
想用一段视频从多个视角观察同一个场景,却发现每换一个视角,视频里的人就 "变脸" 了 —— 短发变长发、左跳变右跳?想为 4D 重建提供多视角监督,但不同轨迹串行推理的结果始终 "对不上号"?试想一下,如果只需给定一段输入视频和几组目标相机参数,就能一次性并行生成多条视角一致的视频,并且能反投影出完整精细的动态 3D 点云,这不正是视频世界模型迈向真正空间智能的关键一步?
如今,CameraSquad 的出现,让这种多视角一致的视频生成与 3D 世界状态构建成为现实。
近日,中国科学院大学高林研究员团队联合卡迪夫大学、香港科技大学和快手可灵团队,提出了一种面向多轨迹并行生成的相机可控视频生成方法 CameraSquad [1],相关论文已被 ACM SIGGRAPH 2026 录用。
该方法基于 Wan2.2 视频扩散模型,构建了一个支持多轨迹并行生成、兼具精确相机控制与跨视角内容一致性的视频生成框架。给定一段输入视频和多组目标相机参数,CameraSquad 能够一次性并行生成多条空间一致的视频,为 4D 重建等下游空间智能任务提供高质量的 3D 世界状态。

图 1 CameraSquad 多轨迹生成示例

图 2 多视角内容一致的点云反投影结果
Part 1 研究背景
近年来,相机可控视频生成已成为视频生成与空间智能领域的重要研究方向。现有工作大体可分为隐式控制与显式建模两类:前者包括利用 Plücker 坐标建模相机轨迹的 CameraCtrl [4]、基于外参矩阵进行运动控制的 MotionCtrl [5]、引入极线注意力增强几何对齐的 CamCo [6],以及支持用户绘制路径或通过相机注意力实现精确运镜的 Direct-a-Video [14] 和 ReCamMaster [8];后者则包括从单图恢复 3D 结构并渲染新视角的 ViewCrafter [7],以及利用 3D 点云缓存维护世界状态的 Gen3C [2]。
这些方法推动了相机可控视频生成的发展,但仍普遍依赖单轨迹串行推理,难以在一次生成中同时保证多条轨迹的效率、相机精度与跨视角内容一致性。
这一限制会直接影响下游空间智能任务。4D 重建依赖多视角视频提供监督信号,若不同轨迹之间存在外观、位置或几何不一致,误差会在重建过程中累积并削弱最终质量;VR/AR 等沉浸式应用同样要求稳定的空间连续性,视角间内容冲突会破坏沉浸体验,并可能误导后续感知模块。同时,相机控制信号的引入还需要避免削弱视频扩散模型原有的生成质量。因此,如何同时实现精确运镜、多轨迹一致和高质量生成,仍是该方向的关键难题。
Gen3C [2] 与 VerseCrafter [3] 分别通过 3D 点云缓存和 4D 几何控制尝试维护统一世界状态,但仍未摆脱串行推理范式。其核心问题在于,每条轨迹都相对独立地推断同一个世界,轨迹之间缺乏充分的信息交互,因而容易出现同一主体在不同视角下外观、位置或动作状态不一致的问题。CameraSquad 不再依赖生成后的补救,而是在并行推理过程中引入双模式跨视角注意力,使多条目标相机轨迹能够共享内容与几何信息,从机制上提升多视角一致性,并为 4D 重建与空间智能任务提供更可靠的视频先验和 3D 世界状态。
Part 2 算法原理
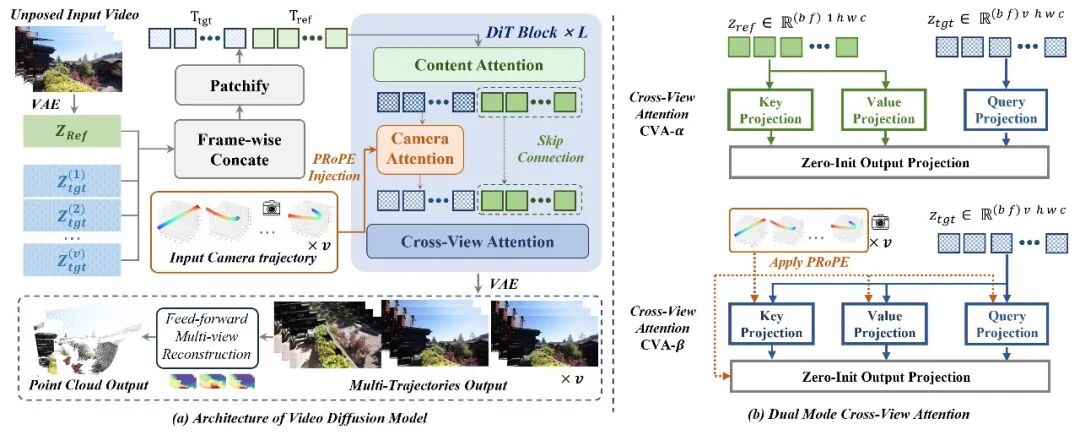
CameraSquad 基于 Wan2.2 视频扩散模型,核心思路是让多条轨迹在并行推理中对同一三维世界保持一致的空间感知。整个框架围绕两个关键设计展开。
第一个设计是相机与内容的解耦注意力。在世界模型里,世界是什么和从哪里观察世界是两类本质不同的信息,混在一起处理会互相干扰。CameraSquad 把 DiT 中原有的 3D 自注意力改造为内容注意力(Content-Attention),专门负责输入视频的内容参考 —— 输入视频 token 与加噪目标 token 按帧拼接后通过自注意力交互,实现目标与参考内容之间的有效交叉学习。另建一条空间注意力通路(Camera-Attention),用 PRoPE [10] 机制将相机内外参数编码进注意力变换矩阵。PRoPE 的独特之处在于,它不是把相机参数压缩成一串 1D 数值,而是将特征维度分为三段:前半段编码 3D 几何投影关系(利用相机内参矩阵与视图矩阵构建的投影矩阵 P),后两段分别编码 2D 旋转位置嵌入沿 x 轴和 y 轴的位置信息。
这意味着模型在注意力层面直接感知 3D 空间中的相对观察位置 —— 也即两个相机视锥体之间的投影几何关系,而非简单的数值编码。这条通路通过零初始化的投影层注入主干,训练时冻结参数,既注入了空间控制能力,又不损害模型原本的生成能力。
第二个设计是双模式跨视角注意力。串行推理之所以不一致,是因为每条轨迹都在独立猜测同一个世界,缺乏信息交互。双模式跨视角注意力正是为了让多条轨迹在并行推理中 "互通有无",共同看清同一个世界。CVA-α 解决内容一致性:参考视频 token 提供 Key 和 Value,各轨迹的加噪 token 作为 Query,通过 reshape 让同一帧不同视角的 token 相互可见 —— 同一时刻、不同视角的像素级信息在注意力层面共享,确保不同视角下对同一物体的外观理解一致,谁也不用自己猜对方长什么样。CVA-β 解决几何一致性:把 PRoPE 空间注意力从沿帧维度调整为沿视角维度计算,让多视角间的几何监督直接参与注意力运算,增强相机精度和跨视角几何一致。简单说,CVA-α 管 "看起来一样",CVA-β 管 "位置也对得上",两种模块交替插入偶数 DiT Block,共同构建多视角空间一致感知能力。
此外,获得多视角一致结果后,CameraSquad 用 DA3 [11] 进行深度估计并反投影生成动态点云。相比单视角反投影,多视角融合的点云更大更精细,还能通过时间维度捕捉场景动态,为下游空间智能任务提供高质量的 3D 世界状态。训练上研究团队采用两阶段方案:第一阶段在低分辨率训练单轨迹空间控制,让视频模型先学会感知相机控制条件;第二阶段引入 CVA 支持多轨迹并行生成,升至原分辨率。此外,研究团队还引入了噪声注入策略来缓解合成训练数据与真实数据之间的域差异问题。
Part 3 效果展示
图 4 单轨迹视频生成的定性对比结果
在 WebVid [12] 和 HumanVid [13] 数据集上,CameraSquad 与 ReCamMaster、TrajectoryCrafter、Gen3C 的对比表明,CameraSquad 在相机控制精度上全面领先:在 WebVid 数据集上旋转误差低至 1.52°、位移误差仅 2.86,在 HumanVid 数据集上旋转误差进一步降至 1.42°、位移误差 3.47,均为所有方法最低。像素匹配度指标 MPI 和 MPO 也达到最高值,直观反映了跨视角内容一致性和下游反投影点云的匹配质量。
视觉质量方面,FID、FVD 和 CLIP-V 等指标也达到竞争力水平,特别是 HumanVid 数据集上的 FID 30.78 和 CLIP-V 91.37 均显著优于所有对比方法,说明空间控制的引入并未损害生成质量,反而有所提升。VBench 评测中,CameraSquad 在美学质量、成像质量、运动平滑度、背景一致性和主体一致性五项关键指标上均取得最佳表现,特别是在 HumanVid 数据集上,运动平滑度 0.9891、背景一致性 0.9313、主体一致性 0.9260,全面超越 ReCamMaster、TrajectoryCrafter 和 Gen3C。
在 WebVid [12] 和 HumanVid [13] 数据集上,CameraSquad 与 ReCamMaster、TrajectoryCrafter、Gen3C 的对比表明,CameraSquad 的旋转误差和位移误差均最低,相机控制精度最高;FID、FVD 和 CLIP-V 等视觉质量指标也达到竞争力水平,说明空间控制的引入并未损害生成质量。VBench 评测中,CameraSquad 在美学质量、成像质量、运动平滑度、背景一致性和主体一致性上均取得最佳表现。
图 5 多轨迹并行生成的定性对比结果
多轨迹并行生成是 CameraSquad 最大的优势所在。如图 5 所示,不同轨迹生成的视频中同一物体在不同视角下外观、纹理和位置始终一致,符合同一物理世界在不同观察角度下应保持一致的基本要求。而其他方法的串行推理结果则出现了明显的跨视角不一致。

图 6 更多定性对比结果
CameraSquad 支持最多 6 条轨迹的同步生成,在人体视频和风景视频上均稳定输出一致结果。
Part 4 结语
视频生成正在从生成画面走向构建世界模型,空间智能是这一转变的核心要求。传统方法只能一条轨迹一条轨迹地串行推理,扩散模型的自由发挥让不同视角下的同一个世界 "各自为政",单视角点云反投影也只能勉强补救,深度误差和稀疏性让 3D 世界状态打了折扣。CameraSquad 的出现改变了这一现状。它通过解耦的空间与内容注意力实现精确相机控制,借助双模式跨视角注意力赋予模型多视角一致感知能力,并通过多视角深度估计反投影构建更完整的 3D 世界状态,让视频世界模型真正具备了对同一三维世界在不同观察角度下保持一致理解的关键能力。
只需给定一段输入视频和多组目标相机参数,CameraSquad 即可一次性并行生成多条空间一致的视频,为 4D 重建、场景理解、自动驾驶等空间智能任务提供更高质量的 2D 先验和 3D 世界状态。正如 Gen3C 用 3D 缓存维护世界状态、VerseCrafter 用 4D 几何控制统一动态表达,CameraSquad 用跨视角注意力确保空间一致感知,共同推进视频世界模型迈向空间智能。
有关论文的更多细节,及论文、视频、代码的下载,请浏览项目主页:
https://rabberk.github.io/CameraSquad/
参考文献
[1] Zhufeng Xu, Xuan Gao, Bailin Deng, Yikang Ding, Xiaogiang Liu, Haoxian Zhang, Pengfei Wan, Hongbo Fu, Lin Gao, CameraSquad: Achieving Content Consistency in Parallel Multi-Trajectory Camera-Controlled Video Generation, ACM SIGGRAPH 2026.
[2] Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, Jun Gao, Gen3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control, CVPR 2025, 6121-6132.
[3] Sixiao Zheng, Minghao Yin, Wenbo Hu, Xiaoyu Li, Ying Shan, Yanwei Fu, VerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control, arXiv preprint arXiv:2601.05138..
[4] Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, Ceyuan Yang, CameraCtrl: Enabling Camera Control for Text-to-Video Generation, ICLR 2024.
[5] Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, Ying Shan, MotionCtrl: A Unified and Flexible Motion Controller for Video Generation, ACM SIGGRAPH 2024 Conference Papers , 1-11.
[6] Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, Arash Vahdat, CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation, arXiv preprint arXiv:2406.02509..
[7] Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, Yonghong Tian, ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis, IEEE Transactions on Pattern Analysis and Machine Intelligence, 1-18.
[8] Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, Di Zhang, ReCamMaster: Camera-Controlled Generative Rendering from a Single Video, ICCV 2025, 14834-14844.
[9] Mark Yu, Wenbo Hu, Jinbo Xing, Ying Shan, TrajectoryCrafter: Redirecting Camera Trajectory for Monocular Videos via Diffusion Models, ICCV 2025, 100-111.
[10] Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, Angjoo Kanazawa, Cameras as Relative Positional Encoding, NIPS 2025.
[11] Haotong Lin, Sili Chen, Junhao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, Bingyi Kang, Depth Anything 3: Recovering the Visual Space from Any Views, arXiv preprint arXiv:2511.10647.
[12] Max Bain, Arsha Nagrani, Gül Varol, Andrew Zisserman, Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval, ICCV 2021, 1728-1738.
[13] Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Youqing Fang, Yuwei Guo, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, Dahua Lin, HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation, NeurIPS 2024, 20111-20131.
[14] Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, Jing Liao, Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion, SIGGRAPH 2024, 1-12.

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










