CBA 直接键合 | 16 层垂直堆叠 | 256L 字线 | H³ 混合架构 | LHB 延迟隐藏 | 张量级预取 | 共享预计算 KV Cache | 吞吐量功耗比

核心概述(TL;DR)
推理侧核心矛盾转移,引爆新型存储层级(HBF)需求:长上下文、RAG 及大参数 MoE 模型的爆发,使推理核心瓶颈从“算力制约”彻底转向“内存墙与 TCO 制约”。传统 HBM 受限于物理空间与高昂成本,无法独立承载海量数据驻留;HBF 凭借“高容量+高并发”特性,精准定位为大模型推理中“海量只读数据”(静态权重、预计算 KV Cache)的专用存储层。 软硬协同硬核“破墙”,完全隐藏微秒级物理延迟:针对 NAND 闪存微秒级(~20μs)物理读取延迟这一致命痛点,系统利用 LLM 推理严格的确定性访问模式,通过底层逻辑层引入约 40MB 的双缓冲延迟隐藏缓存(LHB)进行张量级预取,在系统宏观层面将 HBF 与“无限容量 HBM”的性能差距缩窄至仅 2.2%。 架构跨界融合,近存储处理(PNM)消除总线瓶颈:HBF 通过 CBA 键合、16 层垂直堆叠与分布式子阵列重构,在单栈实现 512GB+ 容量与 TB/s 级内部带宽。其进化形态(如 HAVEN 架构)在存储底层逻辑层直接硬连线集成近存储搜索单元(NSP),使 RAG 全精度向量重排实现片上“零移动”就地计算,重排吞吐量最高飙升 20倍。 商业化时间表锚定,后道生态面临工艺与材料重塑:闪迪与 SK 海力士正基于 OCP 框架全面推进 HBF 标准化,确立了“2H2026 推出 Gen1 样品,1H2027 步入商用系统部署”的明确时间表。这将直接倒逼后道封装(OSAT)向高精度热压键合(TC Bonder)演进,并大幅拉动超高平整度 CMP 浆料等前沿基础材料的供应链需求。
00
摘要
随着大语言模型(LLM, Large Model)向长上下文与检索增强生成(RAG, Retrieval-Augmented Generation)架构演进,推理(Inference)阶段对内存容量与流式读取带宽的物理需求呈指数级增长。传统的高带宽内存(HBM, High Bandwidth Memory)受限于二维芯片 面积、密集互连的物理空间约束与制造成本,面临严苛的容量扩展上限,导致 AI 计算系统在处理大规模长序列数据时遭遇显著的内存瓶颈(Memory Wall)与总体拥有成本(TCO, Total Cost of Ownership)制约。

高带宽闪存(HBF, High Bandwidth Flash)作为一种新型非易失性存储层级,通过 CMOS 直接键合阵列(CBA, CMOS Bonded Array)技术与多达 16 层 3D NAND 介质的垂直堆叠,结合底层的分布式子阵列(Distributed Subarrays)架构重构,在系统层面实现了存储容量与并发数据吞吐量的最优物理平衡。本文全面剖析 HBF 的微观物理结构集成、宏观系统级混合架构演进(包括 H³ 混合架构与 HAVEN 架构)、软硬协同的延迟隐藏调度机制以及标准化产业链生态。量化评估表明,HBF 在提供单栈 512GB 级海量容量的同时,能有效掩盖介质固有的物理读取延迟,显著提升 AI 推理系统的吞吐量与功耗比(Throughput per Watt),进而为新一代大模型数据中心提供极具经济效益与能效价值的近端存储硬件范式。

01
微观物理结构与阵列重构
本章聚焦高带宽闪存(HBF, High Bandwidth Flash)的底层物理架构,深度解析其如何通过微观结构集成与存储阵列的物理重构,克服传统 NAND 闪存的物理限制,从而适配 AI 推理系统的存储需求。
1.1 物理集成技术机制
高带宽闪存(HBF)的微观结构高度依赖于先进的异构集成与封装工艺,其核心在于打破传统 NAND 闪存的架构限制,实现逻辑控制与存储介质在微观层面的物理协同。

CBA(CMOS Bonded Array)技术的物理架构:CBA(CMOS 直接键合阵列)技术是构筑 HBF 超高带宽特性的基础物理架构。在传统架构中,外围电路与存储阵列通常在同一平面或以较低效的方式集成,而 HBF 通过将底层的 CMOS 逻辑电路层(Logic Die)与上层的 NAND 存储阵列进行直接键合,实现了架构的升维。这种键合机制在有限的芯片 面积内,最大化了读出放大器(Sense Amplifiers)的数量。 从物理层面来看,CBA 架构极大地提升了外围逻辑电路的运行速度与分布密度,使得底层控制器能够同时并行控制成百上千个 NAND 通道,这是实现 TB/s 级带宽的关键。同时,底置逻辑层的设计有效缩短了数据传输路径,显著降低了存储单元互连时的寄生电容与电阻(RC 延迟)。这不仅为超宽字(wide-word)的高带宽数据传输提供了物理通道,还大幅优化了系统的功耗表现。 16 层 3D NAND 垂直堆叠与异构集成:在单层闪存容量扩展逐渐逼近物理极限的情况下,为了满足 AI 推理对海量数据的存储需求,HBF 的第一代产品采用了高达 16 层核心裸片(Core Die)的垂直堆叠结构,以实现总容量的最大化(单栈可达 512GB 至数 TB)。 在堆叠的物理集成机制上,HBF 直接复用了高带宽内存(HBM)成熟的先进封装互连技术。它通过数千个硅通孔(TSV, Through-Silicon Via)直接穿透各层 NAND 芯片 ,实现跨 Die 的垂直电信号高速贯通。同时,在层与层之间、以及核心存储层与底层逻辑层之间,利用微凸块(Microbump)完成极高密度的物理与电气连接。这种类似 HBM 的垂直互连物理结构,彻底打破了传统 NAND 经由引脚和长布线传输数据的瓶颈,将 NAND 闪存完美嵌入到 AI 加速器的超高速计算生态中。 热机械应力与良率保障:实现 16 层高密度 NAND 晶圆的垂直堆叠并非单纯的物理叠加,其背后隐藏着严苛的物理挑战。核心逻辑如下: 16 层高密度 NAND 晶圆垂直堆叠 会导致芯片 内部的热机械应力(Thermo-mechanical stress)显著增加。由于 NAND 闪存的物理特性比 DRAM 更容易受到热量和压力的破坏,在利用热压键合(TC Bonding)工艺将各个 Die 压合时,极易发生芯片 形变甚至破裂(Crack)。 因此,必须在制造与封装工艺中采用专有的超低 Die 翘曲(Ultra-Low Die Warpage)技术,精苛控制温度与压力,以抑制晶圆形变。 这一机制的最终目的,是确保多层极其脆弱的 NAND 晶圆在热压键合过程中的物理稳定性,从而保障 TSV 与微凸块的互连导通率,最终实现 HBF 的规模化制造与高良率。
1.2 分布式子阵列(Distributed Subarrays)重构逻辑
为了使 NAND 介质的读取性能完美匹配 AI 推理系统(如 RAG 架构中的向量检索)的极高带宽需求,高带宽闪存(HBF)对传统的存储阵列结构进行了根本性的工程重构,完成了从“容量优先”向“带宽与并发优先”的底层逻辑转变。

单一平面与分布式子阵列设计的对比:在传统的商业级 3D NAND 架构中,为了追求极致的存储密度并降低制造成本,晶圆设计通常采用大规模的单一平面(Monolithic planes)结构。这种庞大的物理阵列虽然能最大化存储容量,但不可避免地导致了字线(Wordline)与位线(Bitline)的物理长度极长,进而产生极高的寄生电容(Parasitic capacitance)与极粗糙的访问粒度。这种粗放的结构完全无法适应 AI 推理和细粒度向量检索所需的快速、高频次访问模式。 为了打破这一物理限制,HBF 在架构上进行了一次“化整为零”的革新:它将原本庞大的单一物理平面,精细切分为大量小型的分布式子阵列(Distributed Subarrays)。在这一重构架构下,每个微小的子阵列都配备了独立的局部字线/位线驱动器(local wordline/bitline drivers)和读出放大器(sense-amplifiers)。例如,在基准的 HBF 架构中,其子阵列被精细划分至 4KB 的页面大小(Page size)与 64 个区块(Blocks)的配置,从而赋予了整个存储层极其密集的网格化控制能力。 从物理微缩到系统级并发:这一阵列重构并非简单的物理分割,而是引发了一系列从微观物理层到宏观系统层面的性能质变。其核心逻辑如下:
采用分布式子阵列设计:打破了传统单一平面的长布线限制,在物理层面大幅缩短了局部字线与位线的物理长度。 降低延迟与能耗:物理路径的缩短,显著降低了布线所产生的寄生电容与电阻(即 RC 延迟,RC of cell interconnections),同时大幅降低了电信号传输时的单次访问能耗(Access energy)。 提升并行度:独立的局部驱动器和缩减的 RC 延迟,大幅提升了存储阵列内部的并发访问能力(Internal Parallelism)。使得整个 HBF 芯片能够同时激活成百上千个微小的读写通道,呈现出极宽的内部并行度。 适配大模型特征:这种极高的内部并发性和更细的访问粒度(Finer access granularity),彻底消除了传统 NAND 的性能瓶颈,使其能够完美满足大语言模型推理(如 KV Cache 读取)与十亿级向量检索(如 IVF-PQ 重排阶段)中细粒度、高并行的存取需求。
1.3 最优配置参数的工程权衡
分布式子阵列的物理参数(层数、页大小、区块数量)直接决定了高带宽闪存(HBF)在容量、带宽与功耗上的系统级表现 。由于物理定律的限制,各项性能指标往往呈反向按比例缩放,因此必须通过严格的工程权衡以寻找最佳物理平衡点。

针对向量重排(Reranking)工作负载的架构探索:在检索增强生成(RAG)的近似最近邻搜索(ANNS)重排操作中,数据访问呈现出高频、细粒度与高度并行的特征。为了匹配这种负载,研发团队对子阵列的尺寸进行了深度的模拟评估: 模拟结果表明,过大的子阵列(例如大页尺寸、多区块)虽然能够有效提升存储容量密度,但不可避免地会导致阵列内部连线变长,并使得 3D 结构的寄生效应显著增加。这会直接推高单次读取的能耗与访问延迟。 更关键的是,HBF 被严格限制在与 HBM 相似的 30W 系统热设计功耗(Thermal Envelope)内。在此功耗墙下,过高的单次访问能耗会导致系统迅速触发功率限制,进而严重削弱实际可输出的并发读取带宽。相反,如果过度缩小阵列尺寸,虽然能够改善延迟与降低能耗,却会大幅牺牲芯片的总存储容量,无法满足十亿级向量库的片上存储需求。 最优物理参数界定:经过对容量、能耗、带宽和延迟的综合建模与评估,“4KB 页大小(Page Size)、64 个区块(Blocks)、256 层(Layers)字线堆叠”被确立为 HBF 的最优基础架构配置。 256 层堆叠:系统分析显示,要在 8 层核心裸片(8-Hi stack)中实现 512GB 的单栈大容量,至少需要 128 层字线堆叠。采用 256 层(256L)的堆叠方案,不仅超越了 128 层或 192 层的存储密度,还为未来更庞大的向量数据库留足了设计余量,确保了坚实的基础存储密度。 4KB 页大小与 64 Blocks 组合:这一精细尺寸组合在提供充足内部并行度的同时,精准地将读取能耗控制在了 30W 的物理封装功率上限内。模拟证实,当区块数量超过 128 或页尺寸过大时,会因触发功耗墙而导致严重的带宽衰减(Bandwidth degradation)。4KB 页与 64 Blocks 的组合完美规避了这一问题,成功在总容量、系统能效(带宽/功耗比)与读取延迟之间实现了最佳的物理平衡。
02
宏观系统级混合架构演进
高带宽闪存(HBF, High Bandwidth Flash)的物理特性决定了其无法完全替代传统的动态随机存取存储器(DRAM),而是需要通过宏观系统级的混合架构设计,与高带宽内存(HBM)及计算单元(xPU)进行深度协同。本章将剖析 HBF 在系统架构层面的三大主流演进方向、近存储处理机制以及前沿的异构封装专利布局。
2.1 三大主流演进架构分析
随着大语言模型(LLM)的不断演进,其推理工作负载对内存容量与带宽的需求呈现出指数级增长的态势。为了突破现有的“内存墙”瓶颈,业界针对如何将高带宽闪存(HBF)高效集成至AI硬件系统,探索并提出了三种主流的物理与逻辑演进架构路径:
共存架构(Coexistence):共存架构是一种在物理空间与性能之间寻求平滑过渡与极致平衡的方案。该架构的核心在于,在同一个芯片封装(Package)内,将原有的部分高带宽内存(HBM)堆叠直接替换为 HBF 堆叠。 从系统层面来看,这种设计的最大优势在于:在保持系统整体物理尺寸(Footprint)与流式读取带宽(Streaming read bandwidth)基本不变的前提下,HBF 的引入能够为系统提供高达 8 至 16 倍的读优化(Read-optimized)内存容量。在此架构下,系统对读(Read)和读写(R/W)分区进行了独立的深度优化,HBF 被专门用于承载极度消耗容量的模型权重(Weights)与键值缓存(KV Cache)。这种架构无需对现有的计算核心(xPU)进行颠覆性改造,便能在系统层面上兼顾 HBM 的极致带宽与 HBF 的极高容量密度。
解耦架构(Disaggregated Architecture):解耦架构的提出,源于对大语言模型推理底层逻辑的深度剖析。在 LLM 推理过程中,预填充(Prefill)阶段因需要并行处理所有输入 Token,主要受限于计算能力(Compute bound);而解码(Decode)阶段由于是自回归地逐个生成 Token,因而高度受限于内存带宽与容量(Memory bound)。 解耦架构正是通过在物理硬件上将这两个阶段进行彻底分离,来实现资源的最优配置。在此架构背景下,HBF 被配置为 Decode xPU(专用解码处理器)的专用存储池,专门用于存储解码阶段所需的海量权重与 KV Cache。这种硬件级别的计算解耦带来了多重显著收益:它不仅极大地提升了处理大型稀疏混合专家模型(MoE)的效率,还能通过支持更庞大的批处理规模(Large batch size)来分摊内存访问成本,有效降低多 GPU 之间的跨节点同步工作负载(Synchronizing workload),从而显著节省系统的总体功耗与运行成本(TCO)。 H³ 混合架构(HBM+HBF Hybrid):H³ 架构(HBM 与 HBF 混合架构)代表了存算一体化演进的更高级形态。该架构旨在通过明确的数据职责划分,最大化 HBM 与 HBF 的协同效能。

在数据分布逻辑上,HBM 利用其极低的访问延迟,负责处理高频更新的动态缓存数据(Tiered cache)以及部分较小的 MoE 模型权重;而 HBF 则发挥其大容量且非易失的特性,专管处于只读模式的庞大长上下文数据(Longer context length)与核心模型权重。 在硬件互连与寻址机制上,HBF 作为 xPU 模块的容量扩展,在物理上直接与 HBM 相连。其统一寻址的实现高度依赖于底层裸片(Base Die)的路由分配:在 HBM 的底层逻辑裸片中,内置的地址解码器与路由器(Address decoder & router)将内存访问物理划分为两条独立路径,分别指向 HBM 与 HBF。这一机制使得主机(Host)能够通过统一的地址空间无缝访问这两种不同介质,如同访问同一块主存。此外,GPU、HBM 底层裸片与 HBF 底层裸片之间,通过裸片到裸片(Die-to-Die, D2D)接口实现了底层物理的紧密连接与超高速数据传输,从而确保了系统级数据流转的高效与低延迟。
2.2 近存储处理(Processing-Near-Memory)创新:HAVEN 架构
在检索增强生成(RAG)系统中,近似最近邻搜索(ANNS)的倒排索引与乘积量化(IVF-PQ)算法是平衡内存效率与检索速度的核心组件。然而,为了追求更高的检索召回率(Recall),系统必须执行全精度向量重排(Reranking)操作。在传统硬件架构下,由于 GPU 内置的 HBM 容量极其有限(通常仅几十到上百 GB),根本无法容纳动辄数百 GB 甚至 TB 级别的十亿级全精度原始向量库,这些庞大的数据只能被迫存放在外部主机的 DRAM 或 NVMe 固态硬盘(SSD)中。这导致在重排阶段,系统必须跨越 PCIe 总线频繁拉取全精度向量,这种极其低效的物理级数据搬移(Off-GPU data movement)引发了严重的延迟激增与吞吐量(QPS)断崖式衰减,成为了制约大模型检索能力定义的根本物理瓶颈。

针对这一阻碍系统扩展的物理壁垒,HAVEN(High-Bandwidth Flash Augmented Vector ENgine)架构提出了一种近存储处理(Processing-Near-Memory, PNM)机制,完成了从“数据找计算”到“计算找数据”的范式转移。
架构集成(硬件级重构):HAVEN 在物理层面极其精妙地利用了高带宽闪存(HBF)底层的 CMOS 逻辑层(Logic Die),在其中直接硬连线集成了一个专用的近存储搜索单元(NSP, Near-Storage Search Unit)。该计算单元构建了一条完整的、无需 GPU 核心参与的片上重排流水线,具体包含四大核心模块:
重排队列(Rerank Queue):作为与 GPU 通信的桥梁,负责接收并缓冲来自 GPU 粗筛阶段生成的候选向量 ID(Candidate IDs)。 地址生成器(Address Generator):将候选 ID 直接转化为对应全精度向量在 HBF 三维存储阵列中的物理读取地址,并向 HBF 发出读取请求。 距离计算模块(Distance Computation):内置并行的乘加器(MACs)阵列。当全精度向量从上方 NAND 阵列取回后,直接在存储底层就地计算其与查询向量(Query)的精确距离。 Top-k 排序单元(Top-k Unit):利用并行双调整排序器(Bitonic sorter),在底层直接筛选出最终的最高匹配度结果,并仅将这极少量的高价值结果返回给 GPU。

从根源消除通信壁垒:HAVEN 架构通过近存储处理引发了深远的系统级性能质变。其核心逻辑如下:
计算下放:将 RAG 系统中最耗时、最消耗带宽的 IVF-PQ全精度向量重排操作,直接下放至芯片封装内部执行(利用 HBF 底层逻辑层的 NSP 单元)。 数据零移动:这一根本性的架构改变,使得重排所需的庞大全精度向量数据完全无需移出 HBF 存储阵列传输至 GPU,实现了高密度数据的“零移动”。 消除总线瓶颈:数据留在原地处理,彻底消除了传统架构中 PCIe 总线与外部 DDR 内存之间的数据传输物理瓶颈,规避了极高的跨组件通信延迟。 并发释放:同时,由于重排操作直接发生在 HBF 内部,它能够充分利用 HBF 内部重构的分布式子阵列所提供的超高并发读取带宽。最终,在处理十亿级规模向量检索时,该架构旨在突破外部带宽限制,完美满足检索增强生成系统对高吞吐与低延迟的苛刻要求。
2.3 前沿专利布局:终极异构形态
为追求更极致的物理互连效率,闪迪(SanDisk)在其最新获批的专利(专利号:US 12,430,274 B2)中提出了一种超越当前高带宽闪存(HBF)标准封装的“终极异构形态”,为彻底打破 AI 推理中的“内存墙”提供了一份极具前瞻性的物理蓝图。

核心工程诉求与封装架构设计:该专利的核心工程诉求是彻底缩短计算核心与海量非易失性存储介质之间的物理距离,以最小化数据搬移所产生的巨大能耗与延迟负担。 在封装架构的设计上,该专利进行了一次颠覆性的空间重构:它将多核处理器(如大型图形处理单元 GPU 或 AI 加速器)直接物理键合(Bonding)在 CBA(CMOS Bonded Array)NAND 存储瓦片(Memory Tile)的顶部。在这个创新的堆栈中,底层是由大规模 NAND 存储阵列与 CMOS 逻辑电路层紧密结合而成的 CBA 瓦片,顶层则是计算核心。同时,为了兼顾系统中不同特性的内存需求,高带宽内存(HBM)半导体堆栈被环绕安装在这个“处理器-CBA 存储”组合堆栈一侧或多侧的共享中介层(Shared Interposer)上。 理论上限与能效评估:这种终极异构封装形态通过打破传统的物理隔离边界,在理论层面极大拔高了系统的能效与数据吞吐量上限。 首先,通过将处理器直接置于大面积的 CBA 存储瓦片之上,系统得以利用极其密集的硅通孔(TSVs)穿透存储芯片的无逻辑直通区,从而在处理器与底层存储之间创建极宽字(Wide-word,例如 1024 bit 甚至更高)的直接电气连接。这种极致的 3D 垂直互连设计大幅缩短了数据传输的物理路径,不仅轻松突破了现有的 I/O 带宽限制,还显著降低了长距离布线所带来的寄生电容(Parasitics)与高昂的驱动功耗。 其次,在此终极架构下,系统实现了高度优化的异构存算分工(Division of Labor):位于共享中介层上的HBM 专注于承载需要即时处理的、对延迟极度敏感的动态内存工作负载;而直接垫在处理器底部的大容量 NAND Tile,则利用其超宽的高带宽接口,专门负责读写密集型操作以及超大规模数据集(如完整的 MoE 模型权重或十亿级向量特征库)的极近端存储。 这一设计让海量存储与极致计算在微观尺度上完美融合,从而在理论上限层面实现了系统整体能效(Performance per Watt)与大模型数据吞吐量的双重最大化。
03
软硬协同优化与 AI 推理工作负载适配
本章聚焦高带宽闪存(HBF)在实际大语言模型(LLM)推理场景中的应用,深入分析软硬件协同优化机制,并论证 HBF 物理特性与 AI 推理工作负载的严谨适配性。

3.1 大模型推理的内存约束量化分析
随着 AI 模型架构的深度演进,推理阶段对内存容量的需求呈现出非线性的物理扩张态势,系统正面临着前所未前且极度严苛的容量瓶颈。
混合专家模型(MoE)的静态权重需求:为了在控制计算成本的同时提升模型生成质量,当前的顶级大语言模型普遍转向了混合专家(MoE)架构。MoE 架构通过稀疏激活机制(仅选择性激活部分专家参与单次推理)来提升模型效能,但这必然需要极大的物理存储空间来容纳数以十计甚至数百计的庞大专家参数。 最新行业趋势的数据充分量化了这一增长:例如,DeepSeek v3 模型内部集成了多达 256 个专家,Kimi K2 模型的专家数量更是高达 384 个,而拥有 4000 亿参数(400B)的 Llama 4 Maverick 也采用了 128 个专家的重度配置。在推理过程中,这些极其庞大的静态模型权重必须被整体加载并常驻于内存中,直接导致了内存需求急剧膨胀,进而极大地加剧了节点间的通信延迟与系统的物理存储负荷。 长序列处理与缓存增强生成(CAG)的内存约束:除了模型本身参数的激增,模型处理长上下文的方式也正在不断挑战物理内存的极限。推理模型(Reasoning Models)在输出最终可见结果前,会像人类分步骤解决问题一样,生成极其长序列的中间“思考”标记(Thought Tokens)。这种为了提升质量而增加的额外“思考”步骤,对系统的内存容量施加了极高的物理压力。 与此同时,为了提高长序列数据在多用户并发下的检索与推理效率,检索系统广泛采用了缓存增强生成(CAG, Cache Augmented Generation)技术,该技术要求系统在运行前载入并长期驻留极其庞大的共享预计算键值缓存(Pre-computed KV Cache)。与每次都需要检索外部数据库的 RAG 不同,CAG 倾向于将海量知识直接转化为 KV Cache 常驻于近端内存中,以此换取极致的响应速度。以处理极长序列的 Llama 3.1 405B 模型为例进行量化评估:仅仅为了处理 1M 长度的上下文序列,系统就需要分配约 540GB 的纯 KV Cache 存储空间;而当处理序列长度扩展至 10M 时,这一单项内存需求将呈指数级暴增至 5.4TB。 当前最新一代 GPU 所搭载的 HBM3e 单卡容量通常仅为 192GB 左右。若试图将此类海量数据完全存储于传统的高带宽内存(HBM)中,单次计算任务就必须强制绑定合并数十张高端 GPU 才能勉强容纳 these 只读缓存,这不仅会产生巨大的 GPU 间数据通信负荷(Overhead),还将导致极高的硬件采购成本与难以承受的系统运行总功耗,最终使 AI 推理的基础设施面临不可逾越的物理与经济限制。
3.2 确定性访问模式与延迟隐藏机制(LHB)
将高带宽闪存(HBF)成功集成至 AI 推理系统中,面临的最核心挑战是必须首先克服 NAND Flash 固有的物理访问延迟缺陷。这无法单纯依靠物理介质的改良,而是需要依赖深度的软硬协同(Hardware-Software Co-design)机制。
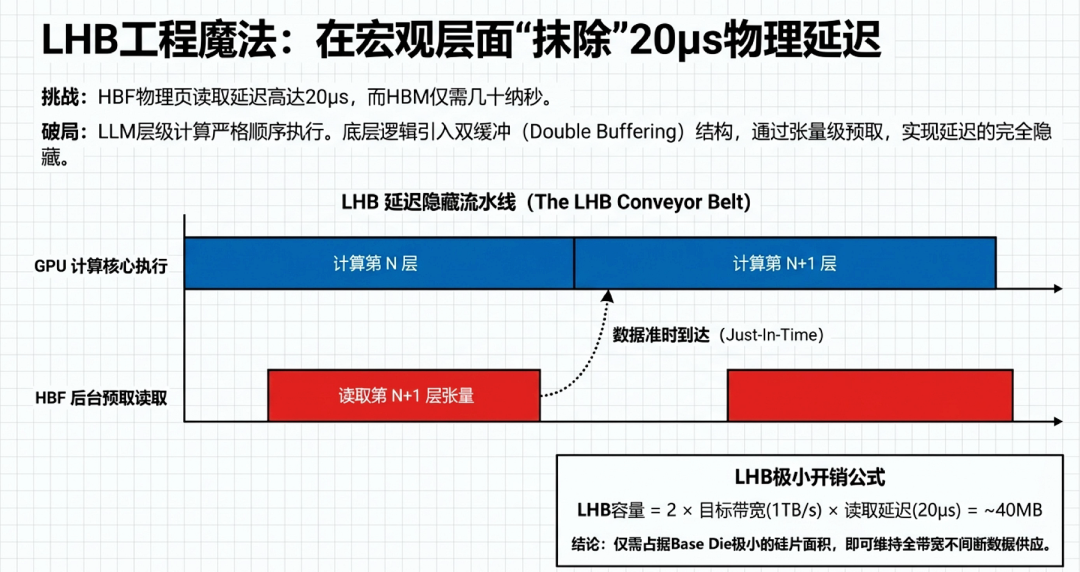
面临挑战:微秒级与纳秒级的鸿沟:虽然 HBF 在容量上具备显著优势,但作为基于 NAND Flash 的非易失性存储介质,其固有的物理读取机制成为了一个致命瓶颈。传统的 DRAM 基高带宽内存(HBM)能够提供极快的纳秒级(10-100ns)读取延迟。相比之下,HBF 的页读取延迟(Page-based reads latency)通常在微秒级别(例如高达 20μs)。这种跨越几个数量级的延迟差异意味着,如果让计算核心直接访问 HBF,将导致极其严重的系统等待(Stall)与计算单元闲置,完全扼杀其超高并发带宽带来的吞吐量优势。 从工作负载特征到底层硬件预取:为解决这一严峻的物理限制,架构设计并未试图强行违背 NAND 的物理定律,而是巧妙地通过分析工作负载特征,建立了一条从软件框架到底层硬件的延迟隐藏逻辑:
确定性模式:利用 LLM 推理具备严格的确定性数据访问模式(Deterministic pattern)与顺序执行特征:在大语言模型推理过程中,网络层级的计算是严格顺序执行的,即下一层的处理必须等待上一层完成。 预知所需数据:基于这种高度的确定性,深度学习框架层(Compiler/Framework)能够提前预知下一步(下一层)计算所需确切的粗粒度张量(Tensor)数据(例如特定网络层的静态模型权重或预计算的 KV Cache)。 张量级预取:为了在硬件层面承接这些被提前调度的数据,系统架构在 HBM 或 HBF 底层逻辑裸片(Base/Logic Die)中引入了采用双缓冲(Double buffering)结构的“延迟隐藏缓存(Latency Hiding Buffer, LHB)”进行张量级预取操作(Tensor-level prefetching)。在此机制下,当计算核心正在处理当前张量时,底层架构已经在后台向 HBF 发出并执行下一个张量的读取请求。 缓存大小物理实现推导:确切的缓存大小根据连续供数的流水线模型计算。其数学关系独立居中呈现:
工程可行性评估:在假定单栈 HBF 提供 1TB/s 带宽、且 NAND 读取延迟为 20μs 的恶劣条件下,系统评估仅需极小配置(约 40MB 容量)的 LHB,即可在双缓冲切换中维持全带宽的不间断数据供应。在先进工艺下(如 3nm),这仅占 Base Die 面积的极小部分,具有极高的经济与物理可行性。 完全覆盖物理延迟:最终,这一软硬件紧密耦合的预取机制,成功在系统宏观层级完全覆盖并隐藏了 Flash 漫长而笨重的物理读取延迟。对于上层应用和 GPU 而言,庞大的 HBF 仿佛具备了与 HBM 同等的零延迟响应能力,实现了无缝的高吞吐量数据流转。
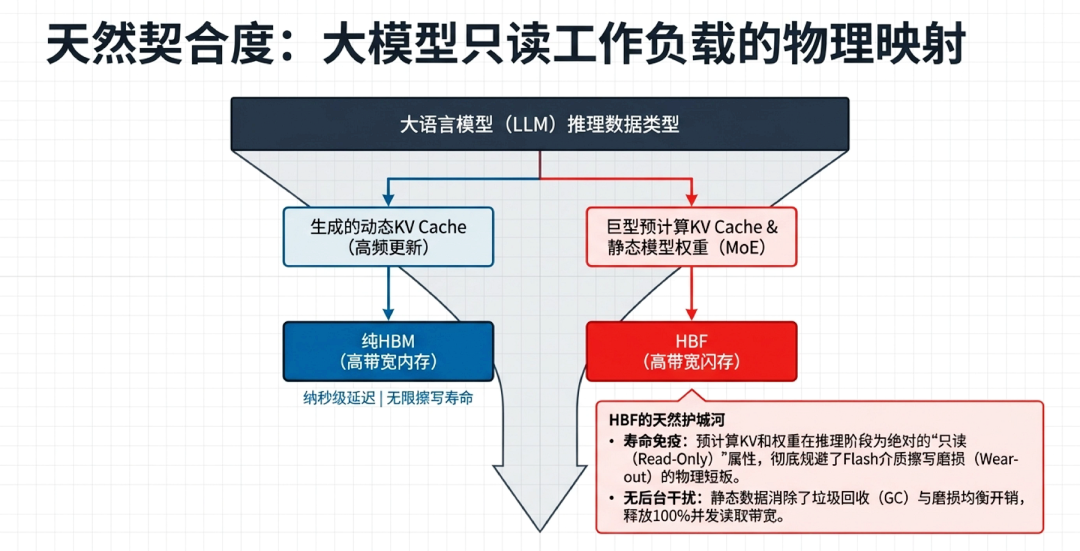
3.3 海量只读数据(Gigantic Read-Only)的完美契合度
高带宽闪存(HBF)的物理介质特性决定了其在系统架构中角色的特异性,其应用必须与特定特征的 AI 数据负载进行严格的物理与逻辑匹配。
物理寿命约束(Write Endurance):从物理本源来看,HBF 是一项基于 NAND 闪存的重构技术。与可以近乎无限次擦写的 DRAM(如高带宽内存 HBM)完全不同,NAND 闪存的物理结构在经历了有限的擦写循环(Write/erase cycles)后,不可避免地会出现介质磨损(Wear-out)。这种物理层面的介质衰减直接导致了 HBF 的写入寿命极其受限。因此,如果强制要求 HBF 承载诸如每个 Token 生成时都在动态更新的高频读写数据负载,将迅速耗尽其物理寿命,这也是其在物理定律上无法完全替代 HBM 的根本原因。 存储负载属性与架构契合:幸运的是,通过对大语言模型(LLM)推理阶段的工作负载进行深度剖析发现,其多数核心数据呈现出极端的“海量只读(Gigantic Read-Only)”特征。 具体而言,这一特征主要体现在两大类核心数据上:首先是静态模型权重(Model Weights),在推理过程中,模型参数是完全冻结的。如前文 3.1 节所述,以 Llama 3.1 405B 模型为例,在 FP8 精度下,仅存储 these 静态权重就需要一次性占用约 405GB 的物理存储空间。其次是缓存增强生成(CAG)架构中预先计算好的共享键值缓存(Pre-computed KV Cache),在处理多用户共享的长文档或庞大代码库时,这类预计算缓存的规模轻易即可达到数百 GB 甚至数 TB 级别。这两类极其庞大的数据集均表现为极低频写入(通常仅在系统初始化时预加载)、极高频读取的数据分布模式。 系统价值判定:这种应用层面的高层数据特征与底层 HBF 硬件的物理限制形成了极其精妙的完美互补。将具有只读属性的海量数据精准分配至 HBF 存储,具有深远的系统级价值: 首先,这种架构级的数据分配有效规避了 HBF 写寿命有限的物理约束,使其由于材质磨损带来的固有的劣势被彻底屏蔽。 其次,由于承载的数据保持静态,底层存储系统彻底消除了传统 NAND 闪存中常见的垃圾回收(Garbage collection)与磨损均衡(Wear-leveling)等极其消耗系统性能与并发带宽的后台开销(Overhead),确保了读出性能的绝对稳定。 最后,在无视寿命衰减与后台干扰的前提下,HBF 真正且纯粹地释放了其单栈高达 512GB 级的高密度存储核心优势。这种底层物理特性与上层数据分布属性的完美契合,使得 HBF 当之无愧地成为支撑大模型极长上下文(Long context length)与巨型混合专家参数推理的最佳且最具成本效益的存储层级选择。
04
量化性能数据与 TCO 效益
本章基于严格的工程仿真与基准测试(Benchmark)数据,对高带宽闪存(HBF)及其衍生混合架构在实际人工智能(AI)推理与检索工作负载中的系统级表现进行量化评估,论证其在降低总拥有成本(TCO)与提升能效方面的核心数据指标。
4.1 HBF 基准性能模拟分析
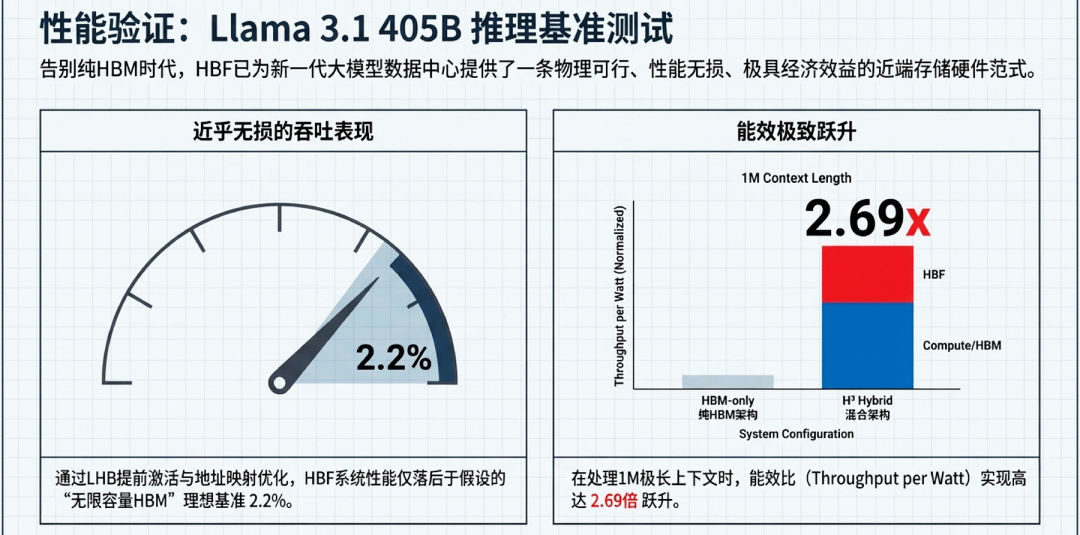
在评估高带宽闪存(HBF)作为大语言模型(LLM)推理硬件的基准性能时,核心的工程考察点在于:其能否在提供海量物理容量的同时,维持系统级的高数据吞吐要求,并有效掩盖 NAND 底层介质固有的高读取延迟缺陷。
Llama 3.1 推理模拟测试:为了验证 HBF 的实际效能,研发团队构建了针对超大参数模型的严格工程仿真环境。在针对Llama 3.1 405B 参数模型的推理模拟测试中,系统专门执行了针对 8 位(8-bit)预训练权重的流式读取操作 。该测试将搭载 HBF 的系统表现,与一个理想状态下的假设基准——“无限容量 HBM(Hypothetical Unlimited Capacity HBM)”系统进行了深度的性能比对。 量化指标:仿真测试的量化数据给出了极具突破性的结果:数据表明,在执行 LLM 解码阶段的权重读取时,引入 HBF 的系统整体性能与采用“无限容量 HBM”的理想状态相比,性能差距仅为 2.2%。这意味着在绝大多数推理场景下,HBF 能够提供几乎与 HBM 等效的吞吐量体验。 工程意义:这一极小的数据偏差(2.2%)具有决定性的工程意义。从物理层面上看,HBF 的基础读取延迟(通常在微秒级)远高于 HBM(纳秒级),且其页尺寸(4096 Bytes)也显著大于 HBM(32 Bytes)。然而,测试结果论证了:通过在 LLM 编译器中引入提前激活机制(In-advance activation),以及在系统层级进行深度的地址映射优化(Optimization in address mapping),HBF 在系统宏观层面上足以完全掩盖其底层的物理劣势。最终,HBF 不仅成功匹配了 LLM 解码阶段(Decode pass)对流式读取带宽极为严苛的要求,更为 AI 推理基础设施突破内存容量墙提供了一条行之有效且性能无损的技术路径。
4.2 H³ 混合架构的能效倍增效益
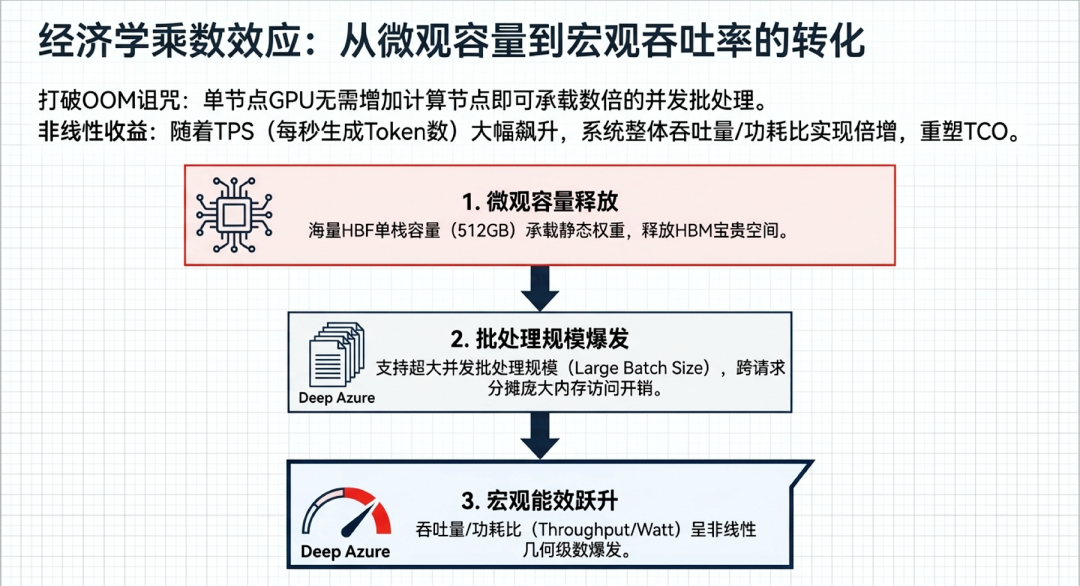
H³ 混合架构(HBM+HBF Hybrid)通过将海量只读数据(如庞大的预计算 KV Cache)移至高带宽闪存(HBF),大幅释放了高带宽内存(HBM)的宝贵容量空间,从而对系统的总体能效产生了显著的乘数效应。

大批量(Large Batch)处理能力的释放:在处理极长上下文的缓存增强生成(CAG)等应用场景中,系统需要在收到用户查询前就载入并常驻极其庞大的共享预计算键值缓存(Pre-computed KV Cache)。传统的纯 HBM 架构由于物理容量极度受限,不仅需要堆叠大量昂贵的 GPU 节点来强行容纳这些缓存,而且在处理多用户并发时极易遭遇内存溢出(OOM),严重限制了系统可支持的批处理规模(Batch size)。H³ 架构的引入彻底打破了这一桎梏。通过将庞大且属性为只读的预计算 KV Cache and 静态模型权重安全安置于单栈可达 512GB 的大容量 HBF 中,HBM 被完全释放,专门用于应对高频生成的动态缓存数据,这使得单节点 GPU 能够在不增加额外计算节点的情况下,承载显著更大的批处理规模。 从容量释放到能效非线性增长:根据相关 H³ 混合架构模拟研究表明,其能够带来系统级能效倍增的底层工程逻辑如下:
提供海量容量:H³ 架构利用 HBF 的高密度特性提供海量片上容量。这一设计释放了 HBM 的存量空间,使得系统在相同硬件规模下能够支持并处理显著更大的批处理规模(Large Batch)。 摊销访存开销:更大的批处理规模意味着在一次推理的前向传递计算中,能够在更多并发请求中充分摊销极其沉重的模型权重内存访问开销(Memory access overhead)。这种对共享 KV 注意力的极效利用,大幅提升了系统每秒生成的标记数量(Tokens per second, TPS)。 实现能效非线性增长:尽管 HBF 组件的加入会使单节点的总功耗略有上升,但由于吞吐量的提升幅度远超能耗增量,系统在总热设计功耗(TDP)增加极为有限的约束下,成功实现了系统总体能效比(吞吐量/总功耗)的非线性增长。
量化指标与经济效益:严谨的工程仿真测试数据直接量化了这一倍增效益。研究显示,在处理极长上下文时,利用 H³ 架构释放的大批量处理能力,系统整体的吞吐量可提升 1.25 倍至 6.14 倍不等 。更为关键的是,在相同 GPU 数量配置下,H³ 架构的吞吐量/功耗比(Throughput per Watt)最高可获得 2.69 倍的惊人提升。这一确凿的量化数据直接证明了,H³ 混合架构在构建低总拥有成本(TCO)、高能效的大规模长序列大语言模型推理基础设施方面,具备极其显著的经济与物理双重效益。
4.3 HAVEN 架构的大规模检索加速指标
在检索增强生成(RAG)系统中,近似最近邻搜索(ANNS)的倒排索引与乘积量化(IVF-PQ)算法是平衡检索效率与内存占用的关键。然而,为了实现高准确度的召回率(High Recall),系统必须执行全精度向量的重排(Reranking)操作,这成为了引发系统性能瓶颈的绝对核心环节。HAVEN(High-Bandwidth Flash Augmented Vector ENgine)架构通过创新的近存储处理(NSP)机制,彻底重构了这一数据流转路径。
数据移动瓶颈的消除:在传统的计算架构中,由于 GPU 封装内的高带宽内存(HBM)容量极其有限,根本无法容纳动辄数百 GB 甚至 TB 级别的十亿级全精度原始向量库。因此,系统被强制要求将这些重排所需的原始全精度向量存储于主机侧的 DRAM 或 NVMe SSD 中。这就导致在重排阶段,海量数据必须经由缓慢的 PCIe 总线频繁且大量地跨组件传输至 GPU。这种严重的“跨设备数据移动(Off-GPU data movement)”引入了极高的物理访问延迟,并导致系统吞吐量(QPS)在开启重排时出现断崖式衰减,使得系统在追求高召回率时面临极其严苛的性能妥协。 从延迟受限到吞吐量驱动:同样,基于 HAVEN 相关架构模拟评估,其核心加速逻辑如下:
海量数据全片上驻留:HAVEN 架构将海量全精度向量直接存储于 GPU 封装内的高带宽闪存(HBF)中,利用其 TB 级的海量容量实现了核心检索数据的“全片上驻留”。 就地进行本地计算:结合硬连线在 HBF 底层的近存储搜索单元(Near-Storage Search Unit)进行本地计算,使距离计算与 Top-k 排序直接在数据源头就地完成。 高密度数据“零移动”:这一机制实现了高密度原始数据的“零移动”,彻底消除了传统架构中 PCIe 总线与外部 DDR/SSD 之间极其低效的外部传输物理瓶颈。 突破带宽与延迟限制:最终,将原本受制于外部内存容量与跨设备传输延迟的重排操作,完美转化为基于 HBF 内部海量分布式子阵列高并发带宽的高吞吐量操作。
量化指标与断层式性能提升:针对极具代表性的十亿级规模数据集(如 BIGANN-1B、SPACEV-1B)以及针对大语言模型特征的高维检索数据集(Wiki-88M)的向量检索工作负载测试中,结果呈现出压倒性的优势。基准对比数据表明,HAVEN 架构相比传统的 GPU-DRAM 或 GPU-SSD 方案,最高可将重排吞吐量(Throughput)提升达 20 倍,同时系统查询延迟(Latency)最高可大幅降低达 40 倍。尤其在处理如 Wiki-88M 这样的高维数据时,由于所需重排的数据流量急剧放大,传统架构的衰减更为严重,而 HAVEN 将数据留在片内处理的性能代差优势则愈发显著。这一断层式的性能提升确凿地验证了,HBF 增强型 GPU 架构在处理极端规模、高召回率要求的检索任务时,具备彻底打破内存墙的数据处理绝对优势。
05
产业链协同、标准化与设备材料生态
本章聚焦高带宽闪存(HBF)从底层材料、制造设备到宏观产业标准的完整生态链,论证其从实验室技术向大规模商业化演进的系统性工程布局。
5.1 标准化进程与商业化时间表
高带宽闪存(HBF)作为一种介于高带宽内存(HBM)与固态硬盘(SSD)之间的全新存储层级,其物理架构的颠覆性与系统集成的复杂性决定了,它的成功商业化不能仅靠单一厂商的闭门造车,而高度依赖于全产业链的规范统一与广阔的生态协同。
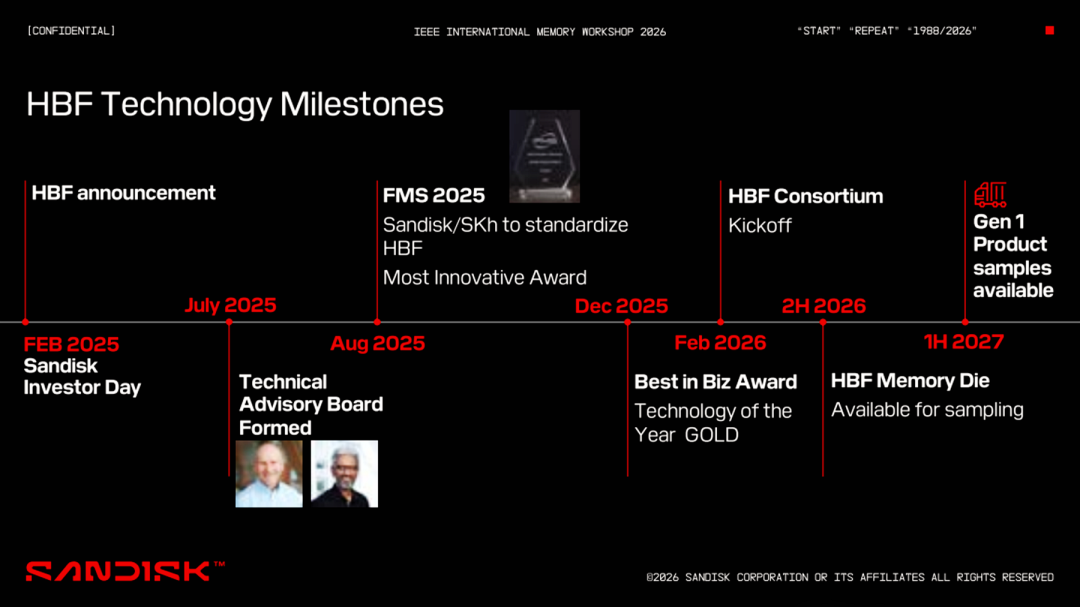
开放计算项目等开放框架下的标准化战略意义:为了打破硬件研发中常见的封闭生态局限并加速技术普及,闪迪(SanDisk)与 SK 海力士(SK Hynix)携手,全面启动了 HBF 标准化的技术推进。这一产业整合动作具有深远的核心战略意义:它标志着 AI 基础设施的竞争,已从单一硬件组件的物理性能指标比拼,全面升维至系统级生态的全局优化层面。通过在开放计算项目(OCP)等开放框架下积极探索异构融合标准的统一,确立统一的物理接口、通信协议与底层封装规范,标准化进程能够有效确保未来不同供应商的 HBF 模块与各类计算核心(GPU/xPU)及异构系统架构之间的无缝兼容。这不仅大幅消除了下游硬件开发者的试错冗余,更从宏观架构上显著降低了 AI 数据中心构建与大规模运营的总体拥有成本(TCO)。 明确的商业化时间节点:在坚实的标准化生态支撑与旺盛的 AI 推理需求驱动下,HBF 的商业化正按照极其严格且加速的工程节点稳步推进。根据最新披露的技术路线图: 2026 年下半年(2H 2026):产业界将正式推出第一代(Gen 1)HBF 产品的物理样品。这标志着基于 CBA 架构与 16 层堆叠的底层热压键合工艺已具备初步的制造可行性。 至 2027 年上半年(1H 2027):用于测试验证的 HBF 核心裸片(Memory Die)将向全球合作伙伴全面开放采样(Available for sampling)。更为关键的是,届时业界将推出与先进 AI 加速器芯片深度集成的初步商用系统。这一决定性的工程里程碑,标志着 HBF 将正式跨越早期的实验室概念与原型验证,迈入全面商业化部署的实质性阶段,开始在全球 AI 基础设施中发挥其突破“内存容量墙”的颠覆性作用。
5.2 后道封装(OSAT)的核心设备需求
高带宽闪存(HBF)的微观物理集成对后道封装测试(OSAT)工艺提出了前所未有的工程挑战,不仅改变了存储芯片的制造流程,更直接重塑了相关核心封装设备的市场需求。
核心设备演进的逻辑分析:HBF 架构在物理层面要求实现高达16 层的 3D NAND 核心裸片(Core Die)垂直堆叠,并在极其有限的芯片 面积内,穿透密集的硅通孔(TSV,单阵列规模约达 8000 个)以建立跨层级的电气互连。这种极高密度的垂直三维互连特征,使得主要依赖边缘物理引脚连接的传统引线键合(Wire Bonding)工艺完全失效。因此,能够将各个内存裸片精确对齐,并同时施加精确温度与机械压力的热压键合机(TC Bonder, Thermo-Compression Bonder),成为了实现层间微凸块(Microbump)可靠连接不可或缺的核心制造设备。 设备商技术占位与工程挑战:针对 HBF 带来的全新封装需求,全球主流的后工序设备供应商正加速进行技术占位与供应链渗透。由于 HBF 与 HBM 在封装的底层物理逻辑上具有高度相似性,包括韩美半导体(Hanmi Semiconductor)、韩华精密机械(Hanwha Semitech),以及国际设备巨头 ASMPT 和库力索法(K&S)等企业,均已全面介入 HBF 专用的 TC Bonder 研发与测试。其中,作为 HBM 热压键合设备龙头的韩美半导体进展最为迅速,预计将在 2026 年下半年向全球主流 NAND 制造商交付首批 HBF 专用的初期量产 TC Bonder 设备。 热预算(Thermal Budget)的物理挑战:尽管 HBF 在宏观架构上借鉴了 HBM,但在实际的热压键合工艺中,设备却面临着更为严苛的物理与材料学限制。根本挑战在于:与 DRAM 介质相比,NAND 闪存介质的物理结构对高温与机械压力的耐受度显著更低(即制造过程中的热预算极度受限)。在将高达 16 层极薄且脆弱的 NAND 晶圆进行热压贴合时,如果设备施加的机械压力或温度场分布出现微小的不均,极易在 NAND 介质内部应力集中的区域引发不可逆的物理破裂(Cracks)。因此,如何在极低的热预算约束下,实现微米级的精准热压控制与翘曲管理,防止键合过程中的芯片损伤,是保障 16 层 HBF 封装良率的核心工程挑战,也是决定其能否顺利从实验室走向大规模商业化的关键壁垒。
5.3 关键基础材料生态的支撑
实现高带宽闪存(HBF)的超高密度三维异构集成,不仅依赖于尖端的热压键合设备,更需要基础化学材料在微观物理层面的绝对支撑 。这种从宏观封装向微观材料延伸的产业协同,是突破存储制造物理极限的关键。
克服晶圆翘曲的工艺协同:HBF 的制造工艺极其复杂,其底层物理架构涉及两步极具挑战性的异构集成:首先,必须将底层的 CMOS 逻辑控制层与上层多达数百层的 3D NAND 阵列进行直接键合,形成 CBA(CMOS Bonded Array)存储瓦片;其次,为了达到单栈 512GB 的海量容量,系统还需要将 16 层极其纤薄的这种核心裸片(Core Die)进行高密度的晶圆级垂直堆叠。为了承接 1.1 节所述的超低 Die 翘曲控制并保障垂直堆叠稳定性,在实际工艺中,化学机械平坦化技术与材料学发挥着决定性的作用。 CMP 工艺与化学材料的不可或缺性:为了实现 16 层堆叠前各层介质表面几乎原子级的绝对平整度,单纯的机械抛光已完全失效,必须高度依赖先进的化学反应进行微观层面的材料去除。这就使得以Soulbrain为代表的先进化学材料企业成为了 HBF 生态中不可或缺的一环。在 HBF 的制造过程中,必须依赖 these 企业供应的高纯度 CMP 浆料(CMP Slurry,主要用于密集的配线平坦化)以及高选择比的特种蚀刻液(Etchant)。这些尖端化学材料能够在不损伤脆弱 3D NAND 结构的前提下,精准去除表面多余材质并消除内部的微观物理缺陷。从系统工程的角度来看,这些特种化学材料是确保整个 HBF 极其复杂的三维结构能够顺利跨越良率鸿沟、实现大规模稳定量产的不可或缺性要素。
06
结论
高带宽闪存(HBF)并非传统意义上单纯追求物理存储密度扩展的非易失性介质,而是一项经过深度物理与逻辑重构的创新存储架构。通过在物理微观层面引入分布式子阵列(Distributed Subarrays)以提升内部并行度,结合 CBA(CMOS Bonded Array)技术将逻辑层与存储阵列直接键合,并采用硅通孔(TSV)与微凸块(Microbump)构建极其密集的三维混合封装架构, HBF 成功实现了系统级的高并发读取带宽与海量存储容量。此外,借助在底层逻辑晶圆直接集成近存储搜索单元(NSP)的设计,HBF 将部分低算力、高访存的数据处理操作(如全精度向量重排)固化在存储近端本地执行。这一架构创新专门针对大语言模型(LLM)推理与检索增强生成(RAG)工作负载,彻底消除了受制于外部内存容量与跨组件总线(如 PCIe)传输的物理瓶颈,进行了深度的系统级优化。
在宏观商业与系统运行效益层面,HBF 展现了极具说服力的量化指标优势。它的引入不仅大幅降低了 AI 数据中心基础设施的总拥有成本(TCO),更在 H³(HBM+HBF)混合架构配置下,通过释放大批量处理能力,使系统的吞吐量/功耗比(Throughput per Watt)获得了最高达 2.69 倍的显著提升。同时,通过深度结合 LLM 推理系统具备的严格确定性数据访问模式(Deterministic pattern),并在底层硬件逻辑中引入延迟隐藏缓存(LHB)进行精准的张量级调度预取(Tensor-level prefetching),系统成功在宏观应用层掩盖了 NAND 介质固有的微秒级物理读取延迟缺陷。
尽管该技术在架构和能效上展现了显著的潜能,但在迈向大规模商业化的过程中,依然面临着 16 层异构键合的工艺良率跨越、全产业链生态软件栈的兼容以及原厂初期产能爬坡等现实挑战。随着开放计算项目(OCP)等标准化进程的稳步推进,以及 2026 年下半年推出首批样品、2027 年上半年全面商业化的明确时间表,HBF 的大规模部署必将重塑由底层存储制造原厂(如 SanDisk、SK 海力士)、先进后道封装测试(OSAT)设备供应商(如韩美半导体、ASMPT)以及系统级 AI 硬件架构商共同构成的全球半导体产业链生态格局。
✦
✦
2026中国AI智能体大会
✦
智猩猩主办的2026中国AI智能体大会7月2-3日杭州举行,大会设有开幕式,企业级AI智能体、AI智能体产品创新2场论坛,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness7场技术研讨会。最终议程已公布。











点击下方名片 即刻关注我们










