点击下方卡片,关注“具身智能之心”公众号
作者丨Minghan Qin 等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
具身智能的进阶,离不开具备运动学属性的“仿真级”铰链资产。然而,现有的 3D 生成技术大多仍停留在静态网格阶段;而现有的铰链化方案,往往受限于多阶段流水线带来的误差累积,或因密集 Token 表示导致的内存溢出(OOM),难以高效处理复杂的机械结构。
为突破这一瓶颈,我们推出了基于统一 MLLM 的铰链资产生成框架——SimArt。只需输入原始网格,SimArt 即可在单次推理中同步完成部件分解、关节预测与 URDF 逻辑构建。
相比传统方案,SimArt 的核心创新在于引入了稀疏 3D VQ-VAE,成功将 Token 冗余降低 70%,有效突破了复杂结构的规模化处理难题;同时,依托 MLLM 强大的物理世界推理能力,该框架在铰链精度与几何一致性上均达到了 SOTA 性能,真正实现了从静态网格到可交互物理资产的“一键式”高质量转化。
目前,该工作已被SIGGRAPH 2026接收,代码已开源。

论文链接: https://arxiv.org/abs/2603.19616 项目主页: https://SimArt-mllm.github.io 代码: https://github.com/ByteDance-Seed/SimArt
研究背景

在具身智能与物理仿真领域,高质量且支持物理交互的“仿真级(sim-ready)”铰链资产是至关重要的基础设施。然而,现有的 3D 生成技术大多仍停留在静态网格阶段,手动创建带有运动学信息的模型极其耗费人力,行业亟需自动化、高鲁棒性的生成方案。目前,主流的自动化铰链资产生成方法主要面临以下两大挑战:
挑战一:多阶段流水线带来的误差累积与物理约束冲突
现有的铰链物体生成方法通常采用“部件分割 -> 关节参数推断 -> 后期组装”的解耦级联流程。这种处理方式不仅容易导致误差在模块间逐级放大,且前置的部件分割往往缺乏关节感知(articulation-aware),生成的部件虽外观合理却违背了真实的运动学约束。这最终导致预测的关节与提取的几何结构无法匹配,产生物理上不可用的铰链输出。
挑战二:密集 3D 表示带来的内存瓶颈与算力开销
尽管多模态大模型(MLLM)为端到端的联合理解与生成提供了新路径,但现有的 3D 原生大模型大多依赖密集的体素表示。该方法会将大量计算资源浪费在空白区域的编码上,生成冗长的特征序列,最终受限于密集 Token 表示导致的内存溢出(OOM)。这一算力瓶颈极大限制了模型处理高保真、多部件复杂铰链物体的规模化扩展能力。
针对上述问题,我们提出了 SimArt——首个能够将静态 3D 网格转化为功能性“仿真级”铰链资产的统一多模态大模型框架。SimArt 能够在统一的网络架构内,同步完成部件级几何分解与运动学参数预测。为突破 3D Token 带来的算力瓶颈,该框架创新性地引入 Sparse 3D VQ-VAE,仅对有效表面体素进行选择性编码。实验表明,该稀疏表示成功将传入 MLLM 的 Token 数量降低 **70%**,彻底缓解了显存压力。同时,SimArt 在 PartNet-Mobility 及多源 AIGC 生成物体的基准测试中均取得了 SOTA 性能。其输出的高精度、符合真实物理逻辑的 URDF 资产,可直接应用于机器人物理仿真控制与 VR/AR 混合现实场景。
SimArt 方法解析

SimArt 的核心思想在于通过一个统一的多模态大模型(MLLM)架构,打破传统静态 3D 网格到铰链物体生成中存在的“多阶段解耦”壁垒,实现端到端的几何分解与运动学物理推理:
统一的多模态联合推理管线:传统方法通常采用“先分割部件、再估计关节、最后组装”的级联架构,这种方式不仅容易造成误差的级联累积,且分割模块往往缺乏对运动学的感知,导致最终模型违背物理常识。SimArt 摒弃了这一繁琐流程,以 Qwen3-VL 为基础主干,将视觉图像、文本指令和 3D 几何特征映射到统一的隐空间。在单次前向推理中,模型能够同时且一致地完成细粒度的部件级网格分解与结构化 URDF 参数预测(涵盖关节类型、轴心、限位、质量分布等),确保了几何形态与物理逻辑的完美对齐。
引入稀疏 3D VQ-VAE 突破算力瓶颈:现有的 3D 原生大模型大多依赖密集的体素(Dense Voxel)表示,这使得处理复杂几何结构时会产生极其庞大的 Token 序列,直接导致内存溢出(OOM)。为此,SimArt 提出了一种基于占据状态(Occupancy)的稀疏 3D VQ-VAE。该机制在编码阶段自动识别并过滤掉大量的空白体素,并巧妙引入了一个专属的“Zero Token”来宏观表征未占据空间。这一创新设计成功将传入大模型的 3D Token 数量断崖式削减了 70%,在完美保留物体高保真表面细节的同时,彻底释放了 MLLM 处理多部件、复杂机械部件组装的潜力。
通过深度融合大语言模型的逻辑推理能力与极其轻量化的稀疏 3D 表示,SimArt 成功打造了一条高效、高保真且严格遵循物理运动规律的“仿真级”资产自动化生成流。
深度解析:Sparse 3D VQ-VAE 稀疏表征

在 SimArt 的架构中,稀疏 3D Token 表征(Sparse 3D VQ-VAE)是突破多模态大模型 3D 几何处理算力瓶颈的关键设计。该模块优化了大模型理解三维空间的方式,具体体现在以下三个核心层面:
避免无效计算:引入专属 Zero Token 的选择性编码
传统的 3D 原生大模型通常依赖密集体素表示(Dense Voxel),会对整个三维空间(包括大量空白区域)进行无差别编码,导致较高的计算冗余。SimArt 基于变分自编码器构建了稀疏编码策略,并在离散码本(Codebook)中将第 0 个索引设为专属的“Zero Token”。在编码过程中,模型会自动过滤未被占据的空白区域,仅对包含实际几何表面的体素特征进行矢量量化(Vector Quantization),从而将计算资源集中于有效几何信息。
高效的序列压缩:降低 70% 冗余,突破显存限制
在多模态大模型(MLLM)中,过长的上下文序列极易引发密集 Token 表示导致的内存溢出(OOM),严重限制了模型处理多部件、高复杂度机械结构的能力。得益于基于占据率的稀疏化机制,SimArt 将输入大模型的有效 3D Token 数量大幅降低了约 70%。这一优化有效缓解了训练与推理过程中的显存压力,在保持高精度几何细节的同时,为多模态联合推理提供了充足的算力空间。
坐标感知的 Token 化机制:维持稀疏序列下的三维拓扑结构
将密集 3D 网格压缩为变长的一维稀疏 Token 序列后,模型面临的核心挑战是如何准确恢复离散片段的空间位置关系。为此,SimArt 引入了坐标感知的序列化策略。每个被占据的体素均被编码为结构化三元组:<voxel> [xyz] [K]。其中,<voxel> 为起始标识,[xyz] 显式注入线性化后的绝对空间坐标,[K] 表示局部离散几何特征。该设计使 MLLM 能够直接解析稀疏序列中的空间位置信息,从而精准执行细粒度的几何推理与复杂的运动学拓扑构建。
4. 实验效果
为了全面验证 SimArt 的实际性能,我们在结构化铰链参数预测与细粒度 3D 语义部件定位两个核心任务上,与当前主流的生成式大模型及多级流水线方案进行了严谨的定量与定性对比。
为了系统评估 SimArt 的实际性能,我们在结构化运动学参数预测与细粒度 3D 语义部件定位两个核心任务上,与当前主流的生成式大模型及多级流水线方案进行了定量与定性对比。

运动学精度与几何保真度对比
我们在域内数据(PartNet-Mobility)与域外数据(多样化 AI 生成物体)上,将 SimArt 与当前主流的物理资产生成框架(如 Articulate-Anything, PhysX-Anything, Particulate 等)进行了对比测试。实验结果如下:
稳定的 SOTA 性能表现:在关节类型分类准确率(Type Accuracy)、关节轴/原点误差(Axis/Origin Error),以及反映几何重建质量的 IoU 与 Chamfer Distance(CD)等关键指标上,SimArt 均优于对比基线模型。 良好的 OOD 泛化能力:面对拓扑结构多样的"未见过的 AI 生成物体",部分生成式基线模型在几何重建质量上出现明显下降(IoU 降低)。而 SimArt 凭借对原始网格的高保真稀疏编码,仍保持了 0.831 的关节分类准确率和 0.777 的 IoU,展现出较强的跨域泛化能力。
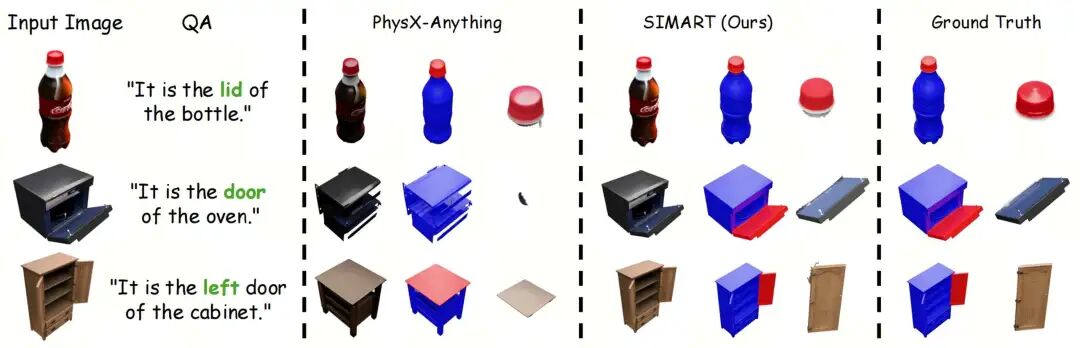
3D 部件功能语义定位(QA Grounding)
为评估模型对 3D 场景的语义理解能力,我们设计了基于自然语言描述(如"瓶子的盖子"、"柜子的左门")的 3D 部件定位任务:
有效的跨模态空间定位:面对结构复杂的未知几何体,SimArt 能够准确识别并分离出目标功能部件,在该任务上取得 0.807 的 IoU,几何误差(CD)为 0.018,性能优于 P3SAM+VLM 级联方案与 PhysX-Anything 等对比方法。 几何与语义的协同建模:实验表明,坐标感知的稀疏 Token 表示有助于增强 MLLM 对 3D 几何结构与语义信息的联合建模能力,使模型能够基于物理属性与功能常识,更准确地理解部件在 3D 空间中的角色与关系。
5. 结语与未来展望
SimArt 结合稀疏 3D VQ-VAE 与统一的多模态架构,有效缓解了传统静态网格向铰链资产转换过程中面临的计算资源限制与多阶段误差累积问题。
此外,该方法可为 Real-to-Sim 迁移提供更可靠的仿真资产,并为机器人视觉-语言-动作(VLA)模型及通用物理世界模型的训练提供结构一致、物理合规的交互数据。我们期望 SimArt 能够进一步推动具身智能在复杂动态环境中的感知、规划与控制能力的持续演进。
推荐阅读 :