TerminalTraj团队 投稿
量子位 | 公众号 QbitAI
被ICML 2026接收为Spotlight!
至知创新研究院、曼彻斯特大学、Multimodal Art Projection Research Community等共同提出TerminalTraj——
一个面向终端智能体的大规模轨迹生成管道(pipeline)。

TerminalTraj从真实GitHub仓库出发,自动构建Docker化的可执行环境(Dockerized execution environments),生成与环境对齐的终端相关的任务(terminal tasks) ,并通过可执行的检验代码(executable validation code) 验证Agent是否真正完成任务。
最终,TerminalTraj构建了32K Docker镜像,并生成50733条已经验证了的终端轨迹,覆盖八类常见编程语言和八个特定的终端领域。
实验显示,使用TerminalTraj数据训练的Qwen2.5-Coder系列模型在TerminalBench 1.0和TerminalBench 2.0上获得稳定提升,并展现出更好的test-time scaling能力。
Terminal Agent缺的不是更多“文本数据”,而是能跑、能验的真实环境
CLI Agent正在从代码补全工具走向真实软件工程中的执行型智能体。
它们不仅要生成代码,还要在终端中安装依赖、运行测试、调试错误、修改配置、调用工具,并根据环境反馈持续修正行为。
当前很多Agent相关的数据构造方法可以生成大量任务描述和交互轨迹,但终端相关的任务有一个特殊难点:
任务是否完成,往往不能只靠文本判断。
例如,一个终端Agent可能需要安装依赖、修改配置文件、启动web service、处理CSV/JSON/Parquet数据、编译 C/C++项目,或者在QEMU中完成系统启动。
这些任务的成功与否,取决于真实文件系统状态、依赖解析、命令执行结果和工具调用副作用。
也就是说,终端Agent的训练轨迹必须同时满足两个要求:
第一,可执行性(Executability)。
任务必须处在一个真实可运行的环境中,Agent的操作需要能够被实际执行。
第二,可验证性(Verifiability)。
Agent的最终结果必须能被可执行验证逻辑检查,而不是只依赖LLM judge或规则启发式判断。
没有Docker环境,任务很难真实执行;没有可执行的验证,轨迹也很难保证真的解决了问题。
这也使得CLI/Terminal任务的训练数据构造构造面临一个核心瓶颈:
大规模、高质量、可执行、可验证的终端环境(terminal environments) 在开源生态中仍然非常稀缺。
这不仅限制了终端相关的Agent轨迹数据的构造,也限制了后续SFT、RL以及test-time scaling能力的提升。
为了解决这一问题,TerminalTraj应运而生。
TerminalTraj的核心目标,就是把大量真实开源仓库转化为可执行、可验证、可扩展的终端Agent训练数据。
TerminalTraj:把真实GitHub仓库转化为可执行终端轨迹
TerminalTraj的pipeline主要包含三个阶段。
首先,TerminalTraj从GitHub大规模收集真实开源仓库,覆盖Python、C++、C、Java、JavaScript、PHP、HTML和Go八种常见编程语言。
与普通训练语料不同,TerminalTraj更关注包含Dockerfile、build scripts、Markdown文档和shell scripts的仓库,因为这些内容不仅是静态代码,更是构建可执行环境和生成terminal tasks的关键线索。
其次,TerminalTraj将仓库的选择转化为基于模型的质量评分问题。真实GitHub仓库非常嘈杂,很多项目不完整、不可运行,或者Docker环境构建失败率很高。
为此,TerminalTraj训练了一个ScoreModel,根据代码文件的完整性、可执行性和工程质量对仓库进行打分,从而筛选出更适合构建Docker环境的高质量项目。
最终,TerminalTraj构建出32325个Docker镜像。
最后,TerminalTraj基于这些Docker环境生成 环境对齐的终端任务和可执行的验证代码。
这里的关键不只是让LLM生成一个任务描述,而是让任务与具体环境强绑定。
例如,任务可能要求Agent运行某个脚本、修复某个配置、生成指定输出文件、启动服务,或者处理特定输入数据。
Agent完成任务后,系统会在Docker环境中运行验证代码,检查最终文件、配置、输出或程序行为是否正确。
只有通过验证的轨迹,才会被保留下来作为训练数据。
这一步有效避免了一个常见问题:
Agent看起来完成了任务,但真实环境状态并没有被正确改变。

从90万仓库到5万条verified trajectories
TerminalTraj的数据构建规模如下:
收集899,741个GitHub仓库; 收集2,010,113个代码文件; 构建32,325个Docker镜像; 生成超过1M个任务实例; 最终保留50,733条验证通过的终端轨迹。

这些verified trajectories不仅覆盖general programming tasks,也覆盖八类特定的终端领域(specialized terminal domains)。
包括环境交互(Environment Interaction)、多模态(Multimodal)、安全(Security)、数据处理(Data Processing)、模型训练和评估(Model Training&Evaluation)、SQL数据库(SQL)、网页服务(Web Service)和QEMU相关的任务 (QEMU-related tasks)。
这说明TerminalTraj并不是在生成简单的代码执行任务,而是在构建更接近真实terminal工作流的多样化训练数据。
真实终端任务往往涉及服务启动、端口检查、系统配置、数据处理、多模态输入、安全分析和模拟器操作等复杂场景。只有覆盖足够多样的Docker化的环境,模型才能学到更稳健的Agent行为。
实验:TerminalTraj显著提升TerminalBench表现
为了验证数据有效性,论文使用TerminalTraj数据对Qwen2.5-Coder系列模型进行多轮SFT微调,并在TerminalBench 1.0和TerminalBench 2.0上评估。
结果显示,TerminalTraj在7B、14B和32B三个规模上都带来稳定提升:
Qwen2.5-Coder-7B基座在TB 1.0/TB 2.0上为6.25/0.00;TerminalTraj-7B提升到23.01/10.10。 Qwen2.5-Coder-14B基座为6.25/1.18;TerminalTraj-14B提升到28.91/19.10。 Qwen2.5-Coder-32B基座为5.00/4.49;TerminalTraj-32B提升到35.30/22.00。
也就是说,TerminalTraj让Qwen2.5-Coder基座在TB 1.0上获得超过20个点的绝对提升,在TB 2.0上获得超过10个点的绝对提升。
更重要的是,TerminalTraj-32B不仅超过了多个30B级别的开源模型,还达到了接近Qwen3-Coder-480B的表现。
这说明高质量基于可执行环境的轨迹(execution-grounded trajectories) 可以显著提升小规模模型的终端Agent能力。

TerminalTraj不只是提升准确率,也改善test-time scaling
终端Agent在真实任务中经常依赖多次尝试和自我修正。
因此,除了单次成功率,test-time scaling也非常重要:
当采样数量增加时,模型是否能更有效地把额外推理计算转化为更高成功率?
论文在TerminalBench 1.0上评估pass@k,k从1增加到16。
结果显示,原始Qwen2.5-Coder基座的pass@k曲线较平,尤其是7B模型,即使增加采样次数,收益也有限。
这说明当模型缺少终端交互能力时,简单多采样并不能显著解决问题。
相比之下,TerminalTraj系列模型展现出更强、更稳定的test-time scaling。
随着k从1增加到16,TerminalTraj模型的pass@k持续提升。
TerminalTraj-32B的pass@16达到约63%,并且在多数设置下超过了更大的Qwen3-Coder-480B。
这说明TerminalTraj学到的不只是某些固定任务的解法,而是更通用的终端问题解决行为:
观察环境、执行命令、解释反馈、自我修正,并在多次尝试中找到可行路径。

为什么executable verification很重要?
一个自然问题是:
为什么一定要用代码验证?能不能让LLM judge判断轨迹是否成功?
论文比较了两种轨迹筛选方式:
LLM-verified:让GPT-5.1判断轨迹是否成功; Code-verified:只保留通过可执行验证代码(executable validation code)的轨迹。
结果显示,在1K、2K、4K和8K不同训练规模下,使用Code-verified轨迹训练的模型都稳定优于LLM-verified轨迹。
尤其在数据规模较小时,code-based verification的优势更加明显。
这说明终端轨迹的质量不能只靠“看起来合理”。
很多终端任务的成功标准隐藏在环境状态里,例如某个文件是否真的生成、某个服务是否真的启动、某个配置是否真的生效。
只有执行验证代码,才能过滤掉“表面成功但实际失败”的轨迹。
对于终端Agent训练来说,基于代码的验证本身就是数据质量的核心组成部分。

此外,团队进一步持续扩展 Code-verified轨迹的数据规模,并观察到即使训练数据增加到全集规模时,模型性能依然保持稳定提升。
这表明TerminalTraj构造的数据不仅具有较高质量,还具备良好的扩展潜力,能够持续为终端Agent能力提升提供有效监督信号。

规模不是唯一关键,可执行的环境更重要
与现有规模接近的数据集Nex-N1相比,TerminalTraj使用更少的轨迹和更弱的基座模型,却带来了更大的TerminalBench提升。
在TB 1.0和TB 2.0上,TerminalTraj相比基座的提升幅度分别达到Nex-N1对应提升的1.7倍和1.3倍。
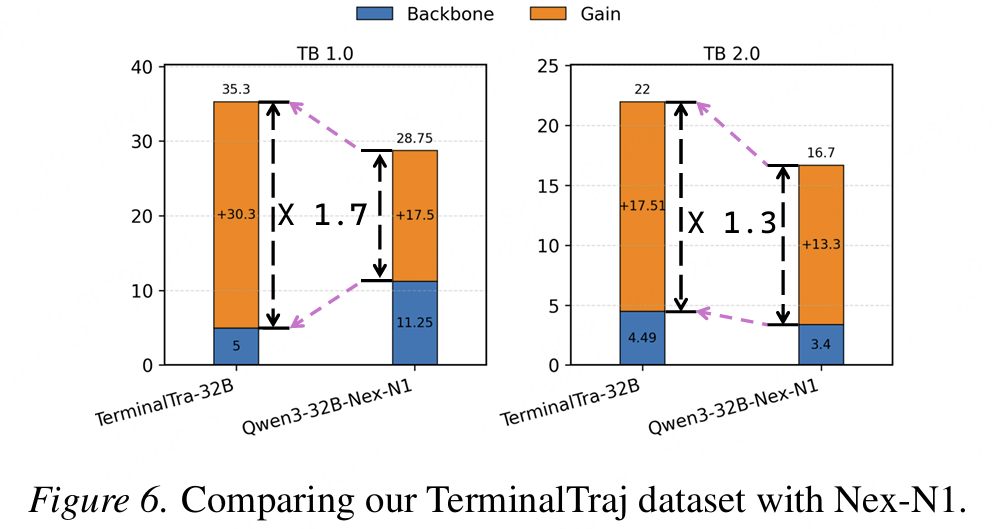
这说明终端Agent数据构造的关键不只是“生成更多轨迹”,而是轨迹是否来自真实可执行环境,是否经过可执行验证,是否覆盖多样化工具与环境依赖。
同样,SETA证明了多样化Docker化的环境可以改善test-time scaling,但其环境规模有限。
TerminalTraj将这一方向扩展到32K Docker化的环境,并通过自动化管道生成大规模环境对齐的轨迹,从而进一步释放模型的test-time scaling潜力。

小结一下
TerminalTraj的意义不只是构建了一个更大的终端轨迹数据集,而是提出了一条面向生产级CLI Agent训练的可扩展路径。
随着Claude Code、Codex等CLI Agent逐渐进入真实开发、调试、部署和运维流程,模型需要具备的不再只是代码生成能力,而是在真实终端环境中执行命令、理解反馈、修复错误并完成任务的终端问题解决得能力。
TerminalTraj表明,提升终端Agent能力的关键,不只是让模型读取更多代码文本,而是让模型进入真实可执行环境,在任务中尝试、失败、修正,并从可验证的交互轨迹中学习。
通过32K Docker化的环境和50,733条code-verified轨迹,TerminalTraj为这一方向提供了大规模、可执行、可验证的数据基础。
更重要的是,它揭示了终端Agent训练的核心瓶颈正在从“有没有足够多的代码”转向“有没有足够真实、可执行、可验证的环境与轨迹”。
论文由吴思为、李一之、宋宇阳共同一作完成,通讯作者为Bryan Dai和林成华。
项目由曼彻斯特大学、IQuest Research、Multimodal Art Projection Research Community、四川大学和北京航空航天大学联合完成。
arXiv论文: http://arxiv.org/abs/2602.01244
GitHub开源代码: https://github.com/multimodal-art-projection/TerminalTraj
注:至知创新研究院(IQuest Research)立足人工智能前沿,是由深厚产业智慧驱动的新型科研组织,核心破解尖端研究与规模化产业落地的产学研难题。
IQuest以原创性底层算法与下一代AI架构攻坚为基石,聚焦前沿技术突破、高复杂度场景落地、全球产学研生态协同三大核心目标。
IQuest以产业一线核心瓶颈锚定研究方向,为顶尖科研人才提供纯粹的探索环境。同时,IQuest深耕AI+科学计算、前沿科技等核心垂直领域,以卓越的学术能力与极致的工程精神,深耕技术本源,释放 AI 全维度深层价值。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟










