雷科技AI组 | 编辑:重嘉 | 监制:罗超
北京时间6月27日凌晨,OpenAI正式发布了备受瞩目的GPT-5.6系列模型。然而,这次发布和过去最大的不同是,GPT-5.6并没有面向公众或普通企业全面开放,而是采取了非常苛刻的受限预览模式。
说得更具体点,这次的发布节奏与准入名单受到了美国监管机构的直接干预,只有极少数经过严格审核的特定企业和机构才能获得访问权限。
这一幕不久之前刚刚发生过,对于Anthropic公司发布的顶尖模型,美国当局以存在潜在的安全漏洞和出口管制风险为由,迅速高阶限制了其高阶版本,不向常规商业用户开放。
当全球最顶尖的AI生产力工具被外部力量介入和限制时,大家其实都意识到了,AI技术自由竞争的时代已经结束了。对企业来说,单纯依赖海外的通用大模型的技术来完成数字化、AI化的方案,正在变得越来越不可控。

监管介入重塑AI生态,
安全合规成企业生死线
GPT-5.6以及Fable 5、Mythos 5模型的受限发布,说明当下前沿AI技术在发展过程中被戴上了一条紧箍咒:模型的能力越强,越接近通用人工智能(AGI),它作为公共商业基础设施的开放度反而越低。
从官方公布的信息来看,GPT-5.6的突出优势集中在代码自主编写、高级网络安全攻防和前沿科学实验领域。而正是在这些方面的强大能力,让美国监管机构心存忌惮。
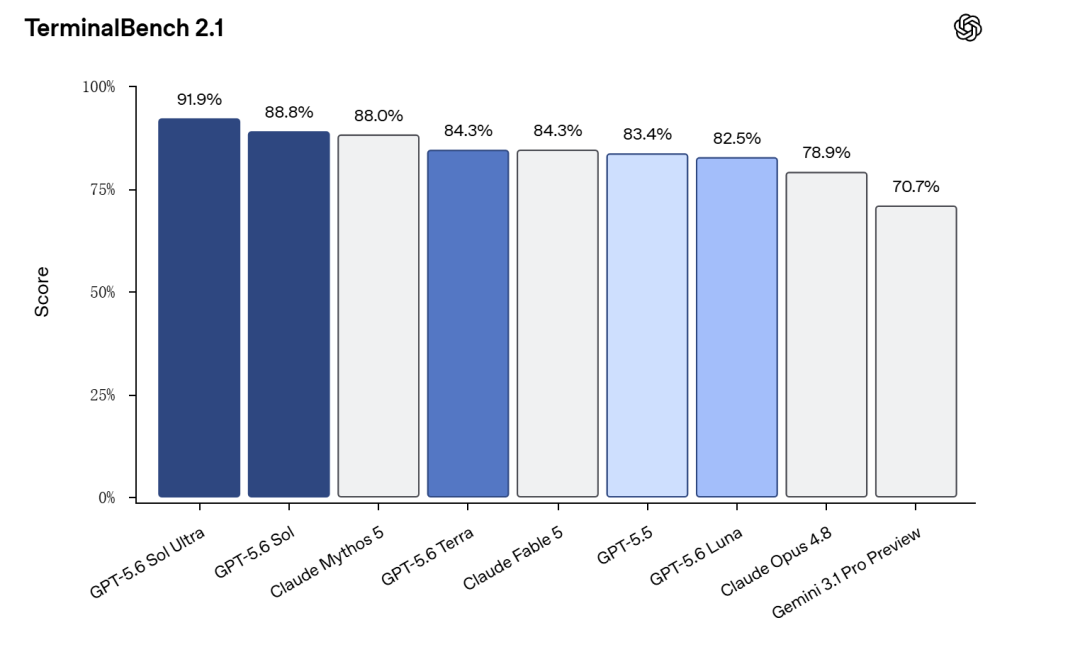
(图源:OpenAI)
目前而言,外部监管力量对大模型的干预已经从事后追责转变为事前准入。更早时候,全球各国的监管机构,对AI的监管重点主要是数据隐私泄露、虚假信息泛滥等应用层面的治理。向来隐私保护法律严格的欧盟,此前对AI企业开出的罚单,基本是出于用户隐私保护的考量。比如,2023年,意大利因信息泄露问题暂时封禁了ChatGPT;2024年,爱尔兰和欧盟施压,让Meta放弃了使用欧洲用户数据来训练AI。
而中国监管部门,2023年出台了《生成式人工智能服务管理暂行办法》,对AI的监管重点主要是知识产权和个人信息保护。另外,面向公众开放的生成式AI服务,需要完成算法备案。
但总的来看,美国当局主导的逐个客户审批机制,显然是最激进的监管手段,相关行政命令很有随意性。这种制度约束下,海外头部AI厂商实质上已经失去了完全的自主销售权。Anthropic此前对核心模型的熔断隔离,以及如今GPT-5.6的定向供给,都是这一监管模式带来的结果。

(图源:Anthropic)
对于全球范围内需要购买AI服务的企业而言,这种外部介入称得上是一场灾难。在过去几年里,大量企业为了不在AI浪潮里掉队,将自身的客服、风控系统,以及内部资料库等,都深度绑定在海外大模型的云端AI API接口上。这种模式简单高效,企业只需要向AI巨头买技术买方案就行,但如今一旦面临着不可控的监管机制,就变得很脆弱了。
企业在使用AI时,安全合规已经成为不得不考虑的关键因素。我们现在说的这种合规,不再是传统意义上的法律合规,还包含了数据主权安全。想象一下,一家跨国企业,如果日常运营的自动化项目高度依赖一个随时可能因一纸禁令而停摆的海外AI,那么面临的风险是高度不可控的。
以往,大家判断一款大模型的商业价值,可能会把基准测试、跑分作为关键指标;但以后,企业用户会更加关注模型的合规和稳定性,比如说,一个技术能力只有GPT-5.4水平、但能够保证合规且不断供的本土化模型,所带来的商业价值,可能会超过能力顶尖但随时可能被断供的GPT-5.6。

海外顶尖模型让出市场,
国产AI迎来红利期
从以往的历史经验来看,原本稳定的市场生态由于外部政治干预出现断层,都会一定程度上释放出市场真空,给受限企业带来危机的同时,也给了它们前所未有的发展机遇。华为就是这样一个非常典型的案例,前些年美国当局对它进行全面限制,在芯片、系统、市场等各个方面实行断供。虽然说华为刚开始面临着巨大困难,但后续成功实现了国产替代,自研芯片、鸿蒙系统都全面崛起,成为华为产品和生态的核心优势。
OpenAI、Anthropic这些海外巨头的顶尖大模型监管受限,给正处于商业化关键节点的国产大模型,让出了一片B端市场。当全球最顶尖的AI被锁进一小块市场时,海量的中小企业、工业巨头、金融机构以及正在谋求全球化布局的出海企业,它们对AI的需求并没有消失,这便成了国产大模型破局的机遇。
6月17日,智谱宣布上线并开源GLM-5.2,这款大模型综合能力和Claude Fable 5、Claude Mythos 5相比还是存在一定差距,但在长程任务等场景中仍然有很强的表现。而就在智谱发布新款模型前不久,Anthropic在监管要求下被迫关闭了这两款旗舰模型的访问权限。
作为对比,GLM-5.2则是开源、开放、不限量,股价扶摇直上,市值一路飙涨,突破了9000亿港元。而且,智谱AI的API定价今年已经多次上调,价格和海外顶尖模型相差不大,但仍然供不应求。
雷科技(ID:leitech)认为,智谱在全球范围内吃香,主要有两个原因:首先,智谱大模型能力虽然不及海外顶尖模型,但仍然达到了行业前列,同时Agent和应用落地能力很强,智谱向B端企业提供了大量可直接使用的解决方案,满足其降本增效的需求;其次,智谱的不确定性风险更低,不会像Anthropic那样出现断供风险,这种情况下,企业用户更愿意选择智谱。

(图源:智谱)
除了智谱,国产大模型市场上,还有阿里千问、字节豆包、MiniMax、DeepSeek等一众顶级企业。它们的模型产品在不断进化,商业化模式也更加多样化。比如,千问持续推动开源大模型的升级,同时阿里云完成了全链路的接口AI化,能直接向客户供应全套的AI方案。豆包的付费专业版大幅提升了生产力属性,能更快、更稳地完成复杂任务;Seedance 2.0在视频生成领域几乎是全球独一档,已经深入影视创作产业。
大洋彼岸对自家顶尖模型的严格限制,必然会导致大量海外企业来国内寻找方案,而垂直赛道丰富、商业方案多样化的中国AI产业,能满足它们的各种需求。同时,国产AI,正迎来宝贵的红利期。

企业自建AI护城河,
开源+本地部署成破局手段?
AI浪潮袭来时,千行百业都在被改变。而无论是个人,还是企业,都普遍存在着AI焦虑,没有人想要在这股浪潮中被落下。很多企业的应对方式是直接购买AI巨头们的技术方案,依托它们来完成对旗下业务、组织架构乃至生产流程的AI赋能。但现在,大家都发现,AI也能被断供,用第三方的云端AI接口,本质上是在别人的地盘上建房子。如果要真正化解风险,企业得将AI能力转化成安全的私有资产。
不过,要求所有企业从零到1地自研AI、创建自己的大模型,当然不现实,也不经济。但是,开源大模型生态的爆发式增长,为企业提供了基础的方案。在Hugging Face等各大开源社区中,从百亿到千亿甚至万亿级参数的优秀开源模型层出不穷。它们在基础推理能力上,已经足够优秀,完全可以作为企业的数字底座,如果再导入自家的行业私域数据,就能定制出自己的专属模型。
另外,本地化部署的门槛其实没有那么高。哪怕是个人用户,用一台几年前发布的、16GB内存的普通MacBook,也能跑得动量化版的开源大模型,并且部署龙虾之类的工具,完成一些不是特别复杂的AI任务。对于预算更充裕的企业,利用几台高性能本地服务器、私有云集群,基本就能撑起企业内部的AI业务。即便前期可能会增加硬件投入成本,但长期来说能降低Token等方面的支出,还能降低不确定性风险。
此外,无论是企业还是个人,对AI的关注重点都逐渐从大模型转向Agent。说白了,相比大模型的参数和跑分,我们更关注AI能解决哪些现实问题。对大部分企业而言,它们其实并不需要OpenAI、Anthropic的最新款顶级模型,更需要能干活的Agent和Skills。
比如在一家企业的AI架构中,在多Agent协同的模式下,发票解析的Agent、合规审计的Agent、编写代码的Agent能相互配合,它们只需要本地小模型提供算力支撑,就已经能解决大部分问题了。
这次GPT-5.6发布时,OpenAI把它分成了Sol、Terra、Luna三个档位,能力有所区分。尽管OpenAI接受了提前审查,但这三个版本都被美国当局限制了,哪怕是主打低成本的Luna版。
目前,GPT-5.6只对少部分客户开放了,后续范围会扩大。然而,目前开放客户的名单是保密状态,后续开放也没有明确时间表,一次新款大模型的发布硬生生变成了掺杂着太多外部因素的黑箱操作。
它用一种非常残酷的方式,打碎了很多企业试图低成本、零风险、无国界接入AI的乌托邦式的幻想。不过,它客观上逼迫着中国乃至全球的企业进行改变,从盲目追求海外最新顶尖大模型,到主动扎根本土生态,这是一条更加可靠的技术自主道路。
.6