公众号记得加星标⭐️,第一时间看推送不会错过。

芯片橱窗Tensordyne 周一表示,预计其新型推理系统的订单额将超过 2 亿美元。这家人工智能芯片初创公司正将自己定位为英伟达在快速增长但日益耗能的市场中的直接挑战者。
其与博通和 HPE 旗下的瞻博网络合作开发的 Tensordyne Napier 芯片,由世界领先的芯片代工制造商台积电 (TSMC) 制造。
这家总部位于加州桑尼维尔的公司旨在通过提高推理速度、电源效率和机架密度来缓解人工智能基础设施的限制,以应对生成式人工智能需求的激增。
该公司首席执行官Marc Bolitho表示,该产品计划在未来几个月内正式发布,这家初创公司“受到了极大的关注”。
他说:“我们已经收到十几份意向书,邀请公司评估我们的测试版系统,预计未来需求将超过 2 亿美元。”
该公司表示,人工智能基础设施提供商 Cirrascale 和 BlueSky Compute,以及大型科技公司和人工智能云服务提供商都对该系统表现出了兴趣。
该公司成立于2017年,原名为Recogni,去年更名为Tensordyne。该公司已从包括Celesta Capital、GreatPoint Ventures和Juniper Networks在内的投资者那里筹集了约1.76亿美元,并正准备在今年晚些时候进行D轮融资。
从汽车到边缘AI
在去年九月,人工智能芯片初创公司 Recogni 宣布更名为 Tensordyne,并公布了其即将推出的数据中心人工智能产品的一些细节。该公司最初是一家汽车边缘芯片制造商,其第一代产品已投放市场。然而,现在它正全面转型,从边缘市场转向数据中心高效的大规模LLM代币生成。
时任Tensordyne 联合创始人兼首席产品官 RK Anand 表示,电力是超大规模数据中心、新型云以及任何拥有机架级 AI 硬件的用户面临的一个根本性问题。
“能源将成为全球人工智能发展的障碍,”他说道。“推理策略是缩小晶体管尺寸、堆叠更多HBM、集成更多GPU,但功耗却持续增长——这就是我们整个行业面临的挑战。在Tensordyne,我们正在从基本原理出发,思考如何让这些挑战更容易被行业所接受。”
Tensordyne 正在使用其开发的 Recogni 对数数方案来解决这个问题。
“人工智能本质上就是数学,”Anand 说。“任何突破性创新都将源于数学。如果我们能在数学层面解决这个问题,它就会层层递进,惠及所有层面。”
时任Tensordyne 人工智能和产品联合创始人兼副总裁 Gilles Backhus 表示, Tensordyne 的对数数学可以将人工智能的成本降低 3 到 10 倍。
“我们称之为零阶缩放定律,它与你所能做出的任何其他设计决策都无关,”他说。
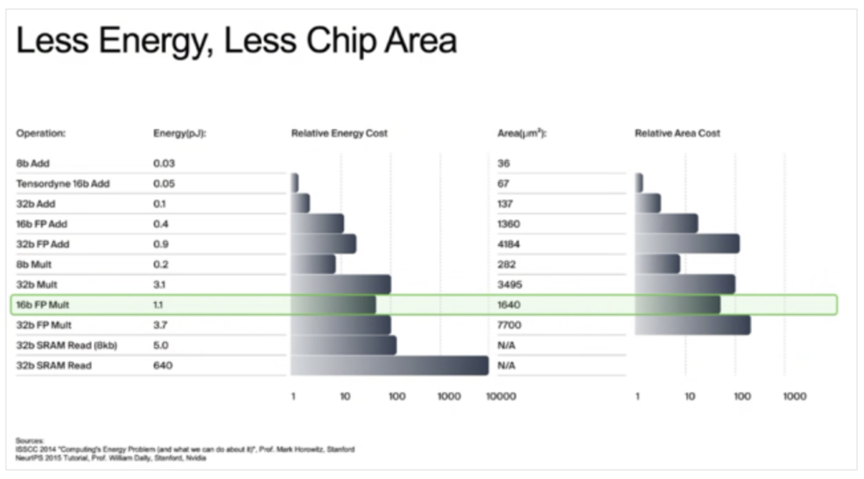
对于给定的工艺技术,传统的16位浮点乘法运算需要消耗1.1pJ的能量和1640µm²的硅片面积,而Tensordyne技术仅需0.05pJ的能量和67µm²的硅片面积即可完成,能耗降低了22倍,芯片面积缩小了25倍。Backhus表示,如果将系统级能耗考虑在内,整体效果可能达到10倍左右。
切换到对数运算还可以减少数字表示中的误差,从而提高准确性。Backhus 表示,与合作伙伴运行的视频生成 Transformer 进行的测试表明,Tensordyne 的运算结果实际上比原始算法更好,因为它允许注意力矩阵具有更高的动态范围。这项技术在数值范围较小的一端保持了数字分辨率;这些小数字累积起来,使整体输出更加准确。
该方案还包括动态自动微缩放功能(激活微缩放到矩阵中列的部分粒度级别,有点像英伟达的 Transformer Engine)。
Anand表示,大幅减少硅片面积除了成本之外,还会产生其他影响。如果相同计算量所需的面积大大减少,那么在给定芯片尺寸下,就会为SRAM腾出更多空间,从而显著影响计算与内存的比率。
“有了更多的SRAM,就能保证计算引擎的持续运行,”Anand说。“引擎运行正常,利用率就会提高。”
Tensordyne 正在研发的产品基于台积电 3 纳米计算芯片,配备 256 MB SRAM 和 144 GB HBM3e。
这些芯片将部署在风冷机架中,并采用任意互连方式,由瞻博网络 (Juniper Networks) 提供支持,每个芯片的单向互连带宽约为 460 GB/s(双向互连带宽接近 1 TB/s)。客户可以在单个域中连接 144 个芯片,从而实现高达 TP144 的张量并行性,或使用多个 MoE 专家。
Anand表示,总体而言,公司目标是使Llama3.3-70B的每个机架每秒吞吐量达到300万个代币,而每个token的资本支出仅为Nvidia Blackwell一代机架的三分之一,功耗仅为八分之一(Tensordyne的预期性能数据会随着模型规模和复杂性的增加而提升)。他还补充说,该方案还能在合理数量的并发用户下保持低延迟。
Tensordyne 的数学系统量化将作为其软件工具链的一部分实现自动化,该公司还将把其已转换模型的模型库添加到 HuggingFace 中。根据超大规模数据中心的反馈,该公司计划支持 Triton 作为前端。该公司的中间表示将完全暴露到 Python 层,以便开发人员可以根据需要进行任意程度的控制。
吊打英伟达?
如果模拟结果可信,初创公司Tensordyne的新型AI芯片在能效和推理延迟方面有望超越市场领导者英伟达。该公司刚刚提交了首款芯片的生产计划,预计将于2027年下半年开始销售包含72颗芯片的商用系统。Tensordyne声称,与配备72颗芯片的英伟达GB300系统相比,其72颗芯片的系统运行大型LLM的速度是后者的四倍,而功耗仅为后者的五分之一。然而,实际系统要到今年年底才能投入使用,届时才能验证这些数据。
Tensordyne公司新芯片Napier之所以效率极高,其背后的秘诀在于它进行矩阵乘法运算的方式,而矩阵乘法正是人工智能的核心数学运算。它利用了这样一个事实:A乘以B的对数等于A的对数加上B的对数。
“我们把乘法器改成了加法器,” Tensordyne创始人兼人工智能副总裁Gilles Backhus解释道。他表示,加法器比乘法电路体积更小、能效更高。因此,Napier可以在更小的面积内集成更多的计算能力,同时还能节省电力。
人们早就知道这种可能性,但一直没有好的方法可以利用它,因为在对数和描述神经网络的浮点数之间来回转换太耗时耗力,而且会引入太多误差。但根据巴克胡斯的说法,这种情况已经改变了。
他说:“到目前为止,还没有人像我们一样找到实现线性到对数以及对数到线性转换的方法。而这恰恰是整个问题的关键所在。我们的工程师已经找到了在硅芯片上非常优雅、非常精确且成本低廉地实现这一转换的方法。”
数字格式的重要性早已被人工智能行业所重视。英伟达首席科学家比尔·戴利在2023年的IEEE Hot Chips大会上表示,该公司GPU性能的显著提升主要归功于更短的数字格式及其所需的更小电路。
研究人员还致力于开发使用其他数据格式进行计算的电路,例如类似对数的 posit 格式,以及最近开发的用于科学计算的takum格式。然而,这些格式尚未得到主流应用,主要是因为它们的硬件实现与传统的浮点运算截然不同。
市场趋势,包括人工智能代理的兴起,意味着推理(即神经网络模型的执行)的重要性正在超过训练新的大型语言模型(LLM)。成本和响应速度等因素开始占据主导地位,这促使人工智能公司寻找更适合这种趋势的系统架构。
Tensordyne 的高管表示,他们预见到了这种情况,并对他们开发的计算机进行了相应的设计。
执行逻LL主要分为两个部分:预填充和解码。在预填充阶段,模型接收输入文本并将其转换为词元(token),即模型可以处理的基本单元,同时构建一个关于输入的工作记忆,称为键值缓存。这是一个计算量很大的任务。
解码是 LLM 生成输出词元(即对输入的答案或响应)的过程。每个新词元都是利用前一个词元和键值缓存进行预测的。这种顺序执行的特性使得解码过程较为缓慢,并且它对内存和网络延迟的依赖性高于对计算能力的依赖性。
因此,人工智能芯片制造商开始着手构建能够满足这两种不同需求的系统。英伟达正在大力推广一种系统,该系统使用一整架B300 GPU服务器机架进行预填充,并使用数架Groq 3处理器进行解码。亚马逊网络服务(AWS)则将一架Trainium人工智能芯片用于预填充,并使用数架Cerebras晶圆级计算机进行解码。
Tensordyne 表示其系统可以同时处理这两项任务。“我们正在同时优化应对两个棘手的挑战,” Tensordyne 首席产品官兼联合创始人RK Anand表示,“我们是第一家证明无需依赖多家供应商和多个机架即可完成这两项任务的公司。”
预填充所需的密集计算来自对数运算。解码所需的资源来自 144 GB 的高带宽内存和一个名为 Tensordyne Napier Link 的定制 1 微秒延迟网络。
Tensordyne公司推出的“pod”系统,体积仅为标准机架的四分之一,却集成了72颗Napier芯片、8颗英特尔至强CPU和64TB固态存储。该公司声称,一个包含四个pod的机架,运行在拥有2万亿参数的LLM(层级模型)上,能够以每百万个token11美元的成本,为每位用户每秒生成1300个token,同时消耗120千瓦的功率。其中一个pod负责预填充,另外三个pod负责解码。Tensordyne公司表示,要达到类似的每用户每秒token生成量,一个包含九个机架的Rubin和Groq 3系统可能需要消耗1.5兆瓦的功率。
这些数据是否属实,还需要等到今年晚些时候才能见分晓。Tensordyne计划通过云端向客户提供测试版,并预计在大约一年后开始向客户交付系统。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4439内容,欢迎关注。
推荐阅读
★
★
★
★
★
★
★
★

加星标⭐️第一时间看推送