点击下方卡片,关注“具身智能之心”公众号
台北 GTC 上,老黄站在一台银色人形机器人旁边,直接下场卷具身了。
仿真、开放模型、训练数据生成,最底下是大家很熟的 Jetson Thor。芯片、大脑、本体、灵巧手,英伟达想把人形机器人的整条栈都纳入自己的盒子里。

发布会结束没几天,几位做投资和做部署的朋友先后来找我们聊端侧芯片。
说实话,这个方向我们之前关注得不算多,Thor 在我的印象里一直是自驾量产的芯片。去官网查了一下,有点意外:算力 2070 FP4 TFLOPS、128GB 显存,功率可配置在 40W 到 130W 之间。
40 到 130W放车上没问题,可放到一台靠电池活动的机器人身上,这个数字就有点吓人了。
给个参照:特斯拉 Optimus 背的是一块 2.3kWh 电池,坐着不动整机约 100W功耗、快走起来约 500W;宇树 H1 的电池是 864Wh,官方标的运动续航也就 1 小时出头,G1 那块 9000mAh 电池续航约 2 小时。

Thor 功率拉满换算到 H1 的电池上,单是大脑 6 个多小时就能把电吃光,本体的电机、传感器还一点没动。续航本就是人形机器人的痛点,大脑这一项先占掉一大块。
这两年具身的聚光灯,几乎都在大脑和本体上,风光是真风光。可真正决定一台机器人能不能落地量产的,恰恰是脚下的端侧芯片。
说到底,没有一块撑得住的芯片,再强的大脑,也是死的。
所以几位朋友问我们国产有没有能平替的,功耗能不能做的更低?性能还能兼顾目前主流的框架?
被这么一问,我们觉得还是有必要认真做了下调研。先看看牌桌上都有谁。
01
牌桌上都有谁
端侧机器人芯片这块,国内外现在大致有这么几拨人在做:
英伟达:通用大平台路线。旗舰 Jetson Thor 给到 2070 FP4 TFLOPS、128GB 显存,功率 40–130W;低一档的 AGX Orin 是 275 TOPS(INT8)、15–60W。强是真强,但功耗和价格都是按「什么都能干」配的。

高通:CES 2026 发布的 Dragonwing IQ10 号称最高 700 TOPS,直接瞄准人形和工业机器人,Figure、库卡都是首发伙伴;不过上市要等到 26 年 9 月,主打能效,没公布具体功耗。
瑞芯微:传统方案里的常客。RK3588 的 NPU 只有 6 TOPS,但胜在功耗低、便宜,很多机器人拿它做小脑运控,真要扛 VLA 或者 WAM就吃力了。
还有一些初创:根据迈特芯最近披露的消息,他们的国产芯片跑通了自变量 VLA 模型的适配验证,平均功耗5W。此外还有地瓜机器人等等。
巨头还有一手自研自用。特斯拉 Optimus 用的是自家 AI 芯片,并不对外。
把这一圈扫下来,最直观的是落差是:算力从 6 TOPS 到 2000 TOPS 差出三个量级,功耗从个位数到 130W,价格从两千多到两万多。而且每家关注的点都不一样,有人做通用算力,有人做大小脑异构,还有人主打性价比。
路线这么散、参数差出十几倍,反而暴露了一个更基础的问题:这么多公司在做端侧芯片,但「端侧到底卡在哪」,大家的答案并不一致。
在我们看来,多数人押错了方向。真正的瓶颈,恐怕不在算力本身。
02
端侧部署的卡点,不是算力是带宽
先替 Thor 说句公道话:它不弱,是太强了。
2070 FP4 TFLOPS、128GB 显存,对标上一代 Orin 算力提升 7.5 倍、能效 3.5 倍。

可这套规格是按「物理 AI 通用大平台」设计的,什么都要能干,代价就是功率拉到 40–130W、价格做到两万出头。这两个参数放到送餐机器人都难受:机器人要在商场跑一整天,续航是硬指标,130W 峰值意味着要么背更大电池、要么频繁回充,都会卡运营效率;成本上本就要抠 BOM,光大脑硬件两万多,经济上不是很划算。
所以端侧跑 VLA,到底卡在哪?
最直接的答案好像是「算力不够」。但我们调研了一圈发现并非如此。我也联系了几位这方面的专家,他们的结论大体一致:
「真正卡脖子的,不是算力大小,是存储带宽和带宽利用率」。
以现在主流部署的VLA为例。模型可以分成两段:
前面的 VLM。这部分大家用的模型都差不多,π0.5、π0.6 或者Qwen 2.5VL,基于开源模型魔改;
难点在后面的动作端。diffusion 或者 flow matching ,不是每家都有解决方法。
而无论是 VLM 推理还是动作生成,大模型在芯片上跑的时候,大部分时间不是在运算,是在等数据从内存传输过来。
简单来说就是:算力是工人,带宽是传送带。传送带又窄、利用率又低,工人再多也只能干等。这就是业内说的「内存墙」。
关于这部分的技术参数,我们联系到了迈特芯。把四类端侧方案总结成了一张表:
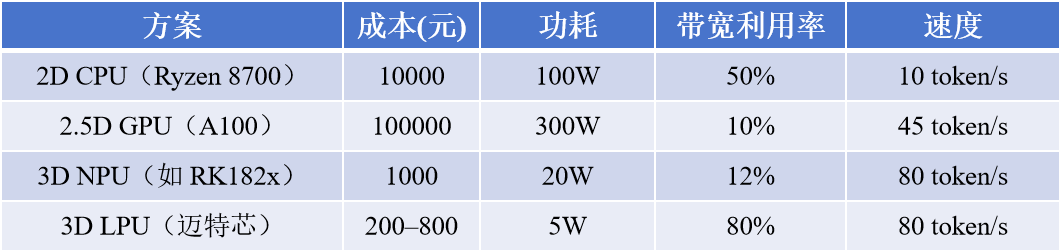
「带宽利用率」这一栏很有意思。GPU 物理带宽很高(A100 标称近 2000GB/s),但跑端侧大模型时利用率只有 10% 上下,大量带宽空转;NPU 也只有 12%,算力闲置。
迈特芯利用率能做到 80%。同一条传送带,它能跑满。这才是低功耗、低成本还保住速度的根本原因。
把卡点定义清楚,后面要解决的问题就是:谁能在小功耗下把带宽吃满,谁才接得住端侧部署这条路。
03
这道题该怎么解
这个问题,是整个后摩尔时代摆在所有芯片公司面前的方向题。
过去几十年,芯片性能靠把晶体管做小往前推。但晶体管快缩不动了,单纯堆制程的收益越来越薄。
华为前阵子提出了 τ(tao)定律,说的就是这个意思:后摩尔时代的优化,不能只盯着晶体管,得跨芯片、电路、系统多个层级做系统级的时间优化。
落到端侧大模型芯片上,这道题的题面是:怎么在小功耗、低成本下,把内存墙拆掉、把带宽吃满。
迈特芯的专家告诉我们。业内公认的方向之一是近存计算和 3D 堆叠。逻辑大体是:传统 2D/2.5D 方案里算的芯片和存的芯片分开布线,数据中间长途跋涉,又慢又费电;把内存垂直堆到逻辑芯片上方、直接近距离互连,路就短了。
打个比方,以前是仓库和工厂分两座城、靠卡车拉货,现在直接把仓库盖在车间二楼,开个口子料就下来了。这个路线的物理收益是实打实的:同样做到 600GB/s 带宽,互连延迟能从 20–40ns 降到 5ns 以内,能效比从 7–9.5 pJ/bit 降到 0.8–1.5 pJ/bit,总功耗从三四十瓦压到 3.8–7.2W。
方向是共识,难的是工程化。沿着这条路开发的国产团队不止一家,迈特芯是走得比较靠前的一个。他们给自己的产品起名叫 MC_mega,核心就是这套 3D 近存。

迈特芯3D芯片结构
具体到怎么落地,迈特芯的负责人告诉我们主要有两点:
立方脉动阵列架构(Cubic Systolic)。计算那一侧的解法,TPU 逻辑芯片上有自有专利。对比 Google 的标量脉动架构,他们的数据是能效提升 1.24 倍、面积减少 20%、动态功耗降低 42%。
3D 分布式数据搬运架构。算芯片和存储芯片之间数据怎么走的解法,也是自有专利。
有几个硬指标,9B 模型、20GB 内存、600GB/s 带宽。定价目标 800 元以内,是Thor 1/30 的成本,5W功耗。
这对一台要量产的服务机器人来说,不单单是优化,是换了一套成本结构。
下面,我们就一起看看他们是怎么实现的。
04
模型、芯片和本体,第一次拼齐
链路是这样的。
自变量提供 VLA 大模型(WALL-OSS),迈特芯把模型适配到自己的芯片上,部署后用来驱动普渡的机械臂,去做具体的操作。目前已经在真机验证的阶段了。

目前,在和 MC_mega 系列芯片同构的FPGA验证平台上,迈特芯已经跑通了自变量的 WALL-OSS VLA 模型。整个系统的大小脑方案就是下面这张图。

异构集成大小脑方案
模型怎么在芯片上落地,迈特芯把 VLA 拆成大脑和小脑两块来承载:大脑跑 VLM 主干,负责看懂环境、理解指令、生成高层动作意图;小脑是专门的强化学习协处理器,支持VLA后训练,如离线强化学习(RECAP)、在线RL残差PLD模块等等。负责底层实时运控,并在真机上采集反馈、可以在线更新轻量策略模块。
一句话概括分工:大脑决定「做什么」,小脑负责「怎么越做越好」。
迈特芯自己给出的结果是,使用端侧在线强化学习框架,在 OOD 陌生场景做 30 分钟的真机交互,成功率可以从 50% 提升到 70%,全程不依赖云端。
这也确实是真机RL的优势之一,对于模型和本体的泛化还是很有必要的。
技术负责人还告诉我们,这也是迈特芯把 RL 协处理器做进芯片层面的原因。他们认为泛化会成为下一阶段本体的胜负手,而泛化的载体需要在端侧上在线学习。
05
写在最后:国产接得住这一棒吗
判断一家端侧芯片公司能不能成,其实不看发布会和 PPT,要看回片。
这话听着残酷,但芯片行业就是如此。
尤其是国内,整个行业仍然方兴未艾。这条路上,有很多值得我们关注的公司。并且每一家的切入角度各不相同,但都在填补国产端侧芯片的空白。
具体到迈特芯,目前在FPGA上走出了第一步,完成了架构的验证。芯片回片还在路上,但也不妨碍我们继续关注这个行业。
再把镜头拉远一些,具身现在给我们的感觉,有点像 2018 年前后的自驾。方向大家都认,但软硬件、数据、量产还没一样完全收敛,每个公司都在补齐自己的短板。
端侧芯片这一环过去几乎被英伟达一家定义。现在国产从功耗、成本这个口子切进来,哪怕只是验证阶段,这个信号本身就值得记一笔。












