点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~

过去几年,机器人操作算法岗的要求正在明显变化。
以前大家更关注单点能力:会不会视觉抓取、会不会位姿估计、会不会 MoveIt、会不会 ROS、会不会调机械臂。只要能把一个固定任务跑起来,就已经算不错。
但到了 2026 年秋招,具身智能把这个岗位重新洗了一遍。企业更想要的,不只是“会一个算法模块”的人,而是能把真实机器人任务从数据、模型、仿真、部署到失败回流完整跑通的人。
一句话总结:
现在的机器人操作算法岗,拼的不只是论文和模型名,而是你能不能把机器人真正跑起来,并且持续把成功率做上去。
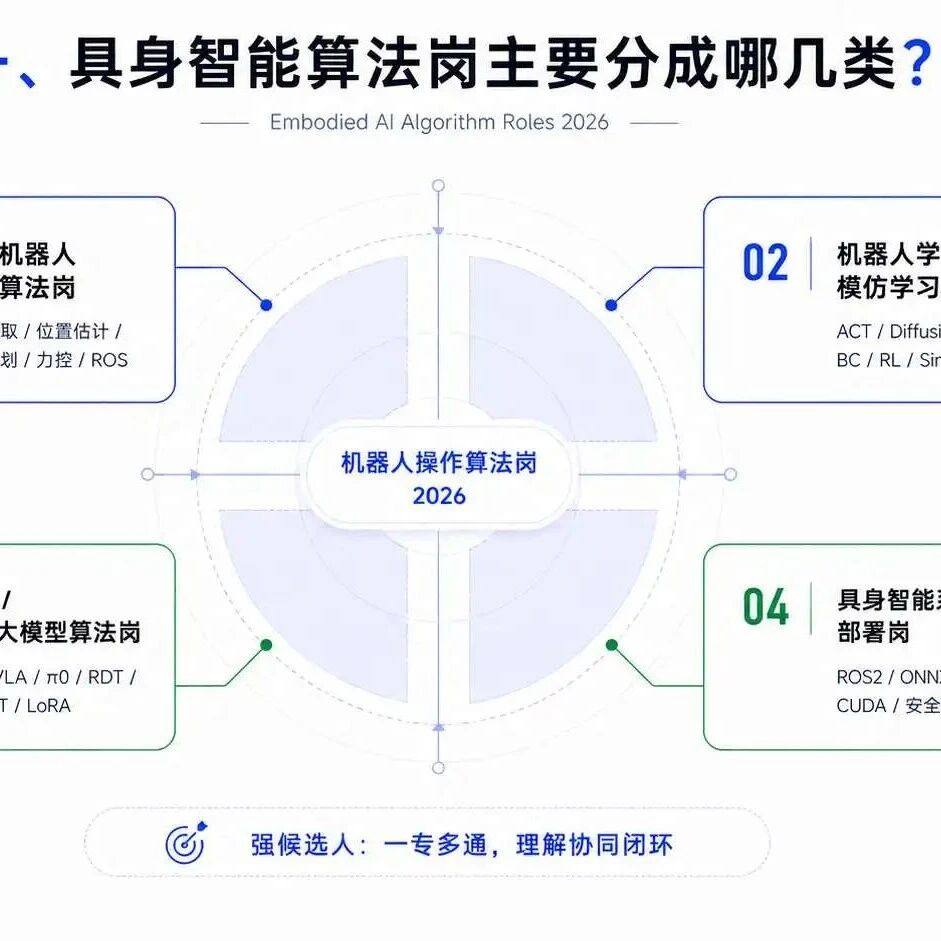
一、具身智能算法岗主要分成哪几类?
如果把当前岗位拆开,大致可以分成四类。
第一类是传统机器人操作算法岗。
这类岗位关注视觉抓取、位姿估计、运动规划、轨迹优化、力控、标定、手眼系统和 ROS 工程。面试常问相机模型、PnP、ICP、坐标系变换、MoveIt、RRT、CHOMP、TrajOpt、阻抗控制、导纳控制、碰撞检测、抓取位姿生成等。
第二类是机器人学习 / 模仿学习算法岗。
这类岗位关注 ACT、Diffusion Policy、BC、RL、offline RL、数据采集、轨迹表示、动作空间设计、策略评估和 Sim2Real。面试会问 observation 怎么设计,action 用关节空间还是末端空间,chunk size 怎么选,策略为什么会抖,为什么仿真能成功但实机失败,失败样本怎么处理。
第三类是VLA / 具身大模型算法岗。
这类岗位关注 OpenVLA、π0、π0.7、RDT、GR00T、SmolVLA、Gemini Robotics 等视觉-语言-动作模型。面试会问 VLA 和 Diffusion Policy 的区别,语言指令怎么进入策略,动作怎么表示,LoRA 和全参微调怎么选,推理延迟怎么解决,跨机器人本体迁移怎么做。
第四类是具身智能系统工程 / 部署岗。
这类岗位关注 ROS2、ONNX、TensorRT、CUDA、异步推理、实时控制、数据平台、实验看板、日志系统和安全回滚。面试会问如何把一个 10Hz 的大模型策略接到 50Hz 或 100Hz 的控制系统里,如何减少相机到动作的延迟,如何做故障保护,如何把真机失败样本回流到训练集。
真正强的候选人,不一定四类都精通,但至少要在一个方向扎深,同时理解其他方向如何协同。
比如你主攻 VLA,也必须知道真实机器人里的延迟、抖动、标定误差、夹爪失败、碰撞保护和数据质量会怎么影响模型。你主攻运动规划,也必须知道为什么现在很多团队开始从传统 pipeline 走向端到端策略。
二、秋招真正要补的,不是论文,而是闭环能力
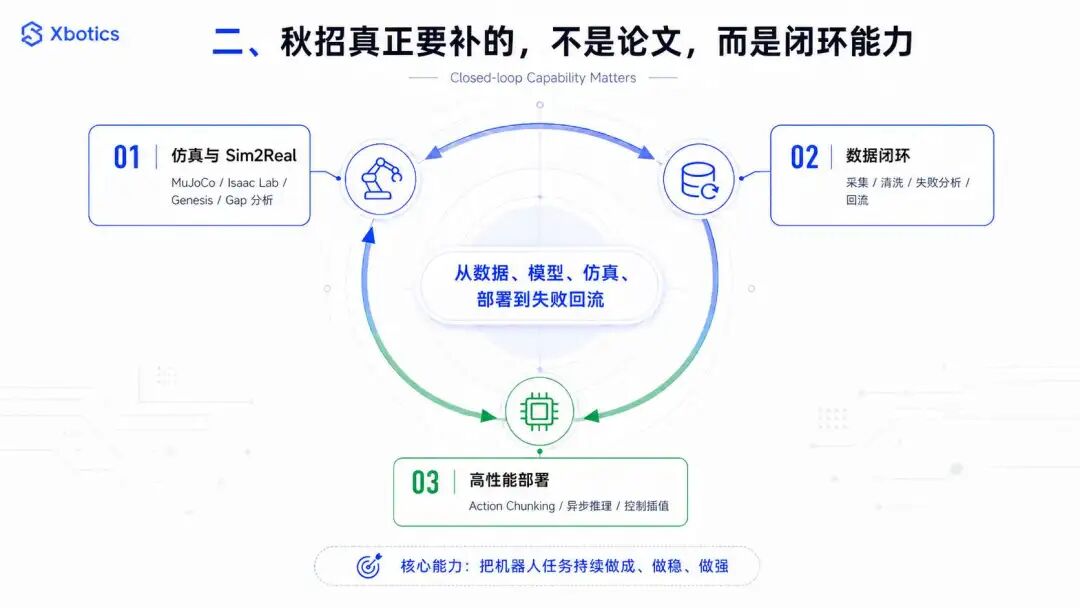
1. 仿真与 Sim2Real:不只是会搭环境,还要会解释差距
仿真已经不是加分项,而是机器人算法岗的基础能力。
常见工具主要有 MuJoCo、Isaac Sim / Isaac Lab 和 Genesis。
MuJoCo 适合机器人控制、强化学习、接触动力学和轻量级策略验证,优点是快、稳定、适合算法研究。
Isaac Sim / Isaac Lab 更适合大规模并行仿真、合成数据、视觉传感器和 GPU 加速训练,优点是生态完整,和 NVIDIA 部署栈结合紧。
Genesis 是近两年比较值得关注的新仿真平台,强调统一多物理引擎、速度和生成式物理世界。对求职来说,它可以作为前沿亮点,但不建议只押一个平台。更重要的是,你要能讲清楚不同仿真器适合什么任务。
面试官真正想听的,不是“我用过 Isaac Lab”,而是你知道 sim-to-real gap 从哪里来。
视觉 gap 可能来自光照、纹理、相机噪声、曝光、遮挡和反光;动力学 gap 可能来自摩擦、质量、关节阻尼、接触模型和夹爪柔顺性;控制 gap 可能来自通信延迟、执行器响应、控制频率和末端标定误差;任务 gap 则来自物体分布、初始状态分布和 reset 规则。
比较好的表达是:
“我不会只做随机纹理和随机光照,而是会把 Domain Randomization 做成可量化实验。比如固定策略结构,逐步增加颜色、位姿、摩擦、质量、相机外参和点云 dropout 的随机化强度,记录仿真成功率、真机成功率和 sim-real gap。最后选择的不是仿真里最高的参数,而是真机泛化最稳的随机化区间。”
这句话比“我做了域随机化”更有说服力,因为它体现了工程判断。
2. 数据闭环:不是采了多少条,而是失败怎么变成提升
具身智能岗位里,数据能力越来越重要。
无论是 ACT、Diffusion Policy、VLA、RDT 还是 π0,本质上都很吃数据。一个合格的数据闭环项目,至少要讲清楚五件事。
第一,数据从哪里来。
可以是遥操作、VR 示教、手柄控制、脚本策略、仿真数据、人工视频,也可以是真机失败回采。
第二,数据怎么存。
至少要包含 observation、state、action、instruction、timestamp、episode_id、success / failure 和 reset 信息。视觉可以包括主视角 RGB、深度、点云、腕部相机;状态可以包括关节角、末端位姿、夹爪宽度、力矩、触觉;动作可以是关节增量、末端 delta pose、绝对末端 pose、夹爪开合或底盘速度。
第三,数据怎么清洗。
要处理时间同步、丢帧、动作延迟、轨迹截断、异常点、空动作、示教抖动、重复片段和失败标签。
第四,数据怎么分析。
不能只说“我采了 500 条数据”,而是要做失败分析。比如按任务阶段、接触状态、物体类别、初始位姿、夹爪状态和轨迹 embedding 聚类,得到失败根因表:抓偏、抓空、遮挡、碰撞、插入失败、放置偏移、长程漂移等。
第五,数据怎么回流。
比如针对“插入失败”补采插入前 3 秒数据;针对“边缘物体抓取失败”补采边缘分布;针对“语言歧义失败”增加 instruction paraphrase;针对“腕部相机不在视野”增加历史帧和阶段条件。
更有竞争力的简历句式是:
“构建 1.2k episodes 双臂操作数据集,包含 RGB、wrist camera、关节状态、末端 delta pose 与语言指令;按任务阶段标注 grasp / transfer / insert / release,建立失败样本库并用轨迹 embedding 聚类,将插入失败占比从 46% 降至 23%,整体任务成功率提升 12.4pp。”
这就不是简单“采数据”,而是数据闭环。
3. 高性能部署:模型能跑不够,闭环要稳定跑
很多同学做机器人学习项目,训练完模型就结束了。但企业更关心的是:模型能不能上真机,延迟能不能压住,异常能不能保护,任务能不能稳定复现。
比较常见的部署链路是:
PyTorch 训练模型,导出 ONNX,再用 TensorRT 做 FP16 或 INT8 优化,部署到 Jetson Orin、Thor 或工控机 GPU 上。机器人侧通过 ROS2 节点接入相机、状态、策略推理和控制器。系统侧用异步线程、双缓冲或共享内存减少相机采集、预处理、推理和控制下发之间的等待。
面试里可以重点讲三个词:
action chunking、asynchronous inference、control interpolation。
大模型策略通常不能每 100Hz 推理一次。常见做法是让模型一次预测未来 N 步动作,比如未来 8 步、16 步或 32 步;控制器按高频执行动作序列,同时后台异步计算下一段 action chunk。这样可以把 5Hz 或 10Hz 的策略推理接到 50Hz 或 100Hz 的控制系统里。
但 action chunking 也有问题。
chunk 太长,策略反应慢,遇到扰动不容易及时修正;chunk 太短,模型调用频繁,延迟和抖动会变大。
所以面试时不要只说“我用了 action chunking”,而要说你怎么选 chunk size:
“我会根据任务阶段动态调整 chunk size。接近物体前可以用较长 chunk,提高平滑性;接触、插入、放置阶段使用较短 chunk,提高反馈频率。对于高频控制,我会将模型输出插值到控制频率,并增加末端速度、加速度限制,避免动作突变。”
ROS2 部署也可以这样讲:
“视觉节点、策略节点和控制节点尽量用 Composition 放在同一进程里,减少序列化和跨进程拷贝;大图像和点云数据尽量使用 intra-process、loaned message 或共享内存方案;策略推理和控制下发用双缓冲,保证控制线程不被推理阻塞。”
如果你能讲到这里,面试官会知道你不是只在 notebook 里跑模型的人。
三、前沿策略模型:不要背名词,要讲清楚取舍
2026 年机器人操作算法岗,比较容易被问到的模型大致有三类。

1. ACT:小数据、低成本、强工程 baseline
ACT 的核心是 action chunking + imitation learning,适合低成本遥操作数据、相对固定任务和 ALOHA 类双臂操作。
它的优点是训练简单、部署相对容易、数据需求没那么夸张;缺点是泛化能力有限,对任务分布变化敏感,语言理解能力弱。
面试时可以这样说:
“ACT 更像一个强工程 baseline。如果任务固定、数据量不大、需要快速跑通真机,我会先用 ACT 建 baseline。它的价值不是通用智能,而是建立数据、部署和评估链路。”
2. Diffusion Policy:连续动作任务里的强 baseline
Diffusion Policy 的优势是能建模多峰动作分布,适合抓取、推拉、插入、柔性物体等连续控制任务。相比普通 BC,它对复杂动作分布更友好,训练稳定性也不错。
但它也有明显缺点:推理需要多步 denoising,延迟较高;如果不做加速,真机闭环频率容易受影响;同时语言条件和跨任务泛化能力不如 VLA。
面试时可以这样说:
“Diffusion Policy 适合做低层连续控制专家,尤其是接触丰富、动作分布多峰的任务。但如果任务需要语言理解、多任务复用或开放场景泛化,我会把它放在 VLA 或高层 planner 下面,作为低层 skill policy。”
3. VLA / 具身基础模型:看的是长期趋势
VLA 模型的代表包括 OpenVLA、π0、π0.7、RDT、GR00T、SmolVLA、Gemini Robotics 等。
这类模型的核心变化是:机器人策略不再只是看图出动作,而是开始结合语言、视觉、状态、子目标、任务上下文、世界知识和跨本体数据。
π0 和 π0.7 代表的是通用机器人策略模型方向,强调更大规模数据、更丰富上下文和跨任务泛化。
RDT 更适合双臂、人形和复杂操作方向,强调多模态输入、连续动作建模和跨机器人本体。
GR00T 更偏人形机器人基础模型和 NVIDIA 生态,关注相对末端动作空间、人形数据、仿真数据和后训练。
Gemini Robotics 则强调 VLA + embodied reasoning,也就是一部分能力负责理解和推理,一部分能力负责把视觉语言转成动作。这很适合长程任务、工具使用、安全推理和任务分解。
面试里可以这样总结:
“ACT 和 Diffusion Policy 是当前真机操作里最实用的强 baseline;OpenVLA / SmolVLA 更适合求职者做可复现的 VLA 微调项目;RDT 和 GR00T 更适合双臂、人形和跨本体方向;π0.7 和 Gemini Robotics 代表更长期的趋势:机器人策略不只是看图出动作,而是要结合语言、记忆、子目标、任务质量、世界知识和推理能力。”
四、VLA 面试高频问题怎么答?
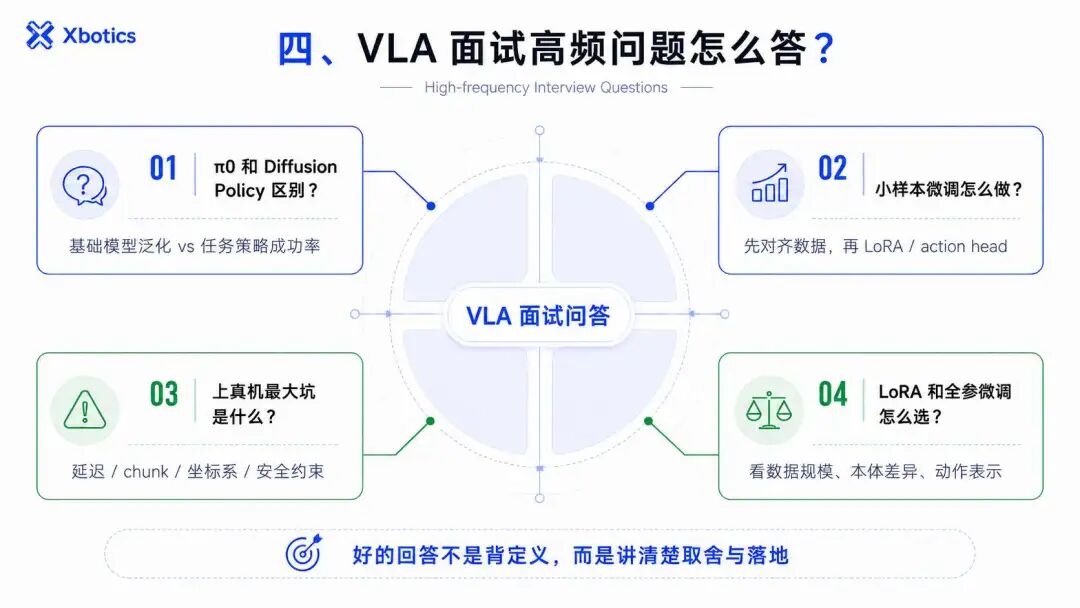
问题 1:π0 和 Diffusion Policy 有什么区别?
可以这样答:
“Diffusion Policy 更像一个面向具体任务的连续控制策略,输入通常是视觉和状态,输出未来一段动作。π0 这类 VLA 模型更像通用策略基础模型,它在更大规模、更异构的数据上预训练,输入包含视觉、语言和状态,输出动作。两者都可能使用 diffusion 或 flow matching 形式生成动作,但目标不同:Diffusion Policy 追求特定任务高成功率,π0 追求跨任务、跨场景和跨本体泛化。”
问题 2:小样本微调 VLA 时,你会怎么做?
可以这样答:
“我会先做数据规范化,而不是直接微调。首先统一相机视角、时间戳、动作频率和坐标系;其次将动作表示转成相对末端位姿或关节 delta,避免绝对位置绑定场景;然后按任务阶段切分 episode,保证抓取、移动、插入、释放这些阶段都有足够样本。微调策略上,数据少时优先 LoRA 或 adapter,避免破坏预训练能力;数据足够且本体差异大时,再考虑解冻 action head 或部分中间层。评估时不只看 loss,而要看真机成功率、失败阶段分布和动作平滑性。”
问题 3:VLA 上真机最大的坑是什么?
可以这样答:
“最大的问题不是模型能不能输出动作,而是输出动作能不能被真实控制系统稳定执行。主要坑有四个:第一,视觉延迟导致动作基于过期观测;第二,action chunk 太长导致反应慢;第三,动作坐标系和机器人控制接口不一致;第四,模型输出没有速度、加速度、碰撞和安全约束。我的解决方式是异步推理、短 horizon 反馈、动作插值、限速滤波、安全 monitor 和失败回滚。”
问题 4:LoRA 和全参微调怎么选?
可以这样答:
“数据量小、任务相似、本体接近时,我优先 LoRA,因为成本低,也不容易破坏基础模型的泛化能力。数据量大、本体差异明显、动作空间变化大时,我会至少微调 action head 和部分中间层。如果是新机器人本体,我会优先保证 action representation 对齐,比如末端 delta pose、夹爪宽度和关节归一化,再考虑微调策略。很多时候微调效果差不是 LoRA 不行,而是数据格式、动作空间、相机视角和时间同步没处理好。”
五、简历里最值钱的不是模型名,而是数字闭环

机器人算法岗简历最忌讳这样写:
“负责机械臂抓取算法开发,使用 Diffusion Policy 和 OpenVLA 完成模型训练与部署。”
这句话最大的问题是:没有任务、没有数据、没有指标、没有难点、没有结果。
更好的写法是:
“面向工业多物料分拣任务,构建 800 episodes 遥操作数据集,包含主视角 RGB、腕部 RGB、关节状态、夹爪宽度与末端 delta pose;基于 Diffusion Policy 训练低层抓取策略,并通过历史帧输入、动作平滑和失败样本回采,将三类物料抓取成功率从 68.3% 提升至 84.7%。”
或者:
“基于 OpenVLA-OFT 思路完成 VLA 微调实验,将自采 1.5k episodes 数据转为统一 LeRobot 格式,采用连续动作表示、action chunking 与 LoRA 微调;在 24 个桌面操作任务上,平均成功率较 ACT baseline 提升 9.6pp,推理延迟由 210ms 降至 165ms。”
或者:
“搭建 Isaac Lab 仿真到真机验证流程,对物体位姿、摩擦系数、相机外参和点云 dropout 进行分层随机化;通过随机化强度扫描和真机 A/B 测试,将 sim-real gap 从 15pp 降至 6pp。”
或者:
“优化机器人策略部署链路,将 PyTorch 模型导出 ONNX 并使用 TensorRT FP16 加速;通过 ROS2 Composition、异步双缓冲和动作插值,将端到端感知-决策-控制延迟从 240ms 降至 155ms,实现 60Hz 控制闭环。”
写简历时记住一个公式:
任务场景 + 数据规模 + 方法选择 + 工程难点 + 指标提升 = 一条有效经历。
没有真机也不是不能写,但要强调 benchmark 和可迁移性:
“在 LIBERO / RoboCasa / ManiSkill / Isaac Lab 环境中构建多任务操作 benchmark,复现 ACT、Diffusion Policy 和 OpenVLA-OFT baseline,统一评估 success rate、completion time、action smoothness、OOD object generalization,并输出失败根因分析表。”
六、最后的求职建议:不要把自己包装成“会跑模型的人”
2026 年具身智能算法岗,简历和面试最重要的不是堆满模型名,而是证明你能解决真实机器人问题。
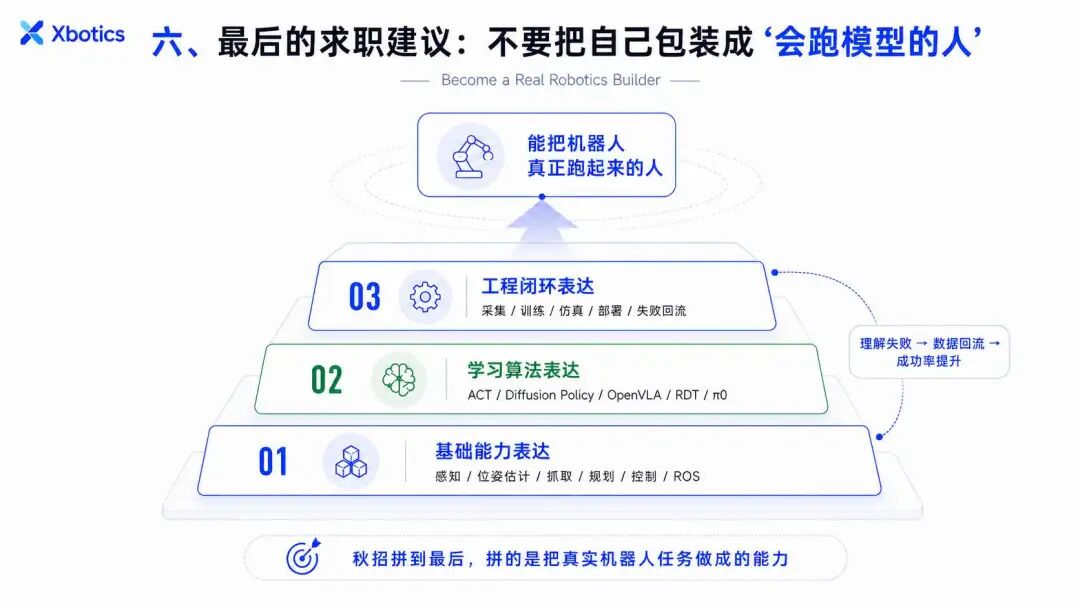
你需要准备三套表达。
第一套是基础能力表达:
“我理解机器人操作的传统 pipeline,包括感知、位姿估计、抓取生成、运动规划、控制和 ROS 部署。”
第二套是学习算法表达:
“我熟悉 ACT、Diffusion Policy、OpenVLA / OpenVLA-OFT、RDT、π0 / π0.7 等策略模型,理解它们在数据规模、动作表示、泛化能力和部署延迟上的取舍。”
第三套是工程闭环表达:
“我能从真机任务出发,完成数据采集、数据清洗、模型训练、仿真验证、真机部署、失败分析和迭代优化。”
真正能打动面试官的,不是你说“我了解 VLA”,而是你能说:
“我知道 VLA 为什么会失败,也知道怎么把失败变成下一轮数据。”
这就是具身智能算法岗最核心的能力。
未来的机器人算法工程师,不会只是调一个检测模型、写一个规划节点、跑一个 imitation learning baseline 的人,而是一个能把物理世界、数据系统、策略模型和工程部署连接起来的人。
秋招拼到最后,拼的不是谁背的论文最多,而是谁最像一个能把机器人真正跑起来的人。
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀