点击下方卡片,关注“具身智能之心”公众号
智源大会上,银河通用机器人创始人王鹤抛出了一个很大的判断:具身智能的「AlphaGo 时刻」已经到来。
「AlphaGo 时刻」指的是那些专精突破——比如全球首个全自主打网球的人形机器人(Musk 看完直接评论「insane」,Karpathy 一度以为是 AI 生成的假视频),还有靠灵巧手世界模型 DexNDM 做到的全球唯一真机转笔、春晚盘核桃。
这些很炸,然而都比较“专”。
比起这些大词,我们更想拆的是银河这次实打实摊出来的两样东西——通用大脑 AstraBrain WAM 0.5 和 通用小脑 AstraBrain-WBC 0.5。
因为它俩恰好对应了具身今年最重要的两条线:大脑侧「世界模型和 VLA 的融合」,小脑侧「运控从单技能走向基础模型」。
看懂这两个,就看懂了领域现在到哪了。
01
大脑 WAM 0.5:
世界模型和 VLA的「融合」
先看大脑。
银河的核心路线叫 WAM(World-Action Model,世界-动作模型),这个词是他们 2025 年在 ICCV 上首次提出的——王鹤说,今天在 arXiv 上搜「world action model」按时间排序,第一篇就是银河的。
王鹤把这件事讲得很透:
VLA 本质是预测 action,它的监督必须依赖带 action label 的具身数据(贵、少);而视频生成不需要 action,完全可以用人戴相机拍下自己干活的纯视频来训,这种数据更 diverse、成本更低、任务空间更广。前者是 explicit action,后者是「image representation as action」——生成的画面里其实已经隐含了机器人的手该怎么动、胳膊该怎么伸。
简单来说:用海量无标签视频解放数据瓶颈,再把它和需要标签的动作预测拧在一起。这也是为什么英伟达的 Jim Fan 会说,WAM 是「robotics endgame(机器人的终局)」。
这条判断和今年整个领域是合拍的。
之前分享了好几篇相关内容,「VLA 和世界模型不是对立、而要融合」已经成了智源大会上一堆 CEO 的共识。银河只是把这个共识,往前推得更彻底、也更早占了名分。

WAM 0.5 这一代,具体的进展有几处值得记:
用「latent 想象」替代「RGB 想象」(对应 RSS 2026 的 LDA 工作)。人对未来的预测本来就做不到像素级,所以银河不在 RGB 空间里预测未来画面,而是在低分辨率的 latent 空间里想象——把光照、纹理这些不重要的信息 factorize 掉,只关注背后的动作和几何。结果是用更少的数据、拿到更强的性能,而且 scaling 曲线比 RGB 方案更好。
统一四个任务(UWM):把 VA、VV 加上前向动力学、逆向动力学,四件事塞进同一个大模型一起 scale。
长程任务 + 语言可打断:演示里让机器人「抓夹子→夹牛排→(中途用语言打断)改抽底下那片→放盘子→撒胡椒粉」,据称只用极少真机数据就训成了。
跨本体:灵巧手、二指夹爪、其他机器人,同一个模型能做 cross-embodiment 泛化。
三类数据统一进一个模型:合成 + 真实 + egocentric(第一视角)全吸收——银河 2021 年就发过全球最大的 egocentric 手物交互数据集,这条线他们站得早。
银河也给了对标:在全部任务上超过 π0.5 和 NVIDIA 的 Groot N1.6。
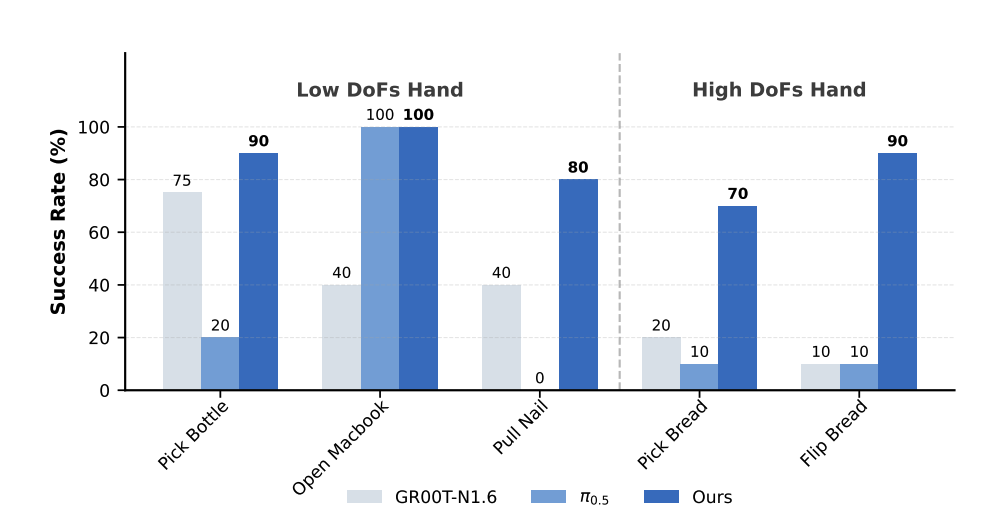
这点先记着,对比的任务集、条件如何,还要看完整论文。不过「latent 想象 + 统一无标签数据」这个方向本身,我们认为是扎实的。
02
小脑 WBC 0.5:
运控第一次跑出了「Scaling Law」
如果说大脑决定机器人「怎么理解世界」,那小脑决定它「在真实世界里怎么动」——毫秒级内协同数十个自由度、保持平衡、抗住扰动。
这块过去一直是具身的老大难。
长期以来,运控是「学一个动作、会一个动作」:针对单一技能专门训练,换个没见过的新动作就抓瞎;模型大多是浅层 MLP,容量有限,数据再多也涨不动。
AstraBrain-WBC 0.5(基于 CVPR 2026 的 HumanoidGPT)正是要改变这个局面。
它的几个数字很有分量:
2 万小时人类动作数据,号称行业最大规模运动语料库,覆盖舞蹈、高动态、快速转向、跌倒恢复、协作搬运等大量长尾动作——动作空间覆盖比行业常用的 AMASS 大 4–5 倍。
8040 万参数,数据量达到 GPT-1 量级。对比一下:此前代表作 GAE 是数千小时 / ~1000 万参数,SONIC 约 700 小时 / 1000–2000 万参数——WBC 0.5 在数据和模型上都是数量级的跃升。
架构换血:首次用 GPT 式的因果 Transformer 替代 MLP,把全身控制重新定义成「连续序列预测」——不再只看当前该怎么动,而是结合过去的动作历史预测未来趋势,像 GPT 理解语言序列一样理解「运动语义」。背后还有 384 个动作专家,蒸馏融合成一个统一控制模型。

最关键的一点:它第一次在运控领域验证了类似 GPT 的 Scaling Law。
据其论文,数据规模从 200 万帧扩到 20 亿帧、模型持续变大,成功率从 83.26% 提到 92.58%,零样本跟踪误差持续下降,没有出现传统运控常见的性能瓶颈。

带来的能力也实在:
真机零样本 OOD 泛化——篮球、拳击、舞蹈、翻身起立这些训练集里没有的高动态动作,能直接执行,不用单独重训。这是运控第一次有了「面对陌生动作也能迁移」的味道。
毫秒级实时——工程优化后,单张 RTX 4090 上端到端推理延迟低于 1.5ms,整套动捕链路延迟小于 20ms,满足 50Hz 实时闭环;在 29 自由度机器人上做到全身全手协同。
全面开源——论文、模型都放了出来。
一句话:小脑这条线,第一次从「轨迹追踪」走到了「基础模型 + Scaling」。
03
具身的两条线,都在往基础模型收敛
把 WAM 0.5 和 WBC 0.5 放一起看,其实在讲同一件事:具身的大脑和小脑,都在复刻 GPT 那条路——数据、模型、训练一起规模化,跑出 Scaling Law 和零样本泛化。
两者通过「脑桥」异步连接,合成银河星脑 AstraBrain,这是它「全栈自研、大脑-小脑-神经控制一体」的底盘。
这也正是今年领域的两个大方向:
大脑侧:VLA × 世界模型融合成共识,WAM、Fast-WAM、ω-EVA……一堆人撞向同一个方向,无标签 egocentric 视频成了 scale-up 的关键燃料(这条线我们去年也专门写过第一视角人类视频)。
小脑侧:运控从「单技能 MLP」走向「通用运控基础模型」,GAE、SONIC 到 AstraBrain-WBC 0.5,是一条清晰的规模化曲线。
王鹤给整件事套了个叙事框架:从「AlphaGo 时刻」(网球、转笔这类专精突破)走向「ChatGPT 时刻」。他给「ChatGPT 时刻」下的定义也很具体——预训练后,在人类无需专门学习就能完成的技能上,zero-shot 达到 70–80% 成功率,再加上 accessibility。












