点击下方卡片,关注“具身智能之心”公众号
作者丨Jia Zheng 等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
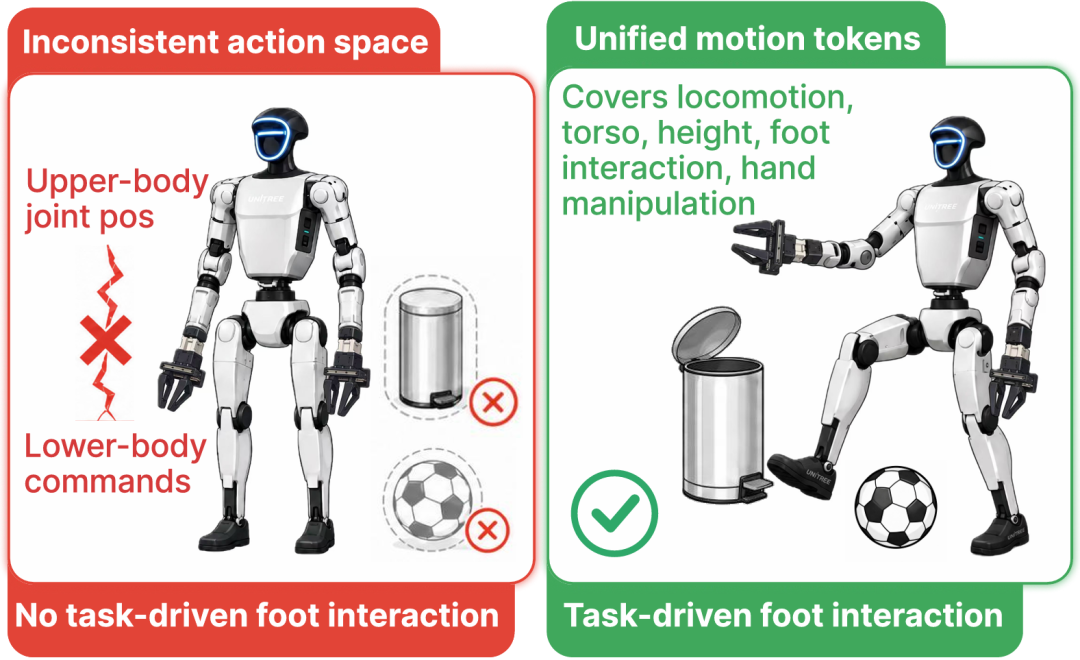
人形机器人的移动操作(loco-manipulation)正在从“上半身完成操作任务、下半身负责行走”的分层范式,走向更统一的全身控制。
这个转变很 make sense ,现实任务里,弯腰、下蹲、转身、踢球、踩踏、推车和双手操作经常同时发生。传统高层操作策略只给上肢关节目标,低层控制器只接收速度、高度、朝向这类粗粒度底盘命令,结果是腿部被限制在维持平衡的角色里,很难成为任务的一部分。
另一方面,WAM 给机器人策略引入了视频动态先验,但现有 WAM 多集中在桌面机械臂,迭代去噪视频和动作 latent 的开销又太高,直接搬到闭环人形机器人上会卡在实时性。
论文标题:MotionWAM: Towards Foundation World Action Models for Real-Time Humanoid Loco-Manipulation arXiv:https://arxiv.org/abs/2606.09215v1
MotionWAM 的核心判断可以概括为两点:第一,人形移动操作需要一个统一的全身动作空间,让腿、躯干、手同时参与任务;第二,WAM 的视频动态先验不能等完整未来视频去噪完成后再给动作模型使用,必须在一次前向里抽取中间去噪特征,才能满足实时闭环控制。基于这两个判断,论文把 Video DiT 和 Motion DiT 耦合起来,让策略从单个头戴相机出发,预测统一的 whole-body motion token,并在 Unitree G1 上完成 9 个真实移动操作任务。

架构:用视频 DiT 的中间去噪特征驱动统一全身 motion token
MotionWAM 沿用“先预测视频动态,再反推出动作”思路,预测对象从单臂动作扩展到统一全身 motion latent。论文把这个过程写成:
这里 是语言目标, 是当前第一人称观测, 是机器人本体状态, 是下一帧视觉状态, 是视频流在 flow 时间步 上的中间未来帧状态, 表示从生成过程中抽取隐藏状态。 负责从当前观测和语言目标预测未来视觉动态, 根据当前观测、本体状态和视频生成隐藏特征预测 motion latent 。最后一项表示中间状态的去噪过程。
这套公式的关键在于 。MotionWAM 跳过完整视频生成结果,直接在视频生成器的中间状态里读取“场景将如何变化”的信息。这个中间动态特征比静态 VLM 表征更接近接触、移动和未来状态变化,同时比完整去噪视频便宜得多。
MotionWAM 的动作表示建立在 SONIC 上(SONIC论文链接:https://arxiv.org/abs/2511.07820 ),whole-body motion latent 被写成:
是 SONIC motion token,论文中通过 Finite Scalar Quantization 得到,用 64 维离散向量概括移动、躯干、高度和足部交互意图; 是连续通道,覆盖 SONIC 未直接表示的灵巧通道,例如左右夹爪命令或灵巧手命令。这样一来,一个动作 latent 同时携带“身体怎么动”和“手怎么操作”。
架构上,Video DiT 初始化自 Cosmos-Predict2.5-2B,包含因果时空 VAE 和 flow-matching diffusion Transformer,并使用 Cosmos-Reason1 的语言嵌入。给定当前帧 latent 和未来帧噪声 latent ,MotionWAM 在固定 flow 时间步 截取 Video DiT 某个 Transformer block 的激活:
是 Video DiT 的速度网络, 是视频分支参数, 是当前观测的干净 VAE latent, 是语言目标, 是被送入 Motion DiT 的中间隐藏状态。论文把 固定在接近纯噪声的一端,也就是 。这样 Video DiT 只做一次前向,在“one-shot imagination”状态下产生动态特征,不执行多步未来视频去噪。
Motion DiT 随后把 、本体状态 和带噪 motion latent token 一起输入,通过交错的 self-attention / cross-attention 输出 motion velocity field。Stage 2 多 embodiment 训练时,不同机器人或数据格式通过各自的输入/输出投影层接入共享 Motion DiT trunk;部署时复用同一个 trunk,只保留 Unitree G1 的投影器。

训练:先学第一人称视觉动态,再把动态先验接到人形动作空间
MotionWAM 的训练分三步,这个过程中 VAE 和文本编码器全程冻结;Stage 1 只更新 Video DiT;Stage 2 接上 Motion DiT 后联合更新视频和动作网络;Stage 3 在 Unitree G1 目标任务上做全网络微调。
两个分支都用 flow matching。先看视频分支。给定干净的当前帧 latent 、干净未来帧 latent 和高斯噪声 ,在 flow 时间 构造带噪未来 latent:
Video DiT 学习从干净未来帧指向噪声的速度场:
这里 是视频速度网络的预测, 是 flow matching 的目标速度, 约束预测速度和目标速度一致。这个损失让 Video DiT 学会:从当前第一人称图像和语言出发,未来视觉状态可能如何演化。
动作分支也使用同类目标。对干净 motion latent chunk 和噪声 ,Motion DiT 预测:
是 Motion DiT 的速度网络, 是动作分支参数, 是 motion latent 在动作 flow 时间 上的带噪状态, 是视频分支的一次前向隐藏特征, 是本体状态, 是 embodiment 索引。这个损失让 Motion DiT 学会把视频动态特征、本体状态和不同 embodiment 标签映射到可执行的 motion latent。
Stage 1 是第一人称视频预训练。作者组装约 2,136 小时第一人称人类视频和人形机器人视频,只训练 Video DiT 的 。论文强调,Stage 1 的瓶颈在第一人称视觉动态,而非动作多样性。先用廉价、无需动作标注的视频把视觉世界模型移到机器人第一人称分布,比直接依赖少量动作演示更容易 scale。
Stage 2 是跨 embodiment 动作后训练。作者接上 Motion DiT,在异构 Unitree G1 人形数据上训练,数据覆盖不同末端执行器和动作标注格式。为了避免动作信号进入后冲掉已有动态先验,Stage 2 保留视频目标作为表征正则,联合损失为:
这里 负责把视频特征落到动作空间, 负责维持视频动态表征。二者相加意味着模型一边学跨 embodiment 动作 grounding,一边保留第一人称世界模型能力。
Stage 3 是 Unitree G1 全身遥操作数据微调。作者在 9 个真实任务上每个任务采集 200 条遥操作 episode,遥操作来自 PICO VR 三点追踪,经 SMPL-24 重定向到 Unitree G1。此时 action 输出切换到统一全身 motion token,仍然沿用 Stage 2 的联合损失和共享 trunk + Unitree G1 projector 配置。
离散 token 的恢复过程写成:
是放进连续 motion latent 里的标量槽,用来承载 SONIC motion-token 索引; 是模型预测出的连续值; 把连续值四舍五入到最近的离散 token 索引 ; 是 SONIC 解码后的机器人关节命令。这个设计避免为离散 token 另加一个分类头,使离散索引和连续末端执行器值共用同一个 flow-matching 预测接口。
实验:真实 G1 上强于 VLA,Stage 2 和实时读取中间特征是关键
实验平台是 Unitree G1,人形机器人配备双 ALOHA2 夹爪,头部安装 Intel RealSense D435i RGB 相机。所有策略都作为 WebSocket policy server 运行在单张 RTX 4090 工作站上,由机载控制器闭环查询。任务集包含 9 个真实全身移动操作任务:拿放瓶子、踢足球、取物并关抽屉、推车并装衣服、扔垃圾、取篮子、货架摆放、擦白板、投放衣物。每个方法每个任务测试 20 次,成功率按成功 trial 占比计算。
主结果显示,MotionWAM 在 9 个任务上全部领先,平均成功率从最强基线 GR00T-N1.7 的 43.9% 提高到 76.1%。

论文对比了五个基线:Diffusion Policy 和 ACT 代表非 VLA 视觉动作策略; 和 GR00T-N1.7 代表强 VLA / 人形基础模型;Qwen3DiT 是作者构造的参数匹配消融,用 Qwen3-VL 2B 替换 Cosmos 视频世界模型,保留 Motion DiT、统一 motion latent 和相同训练接口。所有方法都使用同样的第一人称 RGB、语言目标、本体状态,并输出同一套统一 motion latent。因此,差异主要来自策略条件是视频世界模型中间去噪特征,还是静态图像-文本式表征。
具体看任务,MotionWAM 在需要全身协调的任务上拉开差距最明显:Kick Soccer、Load Cart、Retrieve Item 分别比最强基线高 40 个百分点,Wipe Board 高 45 个百分点,Do Laundry 高 30 个百分点。Qwen3DiT 在许多移动重的任务上接近 0, 平均成功率也低于 20%。这个结果支持论文的判断:语义先验本身不足以处理闭环物理人形移动操作,视频动态先验和统一全身动作空间共同补上了关键缺口。
三阶段训练的消融进一步说明,Stage 1 和 Stage 2 各自承担不同角色。

在 5 个代表任务上,完整模型平均成功率 70.0%;去掉 Stage 1 后降到 59.0%,下降 11 个百分点;去掉 Stage 2 后降到 42.0%,下降 28 个百分点。论文的解释是:没有 Stage 1 时,Video DiT 缺少第一人称动态适配,隐藏状态仍有语义但 motion latent 预测不够准确;没有 Stage 2 时,Motion DiT 直接接到 Stage 1 trunk 上,只靠少量目标任务数据学习动作 grounding,结果在所有任务上明显退化。换言之,Stage 1 负责把视觉世界模型移到第一人称分布,Stage 2 负责把这种动态先验接进跨 embodiment 动作空间。
实时性是这篇工作的另一条硬指标。MotionWAM 的部署频率为 4.9 Hz,虽然低于 Qwen3DiT 的 9.0 Hz 和 GR00T-N1.7 的 6.5 Hz,但明显快于同为世界模型策略的 Cosmos Policy。

这张表说明 MotionWAM 没有为了引入世界模型而牺牲到不可部署的速度。Cosmos Policy 需要反复去噪未来视频再产出动作,频率只有 0.7 Hz;MotionWAM 只读取 Video DiT 一次前向中的中间特征,因此在 2.5B 可训练参数规模下仍能达到 4.9 Hz 的 chunk-wise 输出频率。对需要闭环平衡的人形机器人来说,这个设计直接决定了 WAM 能不能从离线评估走到真实控制。
论文也给出了失败案例。主要失败来自单个头戴相机的视觉 grounding 丢失:被操作物体离开视野,或头部相机视角偏离训练分布时,策略可能停滞或选择不准确的全身轨迹。

这个失败模式和方法设计本身有关。MotionWAM 的优势来自第一人称视频动态先验;一旦视觉输入没有覆盖任务关键物体,世界模型隐藏状态和动作模型都缺少可靠 grounding。论文还承认,Stage 3 微调只在 Unitree G1 上验证,尚未证明能跨硬件迁移;实验也没有严格的新物体泛化研究,训练和测试物体在视觉上仍有相似性。
总结
MotionWAM 把 WAM 和人形机器人全身控制之间最难的两个接口问题同时处理了:一是速度接口,用 Video DiT 的中间去噪特征替代完整未来视频去噪;二是动作接口,用统一 motion latent 取代上肢关节目标和下肢底盘命令的分裂表示。这让 WAM 不再只是桌面机械臂上的动态先验,而能进入真实 Unitree G1 的闭环移动操作。
局限也比较清楚,单头戴相机带来明显盲区,失败案例已经显示只要物体离开视野,策略就容易丢失 grounding。笔者比较关心的未解问题是:如果把多视角、记忆或主动视角控制接进 MotionWAM,它的统一全身 latent 是否还能保持现在的实时频率?这会直接影响这条路线能否从受控实验场景继续走向更开放的家庭和工厂环境。
推荐阅读 :












