StableVLA团队 投稿
量子位 | 公众号 QbitAI
近日,北京大学、清华大学、星尘智能等机构联合提出StableVLA,相关工作StableVLA: Towards Robust Vision-Language-Action Models without Extra Data已被ICML 2026接收。
该工作面向真实机器人部署中的视觉鲁棒性问题,提出轻量级IB-Adapter,在不依赖额外扰动数据和大规模鲁棒性增强的情况下,对视觉特征进行筛选与对齐。
也就是说,机器人在遇到噪声、模糊、遮挡、镜头污染等视觉干扰时,仍能保持w更稳定的任务执行能力。

无需额外数据,提高VLA的稳定性
长期以来,VLA 模型的发展很大程度上依赖更大规模的数据、更大的模型参数量,以及更复杂的训练流程。
这些方法在标准评测和理想视觉条件下取得了显著进展,但当机器人真正进入真实环境时,视觉输入往往并不稳定:
传感器噪声、运动模糊、光照变化、遮挡、镜头污染等因素,都可能使模型的执行能力出现明显下降。
这一问题的核心在于,真实世界中的视觉干扰几乎不可能被训练数据完整覆盖。即使通过数据增强或扰动模拟来提升鲁棒性,也往往只能覆盖有限的噪声模式,难以应对开放环境中不断变化的复杂视觉条件。
因此,一个自然的问题是:能否不依赖额外扰动数据,而是从模型结构本身提升VLA的稳定性?
StableVLA 正是围绕这一问题展开。该工作基于VLA-Adapter的高效 VLA 范式,进一步分析了视觉扰动下模型性能退化的原因,并发现视觉特征进入策略模型前的projector / adapter模块,是影响鲁棒性的关键环节之一。
传统MLP projector在干净输入下能够完成特征映射,但在受到噪声或模糊干扰时,也容易将与任务无关的视觉扰动一并传递给后续策略模型。
为此,研究团队提出了轻量级Information Bottleneck Adapter(IB-Adapter)。
该模块在视觉特征进入策略模型前进行信息筛选,通过建模通道间的相关性,抑制不稳定的噪声特征,同时保留与任务执行相关的语义信息。
进一步地,StableVLA采用Fused IB-Adapter结构,将鲁棒语义筛选与细粒度空间信息保留结合起来,使模型在面对视觉干扰时仍能保持较稳定的操作能力。
实验结果表明,StableVLA在LIBERO、CALVIN以及真实机器人场景中均展现出稳定的鲁棒性提升。
尤其是在噪声、模糊、镜头油污、物理遮挡等干扰条件下,StableVLA相比原始VLA-Adapter和其他强基线模型表现出更小的性能下降。
值得注意的是,在14× smaller backbone、80× smaller training data 的设置下,StableVLA仍然取得了具有竞争力的zero-shot robustness,说明高效小模型也可以通过合适的结构设计获得较强的真实环境稳定性。
从长期意义来看,StableVLA并不是简单依赖更大模型或更多数据来提升VLA能力,而是尝试从视觉-动作对齐结构本身出发,探索更高效、更可靠的机器人基础模型设计。
对于真实机器人部署而言,这类方法有望降低训练和部署成本,也为小规模VLA模型在开放环境中的稳定应用提供了新的思路。
论文中的实验显示,IB-Adapter在不引入额外扰动数据的情况下提升了模型在合成和真实视觉干扰下的鲁棒性,并且额外参数量较小。
详解StableVLA框架
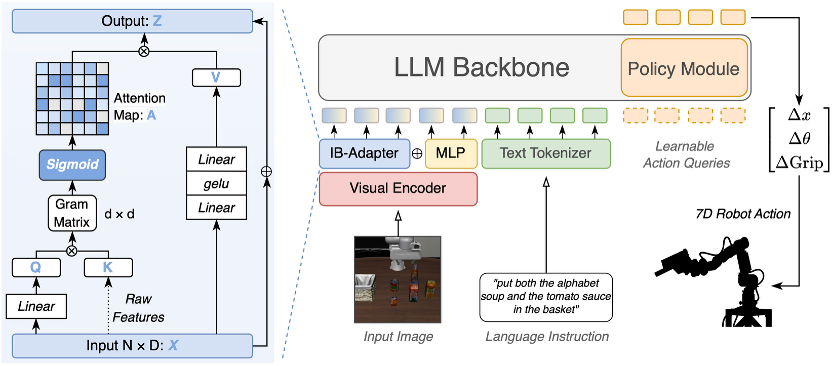
StableVLA 基于VLA-Adapter的高效VLA范式构建,整体仍遵循视觉-语言-动作模型的基本流程:
模型接收图像观测与语言指令,经由视觉编码器提取视觉特征,再通过projector/adapter完成视觉特征到策略模型输入空间的对齐,最终预测机器人动作。
与标准 VLA-Adapter 不同的是,StableVLA 并没有依赖额外扰动数据或大规模鲁棒性增强,而是将重点放在视觉特征进入策略模型之前的对齐模块上。
研究团队发现,当输入图像受到噪声、模糊、遮挡等干扰时,传统MLP projector容易将任务无关的视觉扰动一并传递给后续策略模型,进而导致执行性能下降。
为此,StableVLA将原有的MLP projector替换为轻量级Information Bottleneck Adapter(IB-Adapter),希望在视觉特征进入策略模型前完成一次更有选择性的信息筛选。
B-Adapter的核心思想是:并不是所有视觉特征都同样有用。
真实环境中的视觉输入往往同时包含任务相关信息和无关干扰,例如物体位置、抓取目标是有用信息,而噪声、模糊、局部遮挡则可能成为干扰。
因此,IB-Adapter从Information Bottleneck的角度出发,通过建模视觉特征通道之间的相关性,对视觉信息进行筛选。
具体来说,模块会计算通道维度上的相关性矩阵,并通过Sigmoid gating抑制不稳定或与任务无关的噪声通道,同时保留更稳定的语义特征。
IB-Adapter并不是让模型“看得更多”,而是让模型在视觉特征进入策略模型前,先学会“哪些信息更值得保留”。

研究团队在LIBERO、CALVIN以及真实机器人平台上对StableVLA进行了系统评估。
实验覆盖了多种合成视觉扰动和真实物理干扰,包括噪声、模糊、镜头油污和遮挡等。
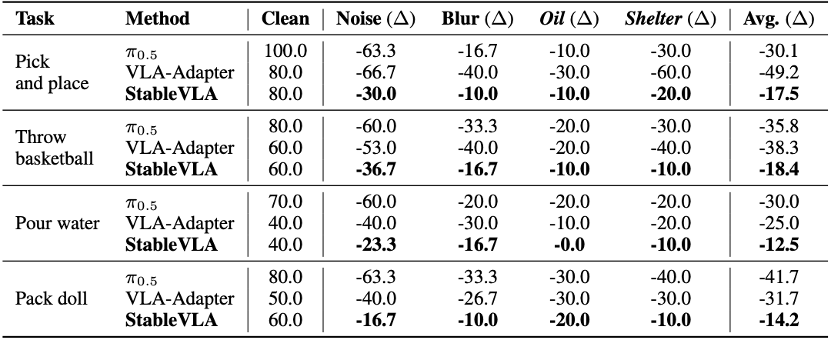
结果显示,StableVLA在这些视觉干扰下相比原始VLA-Adapter和其他强基线模型表现出更小的性能下降。
在真实机器人任务中,StableVLA也能在Pick and Place、Throw Basketball、Pour Water、Pack Doll等任务中保持更稳定的执行能力。
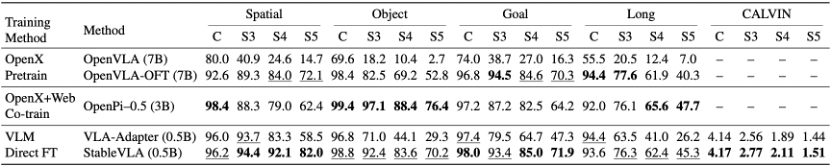
值得注意的是,StableVLA 继承了VLA-Adapter小模型和高效训练的优势。在14× smaller backbone、80× smaller training data的设置下,仍然取得了具有竞争力的zero-shot robustness。
这也说明,提升VLA鲁棒性并不一定只能依赖更大的模型和更多的数据,结构层面的设计同样重要。
论文标题:StableVLA: Towards Robust Vision-Language-Action Models without Extra Data
论文地址:https://arxiv.org/abs/2605.18287
项目地址:https://dagroup-pku.github.io/StableVLA/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟










