香港中文大学(深圳)等团队 投稿
量子位 | 公众号 QbitAI
多智能体系统要继续涨性能,不一定非得先改工作流。
在真实部署里,医疗诊断SOP、金融审计流程这类多智能体系统,往往已经经过专家设计、安全验证和合规审查,一旦上线,拓扑结构很难随意调整。
但工作流固定,不代表优化空间就消失了。
真正还能动、也最直接影响系统表现的,变成了每个Agent的Prompt配置。
问题是,MAS Prompt优化并不简单:
每次评估都要完整跑一遍多智能体流程,上游Agent的Prompt变化还会影响下游输入分布,联合搜索空间也会随着Agent数量指数级膨胀。
针对这一问题,香港中文大学(深圳)、香港科技大学(广州)、华南理工大学和立命馆大学的研究团队提出了MASPOB(Multi-Agent System Prompt Optimization via Bandits)。
一个基于Bandit的样本高效Prompt优化框架,且该工作已被ICML 2026接收为Spotlight。

固定工作流里,Prompt成了最关键的优化入口
近年来,以LLM为核心的多智能体系统快速发展。通过将复杂任务分解为多个专业Agent之间的协作交互,多智能体系统在代码生成、数学推理、问答等任务上展现出超越单模型的性能。
研究表明,系统表现不仅取决于底层LLM的能力,还受到工作流拓扑结构与各Agent Prompt配置的显著影响。
然而在许多真实部署场景中,MAS的工作流拓扑往往经过了专家设计、安全验证和合规审查,例如医疗诊断SOP、金融审计流程,一旦投入使用便难以随意修改,任何结构调整都可能触发高代价的重新验证程序。
在这种固定拓扑的约束下,调整各Agent的Prompt成为改善系统性能的关键手段,这引出了本文的核心问题:
在固定工作流拓扑的条件下,如何高效地对MAS中各Agent的Prompt进行联合优化?
研究团队将该问题形式化为一个有预算的组合黑盒优化问题。
在多个Agent中,每个Agent都有一组候选Prompt。目标是在最多评估T次的限制内,找到一组表现最好的Prompt组合,让整个系统在验证集上的效果最优。
这一问题的难点体现在三个方面:
评估代价高昂:每次评估一套Prompt组合,需要完整执行MAS流程,涉及多次LLM调用,可用评估次数极为有限。
拓扑诱导的耦合:上游Agent的Prompt变化会影响下游Agent的输入分布,各Agent的Prompt并非相互独立,导致优化目标不可分离。
组合搜索空间爆炸:联合搜索空间为各Agent候选集的笛卡尔积,大小随Agent数量指数增长,穷举不可行。
把Prompt搜索,变成一场有预算的Bandit问题
为应对上述三个问题,研究团队提出MASPOB算法,该算法由三个核心组件构成:

△MASPOB框架总览
首先是「拓扑感知的性能代理模型」。
为捕捉Agent间的拓扑依赖,MASPOB将MAS工作流建模为有向无环图(DAG),以各Agent的Prompt嵌入为节点特征,采用图注意力网络(GAT)进行消息传递,学习能够感知拓扑结构的Prompt语义表示。
具体地,GAT通过注意力加权聚合邻居信息来更新节点表示,最终经均值池化和MLP输出预测性能分数,作为Bandit框架中的利用(exploitation)信号。
这一设计使代理模型能够显式建模上游Prompt变化对下游Agent的影响。
以及基于Bandit的「探索-利用权衡」。
为在有限评估预算下实现样本高效的搜索,MASPOB将Prompt组合优化建模为Bandit问题,采用线性置信上界(LinUCB)构造采集函数:

该采集函数在倾向于高预测性能(利用)的同时,也对未充分探索的区域赋予更高的评分(探索),从而在有限预算内实现高效的Prompt组合搜索。
此外还包括「坐标上升搜索」。
为解决组合搜索空间的指数爆炸问题,MASPOB采用坐标上升策略,将联合优化分解为对各Agent的逐一单变量优化,由于UCB评估仅需GNN前向推理而无需实际执行MAS,每轮坐标上升的计算开销可忽略不计。
坐标上升中使用的GNN代理模型保留了对Agent间拓扑依赖的建模,因此分解并不意味着忽略耦合。
实验结果
研究团队在问答(HotpotQA、DROP)、代码生成(HumanEval、MBPP)和数学推理(GSM8K、MATH)六个基准上进行了评估,所有方法在相同的50次验证集评估预算下进行对比,backbone LLM为GPT-4o-mini。

△MASPOB在6个不同基准上的表现
如图所示,MASPOB在所有六个基准上均取得最优结果,平均得分为80.58%。
相较IO基线、AFlow、MIPRO分别提升12.02%、2.06%、1.71%,在相同的50次验证集评估预算下一致优于现有方法。
从各任务的具体表现来看,MASPOB在问答、代码生成、数学推理三类任务上均取得最优结果:
问答任务:HotpotQA达到75.43%,DROP达到82.28%。
代码生成任务:HumanEval达到94.15%,MBPP达到80.65%。
数学推理任务:GSM8K达到93.90%,MATH达到57.05%。
性能增益在三类任务上均有体现,说明MASPOB的提升并不局限于某一特定任务类型,而是来自对各Agent Prompt的整体协调优化。
拓扑复杂度的泛化性
为验证MASPOB在更复杂工作流下的泛化能力。
研究团队使用AFlow生成了拓扑更复杂的MAS结构(HotpotQA、DROP、HumanEval分别采用8、7、7个Agent,相比原始的3、2、3个Agent),在保持其余实验设置不变的条件下进行对比。
在更复杂的拓扑结构下,MASPOB在三个任务上依然取得最优结果:

△MASPOB在复杂MAS拓扑结构上的表现
HotpotQA、DROP、HumanEval上的得分分别为74.43%、81.55%、90.08%,平均得分为82.02%。
与原始拓扑下的结果相比,三个任务上的性能均有所变化(HotpotQA: 75.43%→74.43%,DROP: 82.28%→81.55%,HumanEval: 94.15%→90.08%)。
但方法间的相对排名保持不变,MASPOB在两种拓扑设置下均保持最优。
算法的收敛性
在算法的收敛性上,MASPOB在验证集和测试集上均呈现出较为稳定的收敛趋势。
验证集准确率以每五轮的分段均值(binned average)形式呈现,随评估轮次持续提升。

△验证集与测试集上的收敛曲线
测试集性能在第5、10、…、50轮各节点处,对当前所选Prompt组合进行评估并取三次独立运行的均值,两条曲线的整体走势较为一致。
从收敛过程来看,测试集性能随轮次增加呈现出前期提升较快、后期趋于平稳的规律。
具体而言,性能在前35轮内持续提升,在第35轮左右趋于稳定,此后至第50轮各评估节点的性能变化幅度相对有限。
验证集曲线与测试集曲线在整个优化过程中整体走势一致,表明验证集上的优化过程与测试集性能具有较好的一致性。
消融实验
为验证GNN代理模型在拓扑建模中的作用,研究团队将GNN模块替换为多层感知机(MLP),保持其余组件不变,对比两者的性能差异。
如图所示,去除GNN后平均性能下降2.31%,所得结果略低于AFlow(差距约0.25%)。

△GNN消融实验
从各任务的具体数字来看,GNN带来的性能差异(即MASPOB与去除GNN版本之间的差距)在各任务上有所不同:
HumanEval上为+3.82%,DROP上为+3.08%,MATH上为+3.48%,MBPP上为+1.47%,HotpotQA上为+1.05%,GSM8K上为+0.95%。
GNN在六个任务上均带来了正向提升,说明显式建模工作流拓扑结构对Prompt优化的性能具有一致的正向贡献。
△坐标上升消融实验
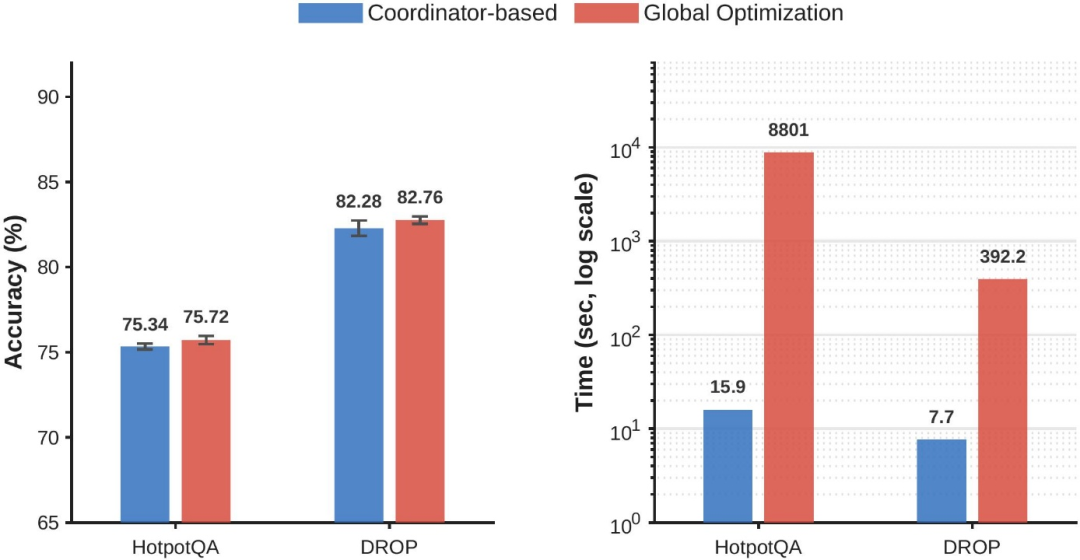
为评估坐标上升策略的有效性,研究团队在HotpotQA和DROP两个基准上,将坐标上升替换为穷举全局搜索,保持其余实验设置不变,对比两者在性能和运行时间上的差异。
如图所示,两者在性能上的差距较小:HotpotQA上坐标上升与全局搜索分别为75.43%和75.72%,差距为0.29%;DROP上分别为82.28%和82.76%,差距为0.48%。
在运行时间上,两者差异显著:HotpotQA上坐标上升耗时15.9s,全局搜索耗时8801s,前者减少99.8%;DROP上坐标上升耗时7.7s,全局搜索耗时392s,前者减少98.0%。
上述结果表明,坐标上升在性能损失较小的前提下,运行时间大幅低于穷举全局搜索。
总的来说,MASPOB真正回答的,是固定工作流下多智能体系统还能如何继续优化的问题。
从六个基准上的实验结果来看,这套方法在相同评估预算下均取得最优表现,也说明多智能体系统的性能提升,并不只来自更复杂的工作流设计。
在固定拓扑约束下,如何更系统、更高效地调好每个Agent的Prompt,同样可能成为多智能体系统走向真实应用前的一项关键能力。
参考链接:
[1]论文链接:https://arxiv.org/abs/2603.02630
[2]代码下载:https://github.com/HZ1008/MASPOB
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟