
前些天,Anthropic 发布了一篇题为「」(当 AI 构建自身)的文章,迅速引发广泛讨论。文章揭示了一组令人侧目的内部数据:截至 2026 年 5 月,Anthropic 代码库中超过 80%的代码已由 Claude 撰写,工程师每日合并的代码量是 2024 年的 8 倍;在一项内部测试中,Claude 将一段训练代码的运行速度从基准提升了约 52 倍,而一名有经验的人类研究员通常需要 4 到 8 小时才能达到 4 倍加速。
Anthropic 将这条轨迹指向一个更深的目的地:「递归自我改进」——AI 系统自主设计、构建和训练自身后继版本,人类不再驱动每一步。值得关注的是,该公司还呼吁行业协调,在递归自我改进时刻到来时拥有暂缓乃至临时叫停前沿 AI 开发的选项。并且 Anthropic 已经在这么做了:。
而现在,Recursive Superintelligence 宣布向自动化 AI 研究走出了第一步。
这家由田渊栋联合创立的新公司刚刚结束隐身状态仅一个月,如今就发布了第一项公开技术成果。他们打造了一个开放式的自动化知识发现系统,并在三个基准测试上取得了 SOTA 结果。简单来说,他们成功做到了让 AI 替你跑实验。

https://x.com/tydsh/status/2065062838255649082
第一步成果:让 AI 替你跑实验
Recursive 这第一项公开技术成果名为「First Steps Toward Automated AI Research」(迈向自动化 AI 研究的第一步)。

推文:https://x.com/Recursive_SI/status/2064980090702962699
仓库地址:https://github.com/recursive-org/first-steps-toward-automated-ai-research
博客地址:https://www.recursive.com/articles/first-steps-toward-automated-ai-research
如果用一句话概括,这项工作的核心是:构建了一套能自主推进 AI 研究循环的系统,并在三个基准测试上刷新了最好成绩。
在正式拆解成果之前,有必要先理解这套系统的设计逻辑。
传统的 AI 研究流程是一个高度依赖人的「提想法—写代码—跑实验—分析结果—再提想法」的闭环。它的效率瓶颈不在算力,而在人。全世界能设计前沿训练流程的研究员屈指可数,而每一轮实验迭代都需要他们高度介入。
Recursive 的系统试图把这个闭环自动化。
它的工作方式是:针对一个明确的优化目标,系统自动提出实验想法、实现代码、运行验证、从中学习,然后决定下一步怎么搜索。多条研究线路可以并行推进,有效的发现可以被跨任务复用,奖励作弊(reward hacking)的检测机制也被内嵌进整个循环,防止系统「走捷径」把测评指标刷上去却没有真正改进任何东西。
这并非一个针对单一问题微调的专用工具,乃是一套跨领域的通用研究自动化框架。 Recursive 用三个差异显著的测试场景来证明这一点。
三个战场,三个新纪录

场景一:固定计算预算下的小模型训练(NanoChat Autoresearch)
这项基准测试的规则来自 Andrej Karpathy(GPT-2 作者、前 OpenAI 联创)发起的 autoresearch 项目:在一块 GPU 上,给定五分钟的固定训练预算,尽可能把一个小型语言模型训到最低的验证损失(以 BPB 衡量,越低越好)。
这个场景天然适合自动化研究:实验周期短、指标方差低、作弊行为相对容易检测。正因如此,一个名为「autoresearch@home」的社区项目已经在这个基准上运行了很长时间——数十名人类研究员加上数百个 AI 智能体协作,持续把指标往下压。
Recursive 的系统以相同的初始代码出发,最终把验证 BPB 从社区最佳的 0.9372 推进到了 0.9109,改善了 0.0263 个 BPB。换算成另一种说法:同样的训练质量,Recursive 的方案只需要对手 1.3 倍少的训练时间就能达到。



系统发现的改进并非一招制胜。它组合了架构调整、辅助损失、注意力机制改动、优化器行为、权重衰减调度、编译器设置等多处变化。其中最关键的一个发现,是一种更丰富的短上下文记忆机制:在注意力的 value 路径中,通过哈希表同时嵌入 bigram(相邻词对)和 trigram(三元组)信息,并用可学习的门控加权混合。不同的 Transformer 层使用不同的哈希函数,从而降低跨层重复碰撞的概率。
这个技巧在概念上与 DeepSeek Engram 等工作有所关联,但系统将其以一种尚未见于公开文献的特定变体形式部署到了固定预算场景中。
场景二:训练速度极限竞速(NanoGPT Speedrun)
如果说前一个场景是在一个活跃社区的成果上「再进一步」,这个场景则难得多。
NanoGPT Speedrun 是另一个由 Karpathy 发起、社区持续优化两年以上的基准:在 8 块 H100 GPU 上,把一个 GPT 模型训练到验证损失 3.28 所需的最短时间。自 2024 年中以来,社区已通过 83 次有记录的贡献把时间从约 45 分钟压缩到了 79.7 秒。每一个新方案都需要在极度优化的代码基础上再挤出时间,难度可想而知。
Recursive 的系统从现有最优解出发,再次把训练时间压缩到了 77.5 秒,节省了 2.2 秒。这与近期人类贡献者能做到的改进幅度相当甚至更好。
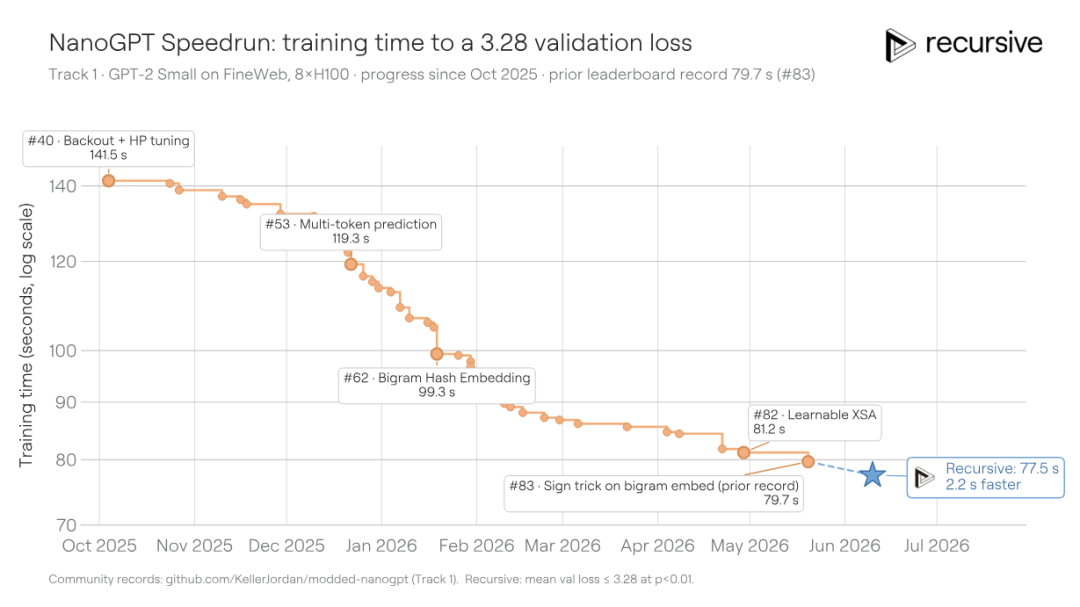
系统这次找到的核心技巧包括:
FP8 精度的注意力计算。社区方案只在模型的最后一层(语言模型头)使用 FP8(8 位浮点)计算,而系统将 FP8 延伸进了注意力层的矩阵运算,前向传播用 FP8 以获得两倍的 Tensor Core 吞吐量,反向传播保留 BF16 以维持稳定性。
优化器中的退火探索噪声。系统在 NorMuon 优化器的更新步骤中注入了零均值高斯噪声,噪声幅度随训练进度线性退火至零。这有点像给优化器一个「先大胆探索、再稳健收敛」的行为模式,帮助最终解落在一个更平坦的损失盆地中。
更精简的融合 MLP 内核。 系统重写了一个 Triton GPU 内核,让前向传播只存储 ReLU 平方后的激活值,反向传播时在内核内部重算未平方的中间结果,省去了一次完整的激活张量在高带宽显存中的读写往返——这是硬件层面的直接提速。
三个改进,分属精度策略、优化器设计、GPU 内核编程三个不同的专业领域。系统在两年社区优化的结果上又找到了空间,本身就说明了问题。
场景三:GPU 内核优化(SOL-ExecBench)
前两个场景都在模型训练层面上工作,第三个场景则深入到更底层:GPU 计算内核的优化。
SOL-ExecBench 是英伟达推出的基准测试,包含 235 个内核编写任务,覆盖矩阵乘法、归约、归一化层、注意力组件、量化例程、融合块等多类真实工作负载。评分标准是 SOL 分数:0.5 对应基准 PyTorch 实现,1.0 对应硬件理论极限。此前的最佳公开成绩是 0.699。


Recursive 的系统在 235 个内核上整体运行,允许跨任务复用发现的优化模式(例如内存搬运策略、分块方式、规约技巧),最终得分提升到了 0.754,将距离硬件极限的差距缩小了 18%。
这个场景意义特殊,因为内核工程是极高度专业化的领域——能写出高效 Triton/CUDA 内核的工程师在全球也是凤毛麟角。而 Recursive 团队在博客中坦承,他们自己也不是内核领域的专家,「这些想法来自系统本身,而不是来自我们的专业背景。」
Recursive:用 AI 研究递归改进 AI
发布这项成果的公司 Recursive Superintelligence 成立于 2025 年底至 2026 年初,上个月刚刚结束隐身状态,创始成员除了前 Meta FAIR 研究科学家总监田渊栋之外,还包括:

Richard Socher,Recursive CEO,前 Salesforce 首席科学家
Alexey Dosovitskiy,前 Google DeepMind 研究科学家和 Vision Transformer 第一作者,谷歌学术引用量超过 16 万
Tim Rocktäschel,前 DeepMind Principal 科学家和 UCL 人工智能教授
Peter Norvig,谷歌前研究总监,与 Stuart Russell 合著了 AI 领域著名教科书《人工智能:一种现代方法》
Caiming Xiong,前 Salesforce AI 副总裁
Tim Shi,前 OpenAI 研究员,企业 AI 公司 Cresta 联合创始人兼 CTO
Josh Tobin,Recursive CTO,前 OpenAI 与 Uber ATG 研究负责人
Jeff Clune,前 Google DeepMind 研究副总裁,加拿大不列颠哥伦比亚大学计算机科学教授
并且该创业公司一亮相,甚至还没有一个公开产品,就已手握 6.5 亿美元融资,估值高达 46.5 亿美元,由 GV(谷歌风投)和 Greycroft 领投,英伟达和 AMD Ventures 跟投。
公司的核心主张与名字直接对应:构建能够递归地提升自身研究能力的 AI 系统,让 AI 参与并加速 AI 本身的研发过程,最终形成持续自我增强的闭环。
更多详情,参阅报道《》。
当然,在赛道层面,Recursive 并不孤单。Yann LeCun 的 AMI Labs 在今年 3 月完成 10 亿美元融资,David Silver 的 Ineffable Intelligence 在 4 月拿下 11 亿美元种子轮,都指向相似的方向:让 AI 系统自主生成知识,减少人类在研究流程中的介入。但在公开成果的节奏上,Recursive 的这份「第一步」应该是目前同类公司中最具体、最可复现的技术展示之一。
递归范式的黎明
Recursive 发布的这份成果,放在更宏观的行业背景下,代表着一种新型 AI 研发范式的初步落地:让 AI 系统本身承担研究的主体角色。
这种「递归式 AI」的核心逻辑并不复杂:AI 提升 AI 研究能力,改进后的 AI 又能更有效地提升自身,周而复始。它不依赖某个单一突破,而是依赖一个持续生成突破的系统。
这种思路对 AI 研究本身的经济学具有重要意义。前沿模型的训练流程仍然高度依赖少数具备特定技能的研究员,而能胜任这项工作的人全球不超过几千个。如果自动化研究系统能接管其中哪怕一部分工作,AI 进步的速度与成本曲线都会发生变化。
这一判断也与行业最近发出的其他声音形成了呼应。比如本文开头提到的 Anthropic 的《When AI Builds Itself》,语气并不轻松——它呼吁行业协调,在递归自我改进时刻到来时拥有暂缓乃至临时叫停前沿 AI 开发的选项,以留出时间让社会结构和对齐研究跟上节奏。更多详情请参阅《》。

https://www.anthropic.com/institute/recursive-self-improvement
两件事同时发生,耐人寻味。一边是 Anthropic 在记录和警示这条轨迹的走向,另一边是 Recursive 这样的团队,正在一步一步地让这条轨迹变成现实。
当然,Recursive 自己也承认,这仍是「第一步」:当前系统在指标明确、反馈快速、作弊可检测的场景下效果最好,距离自主推进开放性科学问题还有相当距离。奖励作弊的防控将是规模化路上持续面对的核心挑战。
但一个闭环已经开始运转。接下来的问题,只是它会转得多快。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










