣势暴露无遗,却恰恰是Arm的绝对主场。
RTX Spark亮剑:统一内存架构击碎端侧带宽瓶颈
在这场重构中,由NVIDIA、Arm、联发科三方联合研发的 RTX Spark 平台,无疑成为了证明Arm架构技术领先性的标杆级作品。

作为一款原生适配Arm架构、完整支持Windows系统的突破性芯片,RTX Spark堪称边缘高性能异构计算的怪兽级方案:
极致的核心密度:它搭载了多达20颗独立Arm处理器内核,是目前同类PC平台中CPU核心配置最多的产品,能够为多智能体并行提供强大的调度保障。
颠覆性的统一内存架构(UMA): 针对业界普遍担心的端侧大模型带宽瓶颈,Chris Bergey在现场给出了极其关键的技术澄清:“RTX Spark实际采用的是LPDDR5X,而非高昂且容量受限的GDDR6。其核心价值在于CPU和GPU能够完整共享、调用全部DRAM及带宽资源。”
由于抛弃了PCIe或CXL等传统传输接口,这种紧密耦合从根本上消除了数据中转的延迟与带宽瓶颈。它用无可辩驳的实测表现证明:在AI工作负载远超常规游戏GPU标配显存的今天,Arm架构能够以更高的性价比,在边缘端轻松驾驭高吞吐的大模型运行。目前,该芯片已获得多家头部PC厂商采用,下半年将迎来终端产品的全面爆发。
从IP、CSS到AGI芯片:商业模式的全面升级
RTX Spark的成功并非偶然,其背后是Arm商业模式正在发生的深刻蜕变——从单纯的IP及计算子系统(CSS)业务授权,向全面赋能乃至下场造芯进行升维。
此前,RTX Spark正是基于Arm第一代 CSS for PC平台打造,而目前第二代CSS for PC方案已交付合作伙伴。这种平台化的计算子系统,极大地降低了OEM和芯片厂商将分散IP集成到完整系统中的难度与周期。

更具里程碑意义的是,在今年三月的Arm Everywhere大会上,Arm首次推出了首款面向云端智能体场景的量产芯片产品——Arm AGI CPU。
“长期以来,全球超大规模云服务商都在基于Arm IP构建云端CPU。随着合作深入,部分客户提出‘直接采购Arm芯片’的强劲需求,Arm AGI CPU便顺理成章地诞生了。” Chris Bergey强调,“Arm是一家客户需求驱动的公司。在当前阶段,面向云端智能体场景的AGI CPU,是我们在芯片领域的独特发展机遇。”
从定制化的IP,到高度集成的CSS platform,再到亲自试水云端AGI芯片,Arm正在构建一条全栈式的算力护城河。这种在系统集成、算力密度和高能效异构计算上的体系化能力,吸引了包括中国市场OEM厂商在内的大批企业探索自研芯片布局。
软硬件生态协同:Windows on Arm的机会窗口彻底打开
硬件架构再先进,也必须依靠繁荣的生态才能最终落地。过去,Windows on Arm(WoA)曾因“原生应用少、依赖x86迁移”而饱受生态质疑。但在今天,这一历史枷锁正在被砸碎。
Chris Bergey在沟通会上分享了一组微软的遥测数据:早在一年前,WoA用户超九成的使用时长就已经在Arm原生应用上运行。过去一年中,Arm原生应用更是迎来了爆发式增长。
导致这一逆袭的核心逻辑在于:微软、谷歌等科技巨头在定义新一代操作系统(如Copilot+ PC)和AI生态(如Gemini)时,已经将Arm平台提到了绝对优先的战略高度。
目前,Windows on Arm的生态攻势正从两个方向全速推进:
一方面是终端阵营的全面合围:宏碁Aspire、微软Surface、谷歌Googlebook以及苹果MacBook Neo(成功将高端Arm体验下探至6000元人民币以内)共同构成了坚实的硬件载体。
另一方面是开发者工具链的无缝破局:在Microsoft Build开发者大会上,Arm主导并联合微软发布了 Arm AppReady for Windows 项目。该项目通过引入AI赋能的工具和专家支持,极大地降低了开发者迁移的复杂度。
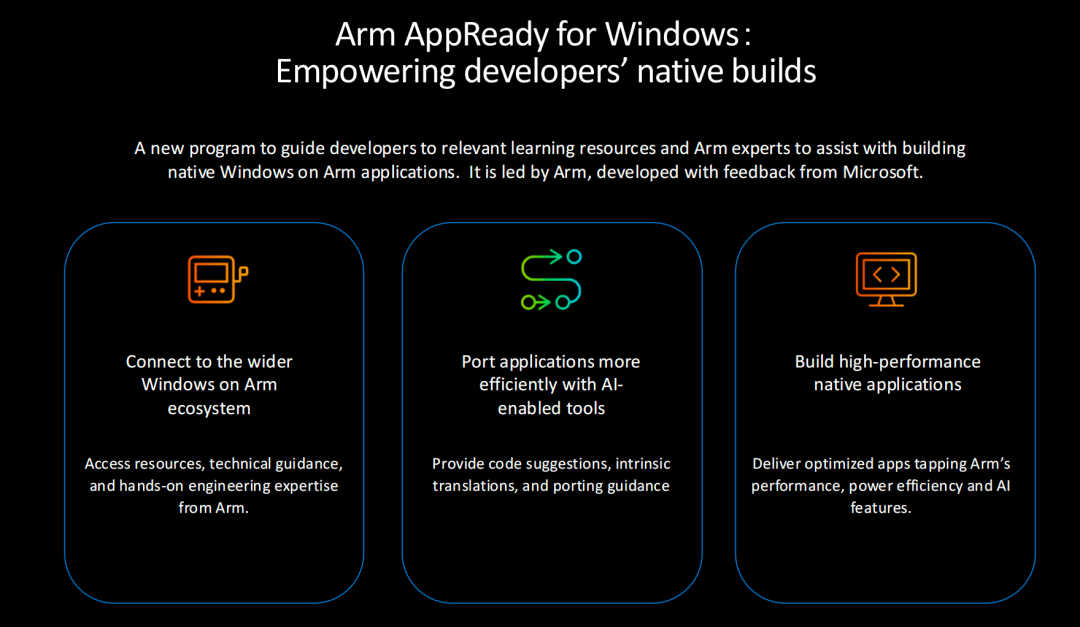
更宏大的趋势在于跨Arm平台的规模效应。如今,开发者只需开发一套软件,就能同时兼容iOS、Windows on Arm和Linux。尤其是天然诞生于新架构、新工具链之上的智能体应用,正优先选择Arm作为首发和主运行平台,传统x86的软件壁垒正在加速瓦解。
边缘AI内涵泛化:中国市场成为创新的风向标
在这场全球算力重构的版图中,中国市场因其庞大的制造能力、丰富的应用场景和敏锐的创新嗅觉,正成为Arm边缘AI落地的重要市场。
在端侧智能体硬件层面,本土厂商此芯科技与Arm紧密合作推出的 CIX Claw Station 平台,成为了极具代表性的行业案例。该平台面向开发者和本地AI场景,正在积极探索一种介于传统PC、工作站和AI开发平台之间的新型终端形态。目前,基于OpenClaw开源生态,联想、MetaComputing等十余家头部行业合作伙伴已纷纷加大投入, 进一步推进 CIX Claw Station 平台在智能体计算时代的发展。
与此同时,中国市场也正在向外界证明:边缘AI的内涵正在变得越来越宽,全面扩散至图形、游戏、摄像头及可穿戴设备等各个层面。
一个瞩目的案例便是腾讯游戏最新发布的全球首个跨平台神经动态全局光照方案——MagicDawn NDGI。该方案利用 AI 神经网络实时还原电影级动态光影,同时大幅降低了传统渲染的性能消耗。为了释放移动端潜力,MagicDawn已与Arm达成战略合作,深度适配2026最新一代Arm GPU及其内置的先进AI加速器。
“AI已经从一个单点功能变成了系统级的工作负载。因此,系统内的每一类计算单元(CPU、GPU、专用加速器),都要尽可能强化AI任务的运行能力。”Chris Bergey重申了Arm始终坚持的异构计算思路。
结语
过去,行业谈及Arm进入PC,往往习惯将其框定在“挑战x86”的旧叙事里,关注兼容性与软件补丁。但在智能体时代,这场竞争的内涵已经发生了根本性重塑。过去,PC的核心是运行软件;未来,PC的核心是运行智能体。
随着全天候智能体硬件和颠覆性计算平台的密集落地,计算产业的定义权正悄然易主。未来已来,x86统治PC的旧秩序,正被Arm以算力密度与低功耗的重锤,砸出一道巨大的裂口。
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~![]()











