01
前言
半导体行业过去数十年依靠摩尔定律驱动晶体管尺寸持续萎缩,实现了性能、功耗与密度(PPA)的指数级提升。然而,进入纳米时代后,这一经验规律面临严峻挑战。物理层面,特征尺寸逼近原子尺度,量子效应、漏电流与散热墙问题日益突出。经济层面,先进节点晶圆厂投资已超过200亿美元,EUV光刻与多重曝光工艺复杂度极高但效率不高,大尺寸芯片良率不及预期,单纯几何缩放的回报显著递减。
 半导体制造路线图(IMEC)
半导体制造路线图(IMEC)
在此背景下,全球产业演进趋势从“More Moore”转向“More than Moore”与系统级微缩,Chiplet架构、异构集成与先进封装逐渐演进为主流思路。这些进展直接为逻辑折叠技术创造条件。特别对于中国,在缺少EUV光刻机支持的背景下,逻辑折叠是传统数字芯片性能演进的关键路线。
通过垂直堆叠多层有源硅,关键路径可在物理上“折叠”,大幅缩短水平走线、降低RC延迟与时钟偏斜,同时缓解内存墙。与此同时,时序逻辑折叠则通过可重构硬件实现资源的时间复用,为架构提供运行时灵活性。某家最近提倡的LogicFolding架构,正是这一国际趋势的积极表率。
 半导体封装/集成路线图
半导体封装/集成路线图
本文系统梳理逻辑折叠的技术本质、两种实现方式、关键使能技术、行业实践案例(包括麒麟系列、鲲鹏系列等平台的探索)以及对芯片架构的影响,主要玩家,方便大家了解这一产业趋势和本质。
02
逻辑折叠的核心概念与分类
在国际半导体行业从单纯晶体管缩放转向系统级Scaling的演进中,逻辑折叠成为应对摩尔定律瓶颈的架构/电路手段。
逻辑折叠是通过时间或空间维度的硬件资源复用、折叠与重构,在单位面积实现更高性能的架构和电路技术。逻辑折叠可以在无需光刻线条微缩的情况下,在芯片产品的性能、功耗和面积实现协同优化。
与单纯的3D堆叠不同,逻辑折叠包括了时间逻辑折叠(时域复用)和空间逻辑折叠(3D堆叠)两个含义。二者可独立或混合使用,适应当前Chiplet与3D异构集成的产业趋势。
时序逻辑折叠(Temporal Logic Folding)
时序逻辑折叠将组合逻辑图划分为多个层次,在不同时钟周期内动态重构同一套硬件资源,依次实现各层功能,以时间换取面积。其典型特征是资源共享与调度驱动的时域复用(Temporal Multiplexing)。硬件在每个周期仅实现当前层次的逻辑,下一周期通过快速配置切换功能,从而大幅降低所需逻辑单元数量。
与时序逻辑折叠对应动态可重构技术近年取得显著进展。学术界早期NATURE架构通过细粒度动态重构与时序逻辑折叠,在65nm工艺下实现逻辑密度提升一个数量级以上,面积-延迟积改善约3.48倍。UIUC的FReaC Cache,进一步将逻辑折叠嵌入最后一级缓存,构建近存可重构计算Fabric,验证了其在资源受限场景下的实用性。
在缺少先进工艺支持的情况下,这一技术特别适合AI加速器场景。LLM工作负载包含GEMM、Attention、稀疏操作等多种算子,时序逻辑折叠可提升阵列资源利用率,增强对演进中工作负载的适应性。
空间逻辑折叠(Spatial Logic Folding)
空间逻辑折叠主要借助单片3D集成或先进垂直堆叠技术,将逻辑门电路与功能块分布到多层有源硅层,通过高密度垂直互连实现关键路径的物理“折叠”。直接缩短水平走线长度,降低RC寄生延迟与时钟偏斜,同时支持逻辑与存储的紧密垂直集成。
在国际产业从2D平面布局向3D异构集成演进的趋势下,3D集成/空间逻辑折叠成为缓解互连瓶颈与内存墙的有效路径。通过将时序关键路径分布至不同有源层,设计者可在固定工艺节点下实现更高晶体管密度与更低功耗。
时序与空间逻辑折叠并非相互排斥。混合使用已在可重构AI芯片与异构计算平台中显现潜力。前者提供运行时灵活性,后者提供物理密度优势,二者共同服务于后摩尔时代PPA优化目标。
采用逻辑折叠技术的芯片

03
时序逻辑折叠的关键技术
时序逻辑折叠通过周期级动态重构实现硬件资源的时间复用,是应对后摩尔时代面积效率需求的技术之一。其关键技术集中在细粒度动态重构硬件平台、高速配置分发与资源共享机制,以及映射与优化工具链三个层面。
3.1 细粒度动态重构硬件
细粒度动态重构硬件平台是实现周期级或近周期级重构的基础,要求逻辑单元支持快速功能切换,同时最小化全局路由开销。典型设计采用本地化配置存储与分布式内存结构,避免传统岛式FPGA中长距离路由带来的延迟与功耗。
例如早些年的NATURE架构采用同质可重构逻辑单元,将动态重构延迟隐藏在正常计算延迟之后,可灵活配置为逻辑或互连功能,并集成基于10T低功耗SRAM的分布式配置存储。并使用Folding Schedule算法将组合逻辑图划分为多个层次,每个周期仅激活当前层次所需资源,实现严格的temporal multiplexing。与传统岛式FPGA相比,NATURE通过细粒度设计,在65nm工艺下将全局路由资源需求大幅降低,逻辑密度提升超过一个数量级。
FReaC Cache则进一步验证了动态可重构资源共享机制的有效性。该工作将逻辑折叠嵌入最后一级缓存,利用现有密集SRAM阵列构建可重构fabric,变化最小却实现了近存计算加速,在数据密集型应用中展现出更低的访存开销和更高的资源复用效率。

FReaC Cache的逻辑折叠
3.2 映射与优化工具链
映射与优化工具链是逻辑折叠落地的关键,需将数据路径展开(Unrolling)与逻辑折叠进行协同优化,以降低面积-延迟积。
传统FPGA映射工具(如Vivado)流程主要优化空间布局与时序收敛,缺乏对时间维度复用的支持,导致资源冗余。
逻辑折叠的映射与优化工具链需工具链需自动完成逻辑图的分层划分、自动生成Folding Schedule,并评估多层次划分对整体PPA的影响。
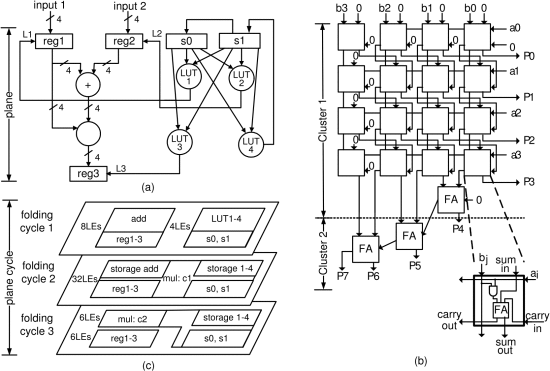
NanoMap的时间逻辑折叠优化
NanoMap集成设计优化流程对数据路径进行自动展开,然后结合时序逻辑折叠的层次划分,自动探索最优的Folding配置,在用户指定的面积或延迟约束下生成映射结果。通过这种自动展开与折叠协同优化,相比仅进行空间映射的传统方法,采用自动展开结合时序逻辑折叠的优化方法,在FPGA类实现中可实现关键路径延迟降低约20%,面积-延迟积改善约39%。
04
空间/垂直逻辑折叠的关键使能技术
空间逻辑折叠依赖单片3D集成与先进垂直互连技术,将逻辑在物理空间上进行“折叠”,直接缩短关键路径并提升密度。近年来,异质键合(Hybrid Bonding)以及单片CFET工艺的快速进展,为这一技术提供了坚实的工艺与互连基础。
4.1 单片3D集成与垂直有源层堆叠工艺
单片3D集成通过顺序或并行制造多层有源硅,配合超细间距垂直互连实现逻辑层的垂直堆叠。核心工艺包括低温晶体管制造、层间介质隔离以及高密度垂直通孔(Monolithic Inter-tier Vias,MIV)或Hybrid Bonding。
IMEC团队在IEDM 2024和VLSI 2024/2025发表的多篇工作系统展示了单片CFET(mCFET)的工艺进展,包括背面接触与混合沟道集成,验证了从底层PMOS到顶层NMOS的垂直堆叠可行性。与传统TSV-based 3D Stacking相比,单片工艺的垂直互连尺寸可缩小至纳米级,寄生电容显著降低。

TSMC SoIC技术则在商业化层面推动了Hybrid Bonding的成熟。其Cu-Cu直接键合间距已进入sub-10μm量级,相比传统Micro-bump实现约15倍互连密度提升和约3倍能效改善,已在AMD 3D V-Cache等产品中得到验证。这些进展表明,垂直有源层堆叠已从实验室原型走向可量产工艺,为空间逻辑折叠提供了可靠的硬件载体。

4.2 关键路径垂直重构与互连优化
将时序关键路径逻辑分布到不同有源层,是空间逻辑折叠实现性能提升的核心机制。通过垂直重构,设计者可显著缩短信号传播距离,降低RC寄生电容与电阻,同时减小时钟偏斜,并支持逻辑与存储的紧密垂直集成。这一技术直接受益于单片3D IC工艺的成熟。

典型的3D IC架构
IMEC团队在Sequential-3D集成领域的系统性研究为垂直重构提供了量化依据。这些工作分析了S3D在不同粒度下的性能影响,指出通过将关键逻辑块分布至不同层,结合细间距垂直互连,可有效降低互连延迟并改善整体时序。实验与建模结果显示,在7nm节点或以下3D集成能在保持功耗约束的前提下,实现比传统2D布局更优的关键路径性能,尤其在高扇出关键路径上优势明显。
单片3D IC的另一重要优势在于对RC寄生的控制。相比TSV-based 3D Stacking,单片工艺采用纳米级MIV,垂直互连的寄生电容可降低一个数量级以上。相关3D IC研究表明,将时序关键路径中的长水平走线“折叠”至垂直方向后,平均连线长度可减少约50%,相应动态功耗和延迟显著下降。
4.3 配套支撑技术
空间逻辑折叠的落地高度依赖配套支撑技术,其中3D架构兼容的EDA工具与多物理场仿真能力尤为关键。
EDA巨头已在3D IC工具链上投入大量资源。Synopsys的3DIC Compiler平台支持多层Die的自动floorplanning与分区优化,并集成热-电耦合分析模块,可在早期设计阶段评估垂直互连对时序和功耗的影响。Cadence则通过Innovus和Clarity 3D Solver提供针对Hybrid Bonding与Monolithic Vias的寄生提取和多物理场仿真能力,支持对堆叠结构中热密度与机械应力的联合分析。这些商用工具已能处理亚10μm键合间距带来的复杂寄生效应,显著缩短了从概念到签核的迭代周期。

3D IC的EDA设计流程
电源完整性分析同样是当前重点。学术与产业合作项目正推动 Backside Power Delivery Network(BSPDN)与多层电源网格的联合仿真,解决垂直堆叠带来的电流密度不均与电压降问题。相比传统2D设计,3D IC的多物理场仿真复杂度呈指数级上升,现有工具仍在持续优化求解速度与精度。
05
代表性芯片与主要技术玩家
在移动SoC领域,华为麒麟系列的演进最具代表性。华为近期宣布的Kirin 2026处理器全面采用LogicFolding架构,通过3D LogicFolding堆叠实现晶体管密度提升53.5%、能效改善41%,时钟频率接近3.1GHz,目标达到每平方毫米2.38亿晶体管,相当于1.4nm节点水平。这一进展直接体现了空间逻辑折叠与时序重构的结合应用,标志着从选择性关键路径优化向多层全面折叠的实质跨越。
服务器与HPC平台方面,华为鲲鹏系列在异构集成场景中积极探索Chiplet与垂直堆叠技术,目标提升核心密度与系统级互连效率。这类实践通常结合时序逻辑折叠提升资源利用率,同时借助空间折叠缓解互连瓶颈。
AMD则通过TSMC SoIC实现3D V-Cache(SRAM垂直堆叠于逻辑之上),已验证hybrid bonding在高性能场景下的实际收益。
06
对芯片架构的影响、挑战
逻辑折叠通过时间与空间维度的资源重构,在半导体工艺微缩之外,为后摩尔时代芯片架构提供了另一优化维度。其影响已从学术原型延伸至移动SoC与AI加速器实践,同时也面临从验证走向大规模部署的现实挑战。
时序逻辑折叠显著增强了可重构架构对LLM多样化算子(GEMM、Attention、稀疏操作等)的适应性与面积效率。空间/垂直逻辑折叠则通过缩短关键路径和提升晶体管密度,有效缓解互连瓶颈与内存墙问题。两者结合,在灵活性与资源利用率之间提供了优于固定功能加速器(GPU、TPU类、LPU类)的权衡空间,尤其适合工作负载持续演进的场景。
时序逻辑折叠以一定执行周期增加为代价换取面积节省,对重构速度和调度算法要求较高。当前细粒度动态重构仍面临配置存储开销与功耗控制的平衡难题。
空间/垂直逻辑折叠则面临热密度上升、多层对准与键合良率、3D EDA工具成熟度以及电源完整性等工程挑战。单片3D逻辑堆叠技术虽已取得IMEC mCFET与TSMC SoIC等进展,但从原型验证到大规模AI训练与推理部署的系统级成熟度仍有很多路要走。热管理与多物理场仿真的精度不足,仍是制约垂直折叠大规模应用的主要瓶颈。
就目前业内发展看,时序与空间逻辑折叠的混合使用已在路上。未来将与光互连、近存计算深度融合,进一步放大系统级收益。面向LLM的专用Folding调度与映射框架将持续发展,结合自动展开与多目标优化工具,实现更精准的面积-延迟权衡。垂直逻辑折叠有望成为高密度可重构与异构AI芯片的重要标配技术选项。
笔者看来,逻辑折叠不是单一解决方案,而是与Chiplet、光互连、近存计算协同演进的重要路径,是在半导体工艺微缩之外的另一选择。对投资人与技术决策者而言,关注相关使能技术的成熟度与生态构建,将有助于把握后摩尔时代AI芯片架构的国产化差异化机遇。
✦
✦
2026中国AI智能体大会
✦

✦
✦
入群申请
✦

点击下方名片 即刻关注我们