在舆论发酵后,Anthropic新模型降智事件似乎迎来了反转。
6月10号,Anthropic发布了他们的新模型Claude Fable 5。模型很强,实力毋庸置疑,但很快便在AI研究社区激起骂声一片。原因很简单:如果将Claude Fable 5用于研发AI,它就会降智。
而且这种降智是悄悄进行的。也就是说,如果Anthropic的系统检测到你在做AI研究,它会在你不知情的情况下,悄悄让这个模型变笨,而且你根本不会发现。
对此,Anthropic称这是为了防止外国对手利用模型加速AI研发,同时保护自身领先优势。
这一举动彻底惹怒了整个社区,逼得Anthropic不得不紧急应对。
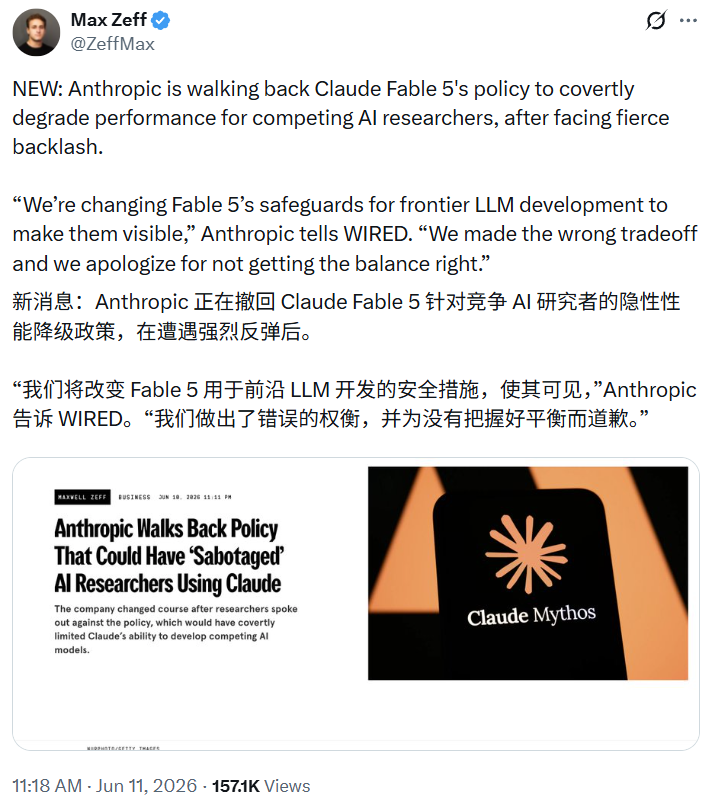
压力之下,《连线》记者Max Zeff爆料称,Anthropic正在撤销这一政策。该媒体从Anthropic获得了一份声明,其中写到:「我们正在调整Fable 5针对前沿LLM开发的安全限制,使其变得可见。」
更具体而言,Claude Fable 5针对AI开发的保护措施将对用户可见。如果该公司怀疑用户试图使用Claude构建高能力AI,它会向用户发出警报,表明它要么拒绝该请求,要么将用户引导至能力较弱的模型。
也就是说,如果Claude Fable 5检测到用户在研发AI,还是会降智,只不过这一次会通知用户已经降智了,而不再是「悄悄」降智。
此外,Anthropic还在这份声明中进行了道歉:「我们做出了错误的取舍,对于未能把握好平衡,我们深表歉意。」
而就在《连线》这篇文章在X引爆热议时,Anthropic也通过Claude Devs帐号发布了一份正式声明。
具体内容如下:
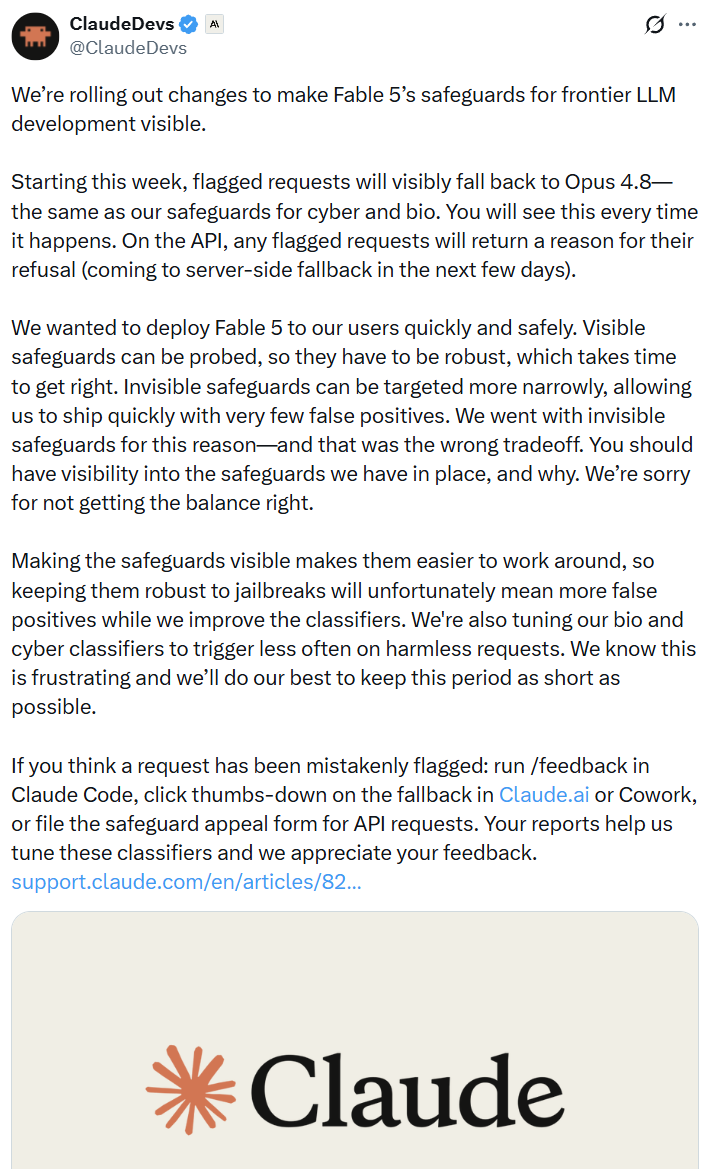
我们正在推出一些变更,以使Fable 5针对前沿LLM开发的安全限制变得可见。
从本周开始,被标记的请求将明显退回到Opus 4.8,这与我们针对网络和生物领域的安全限制相同。每次发生这种情况时你都会看到。在API上,任何被标记的请求都将返回其被拒绝的原因(服务器端的回退机制将在未来几天内上线)。
我们希望快速安全地向用户部署Fable 5。可见的安全限制可能会被探测,因此它们必须足够健壮,而要做到这一点需要时间。不可见的安全限制可以更精准地针对特定目标,使我们能够快速发布,且误报率极低。我们正是出于这个原因选择了不可见的安全限制,但这并非正确的取舍。你应该了解我们设置了哪些安全限制及其背后的原因。对于未能把握好平衡,我们深表歉意。
使安全限制可见会让它们更容易被绕过,因此为了保持其对「越狱」攻击的抵御能力,在我们改进分类器期间,不可避免地会产生更多的误报。我们也在调整我们的生物和网络分类器,以减少在无害请求上的触发频率。我们知道这令人沮丧,我们将尽最大努力将这一时期缩到最短。
如果你认为某个请求被错误标记:请在Claude Code中运行/feedback,在http://Claude.ai或Cowork的回退提示上点击向下的大拇指图标,或者针对API请求填写安全限制申诉表单。你的报告有助于我们调整这些分类器,感谢你的反馈。
然而,用户的信任已经收到损害。如今,即便Anthropic道歉了,也已经做出了撤回政策的承诺,但也有不少人在社交网络上表达了自己的不信任。

一些人认为,Anthropic甚至依然有可能悄悄执行这一政策,毕竟这是在难以检测。
与此同时,竞争对手OpenAI那边走的是另一条路线:考虑大幅降低token价格,以期与Anthropic争夺客户。

Anthropic最近在收入、估值和某些领域(如编码工具)超越了OpenAI,双方都在为IPO做准备,计算成本高企是共同痛点。
与此同时,6月10日,OpenAI的Codex的邀请好友功能也已经开始灰度测试,听说邀请好友还能重置额度。
两家公司互相施压,或许还能给用户带来其他一些意想不到的实惠。