点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~

人形机器人正在从“看起来很酷的演示视频”,走向每一个开发者可以亲手参与的工程现场。
过去大家看到的,可能是机器人在宣传片里行走、搬运、分拣、装箱,也可能是比赛 Demo 中完成一个个复杂任务。但真正的问题是:
这些能力到底怎么做出来?普通开发者能不能从零开始理解它、训练它、部署它,并最终让机器人在仿真和真机上真正动起来?
这正是本次 UBT × Xbotics 具身人形机器人开发实训营 要解决的问题。
在第 1 课直播中,我们从实训营整体安排讲起,带大家认识优必选开发者生态、全球人形机器人挑战赛 GHRC、人形机器人本体,以及 VLA 的核心概念。
第 1 课不是单纯的“开营介绍”,而是帮助所有学员建立一张完整地图:接下来 20 天线上学习和 2 天线下真机实训,我们到底要做什么、怎么做、最后能拿到什么成果。
一、这不是听课,而是完成一条机器人开发链路
本次实训营的核心目标非常明确:不是让大家停留在概念层面,而是亲手走完一条完整的人形机器人开发链路。
这条链路包括:理解任务、读取数据、训练策略、推理验证、失败分析、项目复盘,最终在仿真和真机上完成 Demo 展示。
课程会围绕 GHRC 全球人形机器人挑战赛的四大典型任务展开,包括零件分拣、传送带分拣、泡沫嵌入和装箱。在线上阶段,大家会先基于官方 baseline 理解 Walker S2 仿真、LeRobotDataset、ACT 训练与推理流程;在线下阶段,再进入真机验证和成果展示。
也就是说,这不是“听完几节课了解一下人形机器人”,而是一次从数据到模型、从仿真到真机、从训练到分析的完整实践。
二、完整参加实训营,你能拿到五件套成果
本次实训营设计了一条非常清晰的成果路径:做出来,讲清楚,拿得出,被认可,走得远。
第一件成果,是项目 Demo。
这是整个实训营最硬的产出。学员需要在仿真环境中跑通 GHRC 四大任务,并在线下真机环节完成验证。一个真正跑起来的 Demo,远比“我学过 VLA”“我看过 ACT”更有说服力。
第二件成果,是训练分析报告。
模型跑通只是开始,能说清楚为什么成功、为什么失败,才是真正的能力。报告中需要记录训练曲线如何理解,推理视频里机器人在哪一步出错,修改哪个环节后效果发生变化。这种能力,也是机器人算法工程师和普通调包选手之间的重要分水岭。
第三件成果,是展示视频或项目材料。
很多同学做完项目后,成果只停留在本地代码和零散截图里,很难对外展示。本次实训营会帮助大家把 Demo、训练过程和分析结果整理成可以用于作品集、比赛、求职和社区展示的项目材料。
第四件成果,是结营证书与项目认证。
本次认证不是简单的参与证明,而是任务完成认证。课程会从线上参与、随堂作业、仿真训练、线下 Demo 和项目复盘几个维度综合评定。证书分为结业证书和项目认证证书,后者面向核心开发者、参赛选手与优秀学员。
第五件成果,是进入优必选开发者生态的机会。
实训营结束不意味着结束。表现突出的学员,可以继续接入 Thinker cosmos 社区、GHRC 赛事和优必选开发平台,把这次训练营作为进入人形机器人开发生态的起点。
三、学习路径:线上先行,线下验证
整个课程分为线上 5 次直播和线下 2 天真机实训。
第 1 课,是实训营介绍、本体亮相与 GHRC 入门。大家需要完成资源入口表和环境自检表,先搞清楚官方 baseline、赛事数据集、技术文档、仿真资产分别是什么。
第 2 课,会进入数据采集与 LeRobotDataset。重点不是泛泛而谈“数据很重要”,而是直接看 GHRC episode 里四路相机、状态、动作、任务指令到底怎么组织。
第 3 课,会讲 ACT 训练链路。大家会理解一个模仿学习策略如何从数据中学会动作,以及训练配置怎么写、怎么改、怎么复现。
第 4 课,会重点分析训练效果和 GHRC 迁移。模型为什么会抖?为什么仿真成功但推理失败?视频回放应该看什么?这些都会在这一课展开。
第 5 课,会做算法对比和线上项目收口。学员需要完成线上项目报告和算法对比表,为线下真机 Demo 做准备。
最后,线下 2 天会进入 Walker S2 EDU 和天工行者真机实践,完成项目联调、Demo 展示、训练分析报告和认证评审。

四、为什么第 1 课要讲 VLA?
因为今天的人形机器人开发,已经不能只看单点模块了。
过去机器人系统通常被拆成“感知、规划、控制”几个层级。
相机负责看,检测模型负责识别,规划器负责算轨迹,控制器负责执行。这套方法稳定、可解释,但在复杂开放场景中,往往需要大量人工建模和工程调参。
而 VLA,也就是 Vision-Language-Action,代表了另一条路线:
机器人输入图像和语言指令,策略模型直接生成动作序列,再交给底层控制系统执行。
简单说,VLA 让机器人能够“看图、听指令、直接动手”。
Vision 是机器人的眼睛,负责把 RGB 图像、深度图、点云、触觉、力觉等观测编码成模型可以理解的特征。
Language 或 LLM 是机器人的大脑,负责理解任务指令,比如“把工件分拣到蓝色框里”,并结合视觉信息进行推理。
Action 是机器人的手,负责把推理结果变成可执行动作。动作可以是关节角度,也可以是末端位姿;可以被离散成 token,也可以用连续模型生成。
这三部分接起来,就是完整的 VLA。
五、从 LLM 到 VLM,再到 VLA

VLA 不是凭空出现的,它是顺着大模型的发展路线一步步长出来的。
第一阶段是 LLM,也就是大语言模型,比如 GPT、LLaMA、Qwen。它们能理解文本、推理、写代码、总结内容,但只能处理语言。
第二阶段是 VLM,也就是视觉语言模型,比如 LLaVA、Qwen-VL、PaliGemma。它们在语言模型基础上接入视觉编码器,可以看图说话,但仍然只能回答,不能真正执行动作。
第三阶段是 VLA,也就是视觉语言动作模型。它在 VLM 的基础上接入动作输出,让模型不仅能看、能说,还能真正控制机器人动起来。
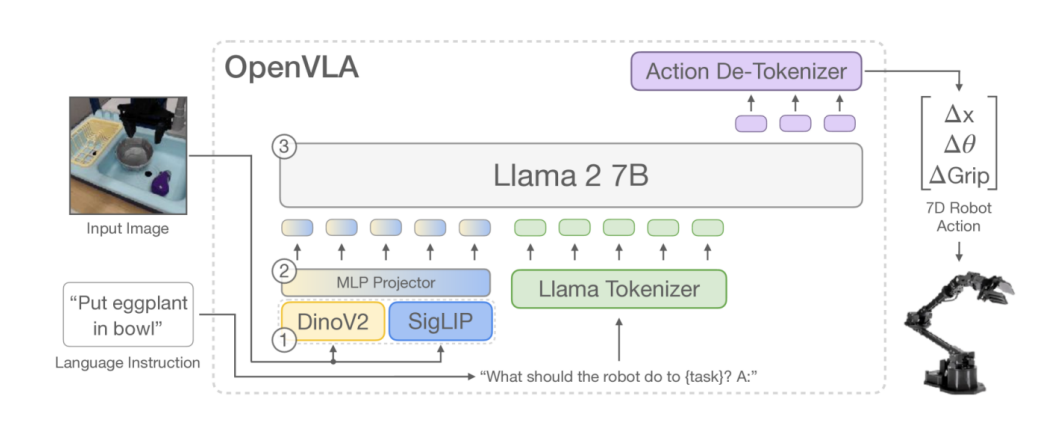
OpenVLA 是其中非常有代表性的开源工作。它用视觉语言模型作为骨干,在大量机器人示范数据上微调,让模型直接输出机器人动作。它的重要意义在于,把 VLA 从少数大公司的私有系统,变成了更多开发者可以复现、研究和改进的开源路线。
当然,VLA 也不是只有一种路线。OpenVLA 代表的是离散动作 token 路线;而 π0、GR00T 等工作则更多采用连续动作生成路线,例如 Flow Matching。这些内容会在后续课程中继续展开。
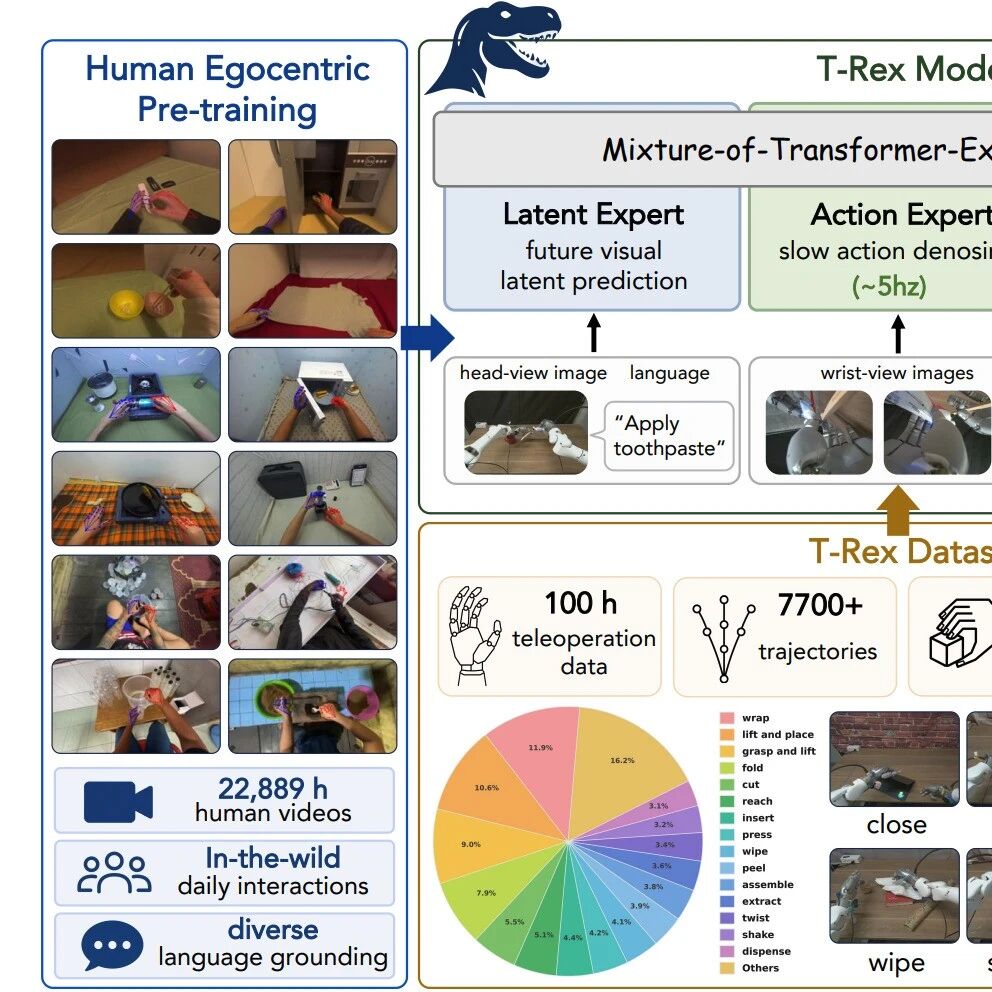
六、VLA 最大的瓶颈不是模型,而是数据
很多人一提 VLA,第一反应是模型架构、参数规模、GPU 算力。
但真正做过机器人训练的人都知道,最难的往往不是模型,而是数据。
机器人数据和互联网图文数据完全不同。它需要真实操作,需要动作记录,需要多相机同步,需要状态和动作对齐,还要覆盖足够多的物体、场景、姿态、失败情况和边界条件。
没有高质量数据,再强的模型也很难学会稳定操作。
这也是为什么本次课程专门安排第 2 课讲数据采集与 LeRobotDataset。学员需要真正看懂一个 episode 是什么,机器人每一帧观测里有什么,状态和动作如何保存,人的操作如何变成策略可以学习的数据。
一句话总结:VLA 的燃料不是 PPT,而是数据。
七、第 1 课作业:先把入口和环境搞清楚
第 1 课结束后,学员需要完成两个基础作业。
第一个作业是官方资源入口表。
大家需要写清楚 baseline、赛事数据集、技术文档、仿真资产分别用于什么。比如 GHRC 官方 baseline 用于 Walker S2 仿真、ACT 训练与推理;赛事数据集提供四大任务的仿真 episode;赛事规程定义任务与评分;Thinker cosmos 则是报名与开发者社区入口。
第二个作业是环境自检表。
大家需要说明自己的 GPU、磁盘、系统、Isaac Sim 条件,或者是否使用助教机。跑通 GHRC baseline 对硬件有一定要求,例如显卡、内存、存储、CUDA、Docker、NVIDIA Container Toolkit 等。
硬件不足的同学也不用担心。
本次课程会提供助教机上的训练结果和推理视频,作业可以走“读懂流程 + 分析结果”的路线。重点不是每个人都必须从第一天开始本地跑满训练,而是先建立正确的理解框架。
八、下一课:看懂机器人数据
第 1 课帮助大家完成了三件事:
知道实训营要产出什么,知道 GHRC 和优必选开发者生态是什么,知道 VLA 为什么是人形机器人开发的重要入口。
下一课,我们会正式进入数据采集与 LeRobotDataset。
如果说第 1 课是在看地图,第 2 课就要开始拆发动机。我们会一起看 GHRC 数据集里的 episode、四路相机、状态、动作和任务指令到底怎么组织,理解人的操作如何变成机器人策略能够学习的数据。
人形机器人开发不是只看宣传片,也不是只背几个模型名。
真正重要的是:你能不能把任务跑起来,能不能看懂失败,能不能一步步把成功率做上去。
这也是本次实训营最想带大家完成的事。
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀