「See Anything, then Do Anything —— 看见一切,进而做到一切」
我们相信,常驻型 (always-on) AI 助理的下一次飞跃,不在于把某一个模型单点调得更聪明,而在于扩展智能体的上下文 (Scaling Agent Context)—— 不断拓宽助理能够持续 "感知 — 推理 — 执行" 的范围,作为生活连接器连接用户的信息孤岛,直到它能接管用户的整个数字世界。
今天的 "助理" 大多只能看到你数字生活的一小片:一封邮件、一条指令。而一个真正的个人助理,应当像一位贴身管家 —— 看得见你散落在数月历史、十几个应用、手机与电脑之间的全部状态,听得懂没说出口的需求,并在恰当的时刻替你把事情做对。先 "看见一切", 才谈得上 "做到一切"。
这就是 Claw-Anything 想要推动的方向:Scaling Agent Context,让 Agent 全面接管用户的数字世界。
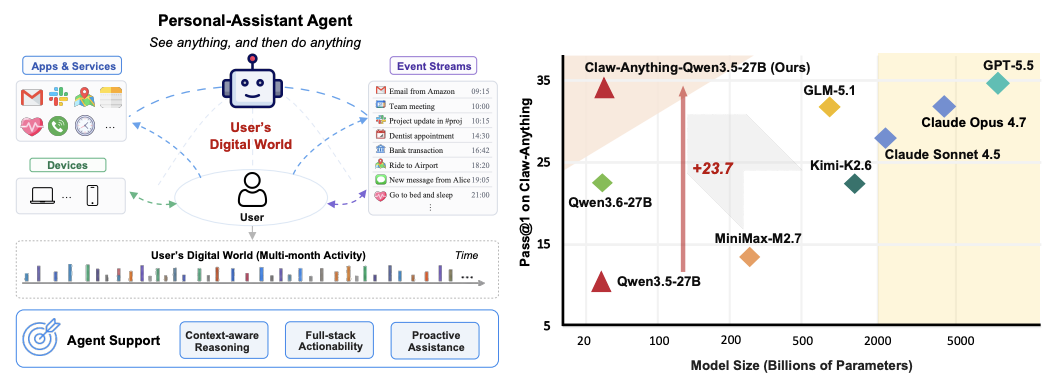
「首个面向日常个人助理 Agent、沿长程历史 × 多服务 × 多设备三维度扩展的评测基准正式发布!」
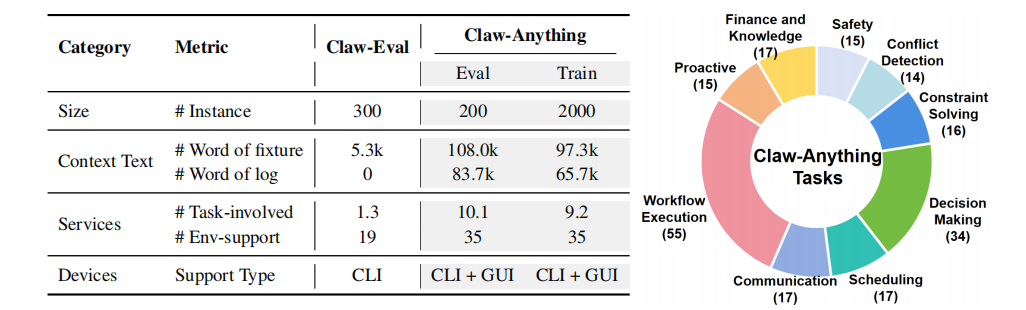
200 个真实日常助理任务,每个任务横跨 CLI 和 GUI、10 + 个应用和数月跨度 ( Scaling Context 20x )
顶尖闭源模型 GPT-5.5 通过率 (pass@1) 仅 34.5%,"最强助理" 与真实日常之间仍存巨大鸿沟
开源自动化管线,附带 2000 + 训练环境,微调开源小模型带来 23.7% 的解决率提升,开源 SOTA
将 "主动服务"(在用户开口之前替他想到) 与跨设备任务引入 Agent 评测体系

论文、管线代码和任务数据均放出:
论文链接: https://arxiv.org/pdf/2605.26086
开源代码: https://github.com/LiberCoders/Claw-Anything
任务数据: https://huggingface.co/datasets/LiberCoders/Claw-Anything
ModelScope: https://www.modelscope.cn/datasets/LiberCoders/Claw-Anything
一个例子
Rachel 是一位独立婚礼策划师,手上同时跟着 8 场婚礼。6 月 3 日早上,她丢给自己的 AI 助理一句话:
"我 6 月 4 号要跟一个企业客户开需求沟通会。我在纠结:这份会前简报,是花钱让兼职助理 Lena 来准备,还是我自己上?"
这句话听上去很简单很日常很好解决,但要答好它,助理得在 Rachel 海量的个人信息里把整盘账算清:
翻日历 app—— 发现 6 月 3 日上午卡着两场根本挪不动的硬会议:一场婚前确认电话,一场和花艺供应商的合同纠纷解决会。
读邮件 app—— 翻出 Lena 的报价 (半天 180 美元),还得发现一个藏起来的坑:Lena 要求 "周三下班前送材料",而今天就是周三,这个截止时间是很极限的,需要考虑今天有没有充足时间准备材料;
看财务 app—— 掂量这 180 美元此刻花不花得起;
往下推演 —— 如果为省钱自己硬扛、把供应商纠纷会往后拖,可能赔上一个关系到好几场婚礼的长期供应商,这笔隐性损失远不止 180 美元。
最后给出干脆的结论:交给 Lena 值。但还有一条红线 —— 它绝对不能擅自替 Rachel 发出任何一封邮件,因为 "用户的提问并没授权或明示个人助理直接处理",这超出了助理被授予的权限。
一个真正好用的助理,既要把这盘账算明白,又要懂得 "什么事不能替你做主"。问题是:今天的 AI, 真的做得到吗?
背景介绍
AI 正从 “帮你写段文案 " 的一次性工具,走向住进你数字生活、随时替你打理一切” 的常驻助理 (always-on personal assistant)。这类系统被寄予厚望:有长期记忆、能后台执行、随叫随到。
但现实是,用户的意图天然散落在整个数字世界里 —— 几个月前的历史事件、十几个互相牵连的后端服务、手机与电脑两套设备。要真正帮上忙,助理必须既能找到并 “看见” 这些分散的状态,又能在闭环里 “行动”。

然而现有评测远远跟不上这个目标。近期涌现的衡量助理 Agent 的基准,大多是干净、短程、单服务、单设备的:给一封整洁的邮件让你总结,或给一个明确指令看你能否调一次工具。这就像考驾照只考 “原地打方向盘”,从不让你上路。它们几乎无法回答:当助理被丢进嘈杂、长程、需要跨设备跨系统协调、还得拿捏分寸的真实环境里,究竟表现如何?

更关键的瓶颈在于:这样的环境极难规模化构造。它需要建模长达数月的时间线、众多互联服务、多台设备,同时保证真实与自洽 —— 长期高度依赖人工搭建,既贵又难扩展。
方案:把助理「扔进」一个万物互联的数字世界
Claw-Anything 沿三个维度,把 Agent 的可感知 / 可操作范围撑到接近真实:
长程事件流 —— 用程序模拟出一个人长达数月的连贯生活轨迹,把 “过去” 和 “现在” 打通;
互联的后端服务 —— 邮箱、日历、待办、联系人、Notion、Facebook、财务…… 牵一发而动全身,单任务平均要打通 10+ 个应用 (最多 18 个);
多设备异构界面 —— 同时覆盖手机 GUI 与命令行 CLI 的交互。
在这个世界里,我们考两类能力。一类是「你能听懂并做对吗」:像上面 Rachel 那道题,需要跨邮件、日历、财务、人脉把碎片拼成清醒判断,还要守住权限边界。另一类是「你能未卜先知吗」:比如每天早上 7 点 Agent 自动触发轮询 “帮用户快速看一眼可能的待办事项,梳理成按优先级排好,并作出建议”—— 没有明确指令,助理得主动把当天最要紧、最易翻车的事拎出来。这种主动性,正是 “贴身助理” 和 “问答机器人” 的分水岭。
1. 读邮件 log:发现近日用户反复编辑过一封草稿箱内的邮件。
2. 读邮件 app:获取这封邮件的内容,发现是准备向某博导发送的申请博士邮件。
3. 读联系人 app:获取所有可联系博导的信息。
4. 读微信 app、邮件 app、日历 app 等:获取用户的学术偏好相关信息。
5. 写 TODO、邮件 app:说明可联系博导的主要研究方向,与本人是否匹配,给出建议,并措辞草拟申请邮件但不发送等用户抉择。
6. ...
为了真实,我们覆盖 30+ 种人物画像 —— 婚礼策划师、独立音乐人、安全工程师、博士生、咖啡馆老板、自由译者…… 每个人都有自己的脾气、权限边界和一摊子糟心事。而且环境里满是噪声:绝大多数信息与当前任务无关,有些甚至互相矛盾,专门等着把模型带偏。
Pipeline:让「出题的机器」模拟连续的日常生活,造出数字人生
Claw-Anything 不止是一个 benchmark,同时也是一套数据生产工厂。
我们把 “构造数字世界” 重新建模成一个可自动滚动的过程:只需给定一个人物的极简设定,一个以 LLM 为核心的模拟器就会像滚雪球一样,从种子事件池里反复采样、逐轮注入,一点点把这个人的数字生活 “养” 出来 —— 邮件越攒越多、人物画像越来越立体、世界状态越来越复杂,连带着以假乱真的无关与矛盾噪声。
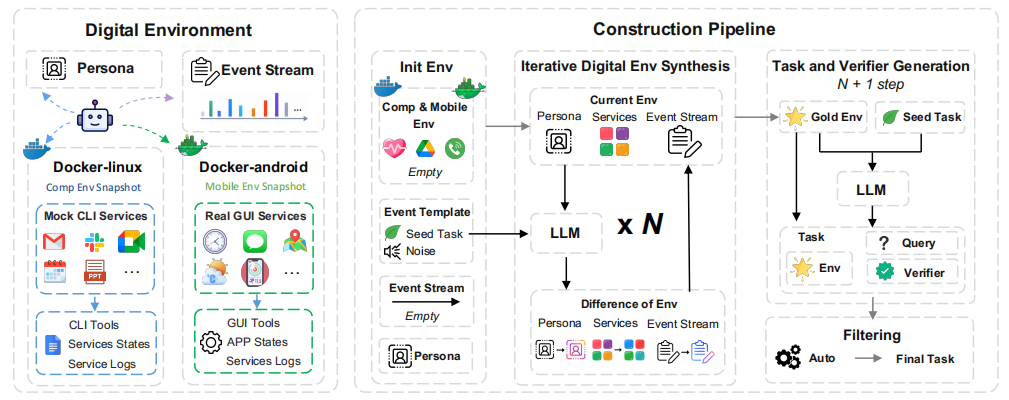
当世界足够丰满,流水线就把 “下一个该发生的事件” 实例化成一道有人物背景、有标准答案、有可执行验证器的任务 —— 评测因此变成了 “在一段不断演进的数字人生里,替主人走好下一步”。整个过程无需人工参与,只消耗算力,因此既能产出供人工复核的高质量评测题,也能海量生成训练环境。
产出:规模化与高质量并存
基于这套管线,Claw-Anything 一边产出 200 个人工验证的评测任务,一边自动生成 2000 个训练环境。
与以往同类基准相比,这些任务的 “真实密度” 高出一个数量级:平均每个任务横跨 10.1 个互联服务 (最多 18 个)、上下文长达 191.7k 字,并且是业界第一个同时覆盖 CLI 与 GUI、且把主动服务纳入评分的基准。模型不再能靠 "猜一个干净答案" 蒙混过关,而必须真正读懂分散在数月历史与十几个应用里的状态,才能完成任务。
实战效果:一面照出差距、也指明出路的镜子

我们把市面上最强的模型挨个拉来考,结果发人深省:
即便是 GPT-5.5, 通过率也只有 34.5%。大量在以往 "干净考场" 里高分的模型,一旦进入真实嘈杂、需要长程推理和分寸感的环境,三分之二的任务都栽了 —— 它们会漏看那条 “截止时间已过” 的关键邮件,算不清拖延一场会议的隐性代价,甚至越权替用户把邮件发出去。
但我们没有止步于 “出了一张难卷子”。用自动生成的训练环境去微调开源模型 Qwen3.5-27B,效果立竿见影:
任务成功率提升 23.7%!
这意味着 Claw-Anything 不只是一把量出问题的尺子,更是一台能源源不断造燃料、把模型推向更可靠的发动机 —— 发现问题和解决问题,在同一套系统里闭环了。
消融实验:Claw-Anything 究竟揭示了什么问题
为了搞清楚到底是什么让任务变难,我们把环境拆开做了一系列消融实验,结果有些反直觉,却特别说明问题。
1. 给模型看得越多,它反而做得越差。
这听起来不合常理,但数据很诚实 —— 我们让 Agent 能翻的历史越长、要打通的 App 越多、环境里掺的无关噪声越重、人物画像越立体、信息之间的矛盾越多…… 每加一分 "真实", 成功率就掉一截,而且是稳定地、单调地往下掉。一方面,这证明我们造的世界确实在逼近真实生活的复杂度;另一方面,也戳破了一个幻觉:今天的模型并不是 "上下文越大就越聪明", 面对一整个数字人生,它们还远没学会从海量信息里精准捞出那几条真正要紧的线索。
2. 能看到一切,但不一定能 “看” 到一切。
在 CLI 任务上,GPT-5.5 和 Claude Opus 4.7 是绝对王者,双双冲到 40 分档,把一众开源模型甩在身后。
但剧情在 "上手机" 那一刻反转了,在评测 GUI+CLI 任务的时候,Claude 系列断崖式崩塌:Opus 4.7 从 CLI 上的 40 分跌到 GUI+CLI 的 7.3 分,Sonnet 4.5 更是只剩 6 分,几乎不会 “看” 手机。
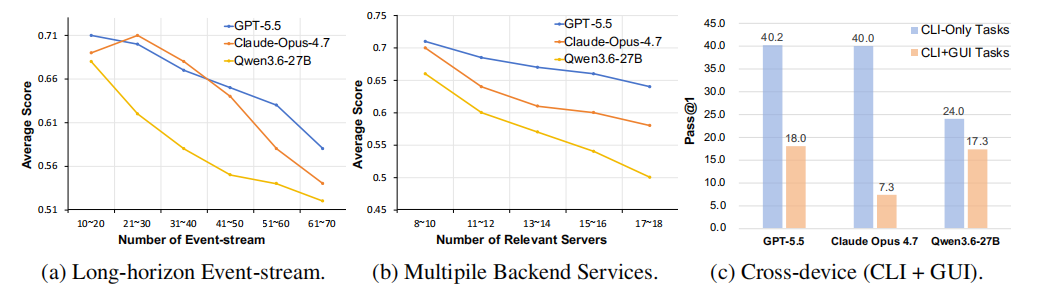
3. "看见一切" 不是锦上添花,是生死线。
我们试着把三个维度逐一 "拔掉": 一旦不让助理读历史事件流,大量任务直接做不出来;一旦屏蔽掉跨 App 协作的能力,成功率几乎归零;一旦只给电脑、不给手机,那些需要手机操作的任务也基本全军覆没。换句话说,只要少看了用户世界的一个角落,一整类任务就彻底无解 —— 这正是我们反复强调 "See Anything" 的原因:先看得全,才谈得上做得对。
4. "主动" 比 "被动" 难得多。
让助理回答你明确提出的问题是一回事;让它在你还没开口时,主动发现 "这件事你今天该处理了", 完全是另一个难度。实验里,主动类任务的成绩明显低于被动响应类 —— 这也指明了下一代助理最该补的一课:从 "有问必答" 走向 "未问先知"。

结语
我们正站在一个转折点:AI 越来越像一个住进你数字生活、随时替你打理一切的助理。越是贴身,越马虎不得 —— 它得看得够全、想得够远、还守得住分寸。Rachel 那道关于 "180 美元值不值" 的小题,背后是每个普通人都会遇到的真实困境;人可以通过回忆与权衡来做出符合当下的选择,而 AI 能不能答好,决定了我们到底敢不敢把生活交给它。
Claw-Anything 想做的,就是诚实地丈量这段距离,并亲手为跨越它铺下第一段路 —— 它既是一个足够难的基准,也是一套可持续的数据基础设施。这条路才刚刚开始,而我们已经在上面了。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com