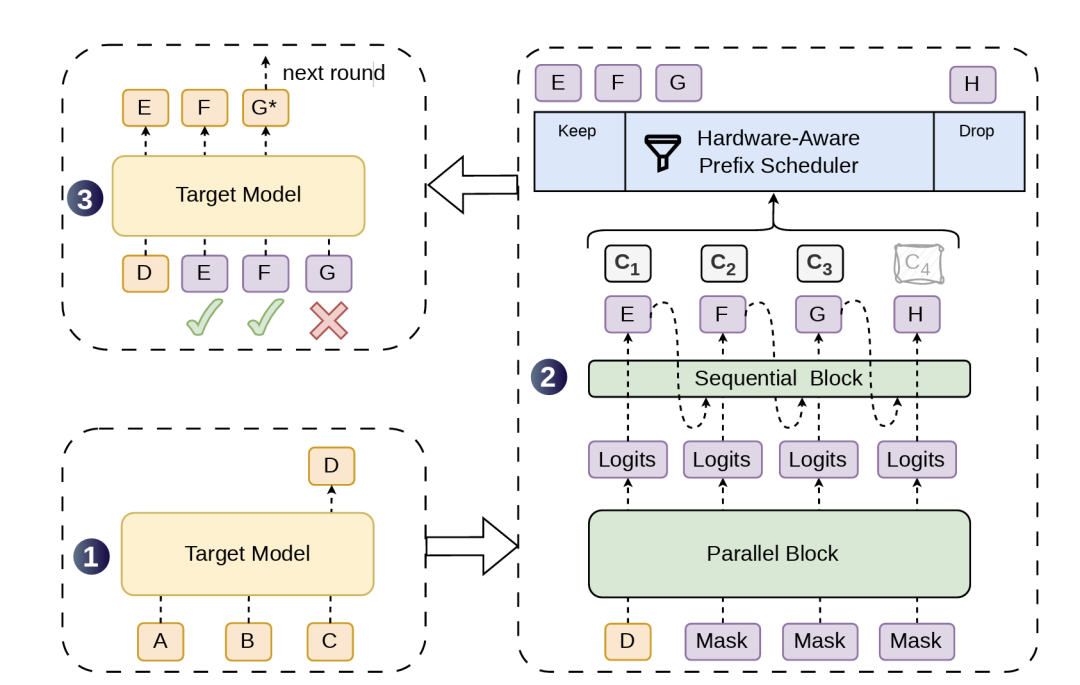
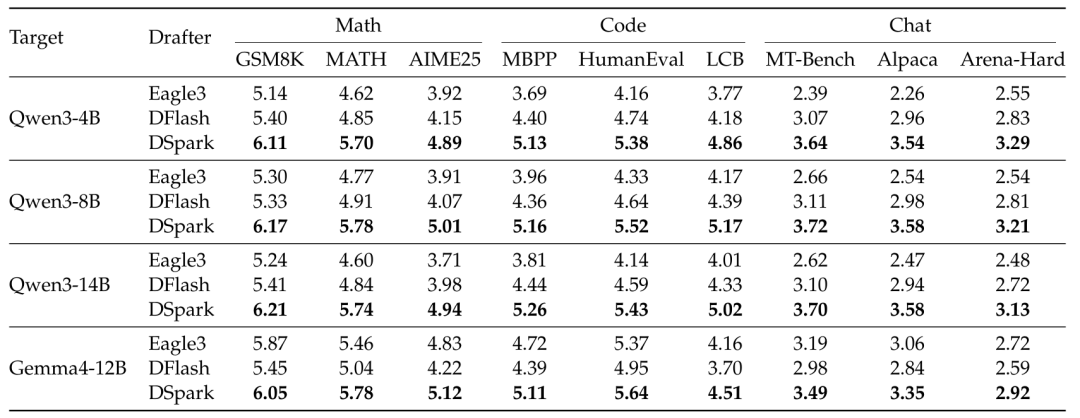
最近忙着大规模招兵买马的 DeepSeek,也始终没有忘记开源这条主线。今天,DeepSeek 与北京大学团队联合发布论文《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》,提出了一套新的大模型推理加速框架 DSpark。技术报告 🔗 https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf论文披露,DSpark 已经进入 DeepSeek-V4-Flash preview 和 DeepSeek-V4-Pro preview 的生产服务系统,并替代此前的 MTP-1 方案。在线上真实用户流量中,在系统总吞吐水平相同的情况下,DSpark 将 DeepSeek-V4-Flash 的单用户生成速度提升了 60% 至 85%,将 DeepSeek-V4-Pro 的单用户生成速度提升了 57% 至 78%。速度飙成这样,DeepSeek 究竟给自家的推理引擎喂了什么灵丹妙药?当然,本文难免有些枯燥,感兴趣的朋友不妨耐心阅读。天下苦 AI 「蹦字」久矣为什么每次等到大模型的回复总感觉在「挤牙膏」?原因并不复杂。主流语言模型生成文本时,基本采用 autoregressive(自回归)方式。模型每生成一个新 token,都需要做一次以前文为条件的前向计算,因此输出越长,解码步骤越多,延迟也越容易累积。对于实时聊天、多轮 Agent workflow(智能体工作流)、代码助手这类高交互场景,生成速度会直接影响用户体验,也会影响 GPU 利用率。speculative decoding(推测解码)就是为了解决这个问题。为方便阅读,图片由 AI 生成,仅供参考它的思路像是让一个「小模型」先写草稿,再让「大模型」快速审稿。系统先用一个轻量级 draft model(草稿模型)生成一串候选 token,再由真正负责输出质量的 target model(目标模型)一次性验证这些候选 token。通过验证的 token 会被接受;一旦某个位置被拒绝,后面的候选 token 全部作废,target model 再生成一个修正 token。由于 verification(验证)阶段可以并行完成,speculative decoding 可以在不改变 target model 输出分布的前提下提高生成速度。更直观地说,它想让大模型一次前向计算确认更多 token,而不是每次只确认一个。speculative decoding 已经是大模型推理加速的重要方向,但已有方案仍有明显限制。第一类方案是 autoregressive draft model(自回归草稿模型)。它像正常语言模型一样,一个 token 接一个 token 地生成候选内容。优点是前后关系更自然,候选质量较高;缺点也明显:draft model 自己写草稿时也要一步一步来,候选 token 越多,draft 阶段越慢。第二类方案是 parallel draft model(并行草稿模型)。它可以一次性生成多个候选 token,速度很快,也更适合生成较长的 candidate block(候选块)。问题在于,candidate block 内部的 token 之间缺少足够的依赖关系。为方便阅读,图片由 AI 生成,仅供参考论文里举了一个很直观的例子。模型面对某个上下文时,可能同时存在 「of course」 和 「no problem」 两种合理续写。parallel draft model 因为没有真正按顺序生成,很容易把两条续写路径混在一起,生成 「of problem」 或 「no course」 这种前后不一致的组合。结果就是,parallel draft model 开头几个 token 往往还不错,但越往后,候选 token 被 target model 接受的概率下降越快。论文把这种现象称为 suffix decay(后缀衰减)。更现实的问题发生在线上服务里。parallel draft model 很容易一次生成一长串候选 token,但在真实高并发服务中,把这些 token 全部送给 target model 验证,未必划算。数学、代码这类结构化任务,答案路径相对明确,候选 token 更容易被接受。开放式聊天不确定性更高,后面的 token 更容易被拒绝。系统空闲时,多验证几个 token 影响不大;系统繁忙时,验证那些大概率会被拒绝的 token,会占用 batch capacity(批处理容量),影响其他用户请求。换句话说,推测解码的问题已经不只在于能不能一次生成更多 token,还在于哪些 token 值得交给 target model 验证。DSpark 是怎么「既要又要」的DSpark 的思路可以概括为两件事:草稿要写得更像样,审稿要更会挑重点。在生成侧,DSpark 采用 semi-autoregressive architecture(半自回归架构)。它保留 parallel draft model 的主干,让大部分计算仍然一次完成;同时在输出端加入一个轻量级顺序模块,让后面的 token 能参考前面已经采样出来的 token。可以把它理解成:前面用并行方式快速铺开候选,后面再用一个很轻的顺序模块检查相邻 token 的衔接关系。论文默认使用 Markov head,也测试了 RNN head。Markov head 主要建模相邻 token 之间的转移关系,计算成本低,部署更方便;RNN head 能保留更长的块内历史,但收益有限,复杂度更高。因此,论文把 Markov head 作为默认方案。这种架构的目标很明确:保留 parallel draft model 的速度,同时补上部分 autoregressive draft model 的前后连贯性。在验证侧,DSpark 引入 confidence-scheduled verification(基于置信度调度的验证)。系统会给每个候选位置预测一个 confidence score(置信度分数)。这个分数表示:在前面的 token 都已经被 target model 接受的情况下,当前位置继续被接受的概率有多高。随后,hardware-aware prefix scheduler(硬件感知前缀调度器)会根据三个因素动态决定每个请求该验证多少 token:当前系统负载、每个候选位置的置信度、引擎在不同 batch size(批大小)下的 throughput curve(吞吐曲线)。因此,DSpark 不会机械地验证固定长度的 candidate block。系统资源宽松时,它可以验证更长的 prefix(前缀),让一次 target model 前向计算尽量产出更多有效 token。系统负载升高时,它会缩短低置信度请求的验证长度,减少对 target model batch capacity 的占用。这也是 DSpark 相比传统推测解码更接近真实生产环境的地方:它不只追求单次生成更多候选 token,也会根据系统负载调整验证预算。大模型的尽头,是复杂的系统工程问题离线实验部分,论文在 Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Gemma4-12B 四个 target model 上测试 DSpark,并与两类代表方案对比:autoregressive draft model Eagle3,以及 parallel draft model DFlash。评测覆盖数学推理、代码生成和日常聊天三个场景,包含 GSM8K、MATH500、AIME25、MBPP、HumanEval、Live-CodeBench、MT-Bench、Alpaca 和 Arena-Hard 等 benchmark(基准测试)。结果显示,在 Qwen3-4B、Qwen3-8B 和 Qwen3-14B 上,DSpark 相比 Eagle3 的 macro-average accepted length(宏平均接受长度)分别提升 30.9%、26.7% 和 30.0%;相比 DFlash 分别提升 16.3%、18.4% 和 18.3%。在 Gemma4-12B 上,DSpark 也保持领先。accepted length 可以理解为每一轮 speculative decoding 中,平均有多少 token 能被 target model 接受。这个数字越高,说明 draft model 写出的草稿越能被大模型认可,推理加速空间也越大。论文还观察到,不同任务之间差异很大。以 Qwen3-4B 为例,DSpark 在数学任务上的平均 accepted length 为 5.57,在代码任务上为 5.12,在聊天任务上为 3.49。数学和代码更结构化,续写路径更稳定;聊天更开放,模型可能有很多种合理回答方式。因此,同样长度的候选 token,在不同任务里的价值并不一样。固定 verification length(验证长度)会浪费一部分计算资源。更详细的实验解释了 DSpark 为什么行之有效。DFlash 这类 parallel draft model 在第一个候选 token 上表现很强,因为它可以用更深的网络一次性生成候选。但从第二个 token 往后,它缺少块内依赖,接受率下降更明显。Eagle3 这类 autoregressive draft model 在后段一致性上更好,因为它确实按顺序生成。但为了控制 draft 阶段延迟,它通常不能做得太深,因此第一个 token 的预测能力受限。DSpark 介于两者之间。第一个 token 继承 parallel draft model 的强预测能力,后面的 token 通过 sequential module 减少 suffix decay。结构实验也支持这个判断。论文显示,2 层 DSpark 已经超过 5 层 DFlash,说明轻量级顺序建模比单纯增加并行层数更有效。随着 proposal length(候选长度)从 4 增加到 16,DSpark 相对 DFlash 的优势继续扩大。在最长设置下,DSpark 在数学、代码和聊天任务上分别领先 DFlash 30%、26% 和 22%。延迟方面,sequential module 带来的额外开销很小。在 batch size 128 的测试中,相比 DFlash,DSpark 的单轮延迟只增加 0.2% 至 1.3%,但 accepted length 最多提升 30%。置信度模块也经过了单独验证。论文在 Qwen3-4B 上做了 confidence threshold sweep(置信度阈值扫描),也就是不断提高置信度门槛,观察系统会保留哪些 token。结果不言而喻:门槛越高,系统过滤掉的低价值候选 token 越多,整体 acceptance rate(接受率)越高。聊天任务变化最明显,acceptance rate 从 45.7% 提升到 95.7%;数学任务从 76.9% 提升到 92.5%;代码任务从 67.6% 提升到 92.0%。线上部署部分更关键。DeepSeek 在 DeepSeek-V4-Flash preview 和 DeepSeek-V4-Pro preview 的 production engine(生产引擎)中部署 DSpark,最大 draft 长度设为 5,对比对象是此前的 MTP-1 生产基线。MTP-1 只做单 token 预测,加速空间有限,但在高并发下比较安全。原因在于,静态 multi-token draft(多 token 草稿)虽然看起来一次生成更多 token,但如果很多 token 最后被拒绝,反而会浪费 target model 的验证资源,拖累系统总吞吐。DSpark 的意义在于,它让 multi-token draft 在真实线上流量中变得可控。面对中等并发时,DSpark 会把验证预算从 MTP-1 的静态 2 个 token 扩展到大约 4 到 6 个 token,让每次前向计算产生更多有效输出。当并发继续升高、target model 接近饱和时,DSpark 会自动缩短验证长度,减少低置信度 token 对 batch capacity 的占用。在线上测试中,V4-Flash 在 80 token/s/user(每用户每秒 token 数)的服务目标下,DSpark 相比 MTP-1 将系统总吞吐提升 51%。在更严格的 120 token/s/user 目标下,MTP-1 已经接近可承载边界,DSpark 给出的名义吞吐优势达到 661%。这个 661% 不应理解成所有常规场景都能获得 6 倍以上提升。更准确的理解是:在高交互、强 SLA 约束下,MTP-1 已经很难继续维持服务能力,而 DSpark 把原本难以达到的性能区间打开了。V4-Pro 的趋势类似。在 35 token/s/user 的目标下,DSpark 总吞吐提升 52%;在 50 token/s/user 的严格目标下,名义吞吐优势达到 406%。在相同系统容量下,DSpark 让 V4-Pro 的单用户生成速度提升 57% 至 78%。故事的最后,自然是熟悉的配方、熟悉的味道。DeepSeek 还宣布开放 DSpark 的模型权重,包括 DeepSeek-V4-Flash preview 和 DeepSeek-V4-Pro preview 对应的 DSpark checkpoints(模型检查点)。同时,DeepSeek 开源了 DeepSpec,一个面向 speculative decoding 训练的代码库,包含 Eagle3、DFlash 和 DSpark。🔗 https://github.com/deepseek-ai/DeepSpec简言之,大模型推理加速已经不只是模型结构问题,也越来越是系统调度问题。单纯让 draft model 一次生成更多 token,并不等于服务一定更快。候选 Token 的质量、通过率、验证长度、系统负载、吞吐目标……每一个变量都在极其微妙地互相牵扯。大模型竞争正在进入更精细的阶段。训练出更强的模型,仍然是牌桌上的硬实力;但能否把模型以更快、更便宜、更稳定的方式送到真实用户面前,同样会决定一款 AI 产品的上限。DeepSeek 选择把这套生产环境里的加速经验开源,相当于把一部分真正能提高推理效率、降低服务成本的核心方法,无私分享给全行业。只能说,做人不要太 OpenAI,多学学 DeepSeek。我们正在招募伙伴📮 简历投递邮箱hr@ifanr.com✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)