点击下方卡片,关注“具身智能之心”公众号
在真实物理世界中,机器人经常会遇到“非马尔可夫(Non-Markovian)”场景:刚刚打开盖子看到一个红色的方块,盖上盖子后,机器人还需要记得“里面是红色的”才能完成后续任务。
面对这种长序列、强遮挡的任务,主流的 VLA(视觉-语言-动作)大模型往往显得像拥有“金鱼记忆”。为了解决这个问题,过去两年的主流做法是引入记忆机制(Memory):要么做双系统分离(延迟高、误差易累积),要么把历史帧压缩进隐变量(丢失细粒度视觉特征),或者干脆无脑保留所有历史帧,做一个巨大的记忆缓存(Memory Buffer)。
但这带来了一个巨大的代价:海量的冗余历史帧不仅拖垮了模型的推理速度,还让真正关键的“线索”淹没在了无用的背景信息中。
那么,做长程记忆操控,一定要靠无脑堆叠历史帧吗?来自上海人工智能实验室、中国科学技术大学、上海交通大学等机构的最新工作 EventVLA 选择了另一条路:让大模型学会像人类一样“划重点”,只在关键事件发生时,提取并记住那极其稀疏的几帧“证据”。
凭借这套优雅的动态稀疏记忆机制,EventVLA 在 17 个仿真任务和 4 个真机双臂任务上,平均成功率暴涨了 40%,并且能够实时在双臂机器人上完成复杂的瞬时记忆任务,代码与全新 Benchmark 均已开源。
论文标题:EventVLA: Event-Driven Visual Evidence Memory for Long-Horizon Vision-Language-Action Policies
作者:Ganlin Yang*, Zhangzheng Tu*, Yuqiang Yang*, Sitong Mao, Junyi Dong, Tianxing Chen, Jiaqi Peng, Jing Xiong, Jiafei Cao, Jifeng Dai, Wengang Zhou, Yao Mu†, Tai Wang†
单位:中国科学技术大学, 上海人工智能实验室,上海交通大学,大连理工大学等
论文链接:https://arxiv.org/abs/2606.20092
项目主页:https://ganlin-yang.github.io/EventVLA.github.io/
开源代码:https://github.com/InternRobotics/EventVLA

EventVLA 框架总览。左上:非马尔可夫任务中的“记忆遗忘”挑战;右上:基于事件驱动的稀疏记忆架构;左下:全新的 RoboTwin-MeM 评测基准;右下:在各大榜单和真机上的压倒性性能优势。
把记忆拆解:
“视觉锚点” + “动态关键帧”
人类在执行长程任务时,并不会像录像机一样记住每一秒,而是记住“初始环境的布局”以及“几个决定性的瞬间”。EventVLA 正是基于这一直觉,将模型的记忆负担降到了最低。它完全摒弃了冗余的连续缓存,将视觉证据记忆(Visual Evidence Memory)拆解为两部分:
基础视觉锚点(Visual Anchors):由“第一帧”(提供全局静态布局)和“最近的短时历史帧”(提供局部运动线索)组成。这是一种免训练的启发式规则,足以应对简单的记忆任务。
动态关键帧记忆(KEM,Keyframe Evidence Memory):这是 EventVLA 的绝对核心 。在复杂的物理交互中,很多关键信息(如揭开盖子瞬间看到的物体颜色、抽屉里隐藏的道具)往往是转瞬即逝的 。KEM 模块作为一个轻量级的并行预测头,直接作用于 VLA 自回归 Transformer 最后一层的隐层特征 。由于这些隐层特征天然融合了当前的视觉观测与动作条件查询 Token,它让 KEM 具备了对机器人未来动作走向的 “前瞻性(Foresight-driven” 感知 。通过这种设计,模型能够直接预测未来 H 步内每一步演变为“任务关键帧”的概率,并在概率达标时自主决定何时、将何种视觉证据写入稀疏的 FIFO 记忆池中,从而在关键信息因交互而被遮挡或消失前,将其动态捕获并固化为长程决策依据 。
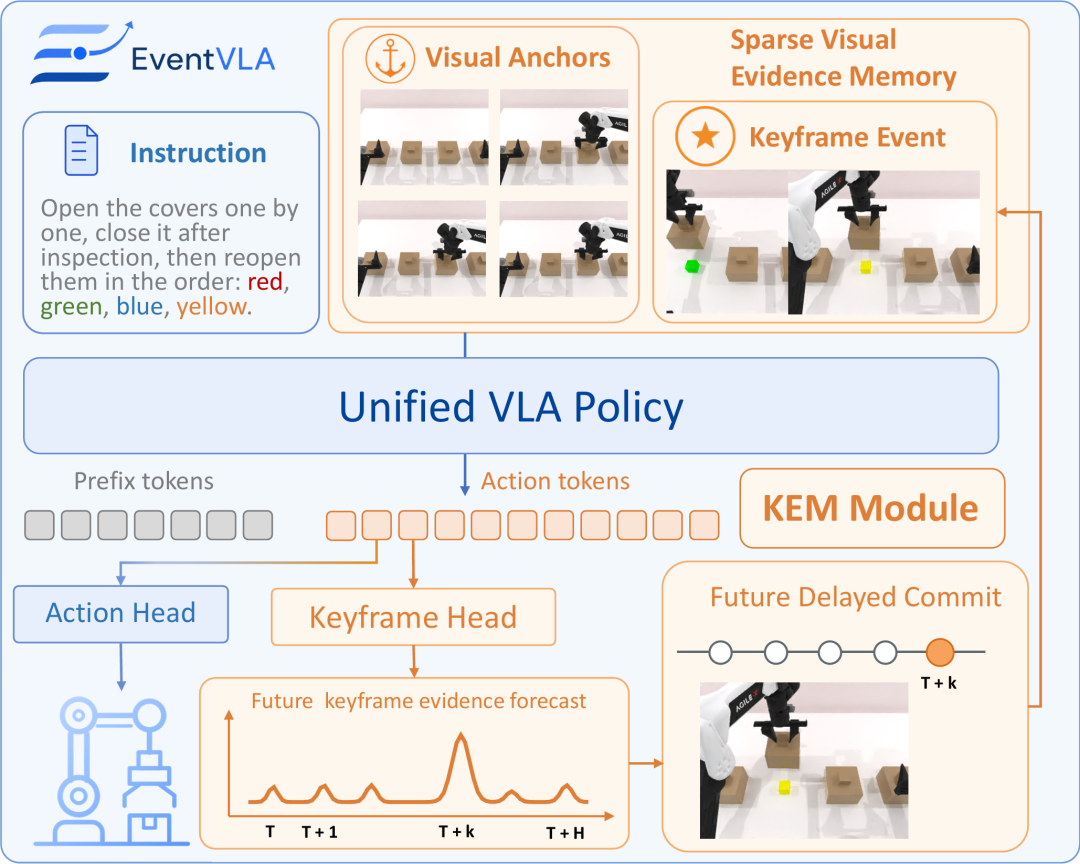
EventVLA 架构图。通过 KEM 模块对未来执行视野内的关键帧进行预测(Foresight-driven),并在事件发生时将其写入稀疏的 FIFO 记忆池中,随后与视觉锚点拼接,统一送入 VLA Backbone。
KEM 的精妙之处在于“前瞻性(Foresight-driven)”:它不是在事情发生后才后知后觉,而是基于当前的动作规划,提前预测接下来哪个瞬间是“任务关键时刻”(比如机械臂即将掀开盖子)。
当预测概率超过阈值,EventVLA 就会触发一次“写入”,把这极其珍贵的一帧存入记忆池中。为了避免同一事件被重复记录,EventVLA 引入了在目标检测中常用的 1D 非极大值抑制(NMS)和冷却时间(Cooldown)机制,从算法底层保证了记忆的“绝对稀疏”。
专为“瞬时记忆”打造的试金石:
RoboTwin-MeM
有了好的算法,还需要能真正检验其成色的考场 。现有的记忆增强基准(如 RMBench)往往可以通过简单的“拼接最近历史帧”作为锚点就能轻松通关 。为了填补这一空白,研究团队基于强大的 RoboTwin 2.0 仿真平台并依托 SAPIEN 物理引擎,推出了全新的 RoboTwin-MeM 诊断性基准测试。
该基准在统一的流水线内完美支持了自动化的数据合成与策略闭环评估,从基础设施层面保障了大规模数据生成的效率以及机器人操控评测的高一致性与可复现性 。此外,研究团队还为每个“动作-观测”对严格配置了细粒度的语言标注,将底层的物理交互与状态转换映射为直观的结构化文本描述,从而为下游记忆模块的训练提供了稠密且高质量的监督信号 。

RoboTwin-MeM 中的 8 个非马尔可夫任务。每个任务都明确标定了需要记忆的“瞬时关键帧”数量 n(蓝色高亮部分),n 从 1 到 5 不等,精准切中 VLA 的记忆痛点。
该基准包含 8 个极具挑战性的任务,平均执行步数高达 430~1544 步。更重要的是,它显式地参数化了记忆难度 n:即机器人必须在超长的执行过程中,精准捕捉并记住 n 个转瞬即逝的中间状态(如看颜色、记数字、复现指定顺序),才能通关。
03
实验结果:
以稀疏胜海量,仿真真机霸榜
在评测中,EventVLA 的表现全面超越了当前主流的无记忆模型(如π0.5, ACT, DP, X-VLA)和各类记忆增强模型(如 MemER, MemoryVLA)。
仿真环境碾压:在传统的 RMBench 上,EventVLA 以 67.8% 取得 SOTA。在真正考验瞬时记忆的 RoboTwin-MeM 上,纯依赖视觉锚点的模型成功率仅有 18.0%,而搭载了 KEM 模块的 EventVLA 成功率飙升至 75.2%,实现了质的飞跃。

RMBench仿真结果,EventVLA 以67.8%的成功率取得了压倒性的SOTA点数优势。

在需要瞬时记忆的 RoboTwin-MeM 测试中,绝大多数现有的模型(包括开源的 MemoryVLA 和强力的π0.5)几乎全军覆没,而 EventVLA 取得了压倒性优势。
真机双臂操作:团队在 ARX ACONE 双臂机器人上部署了 EventVLA,挑战了 4 个非马尔可夫任务(找隐藏方块、看纸条数字抓取 N 次、看木棍指示顺序抓取)。 作为基线的顶尖模型 因为没有记忆,成功率几乎为 0%~10%。 而 EventVLA 分别取得了 90%、60%、90% 和 75% 的极高成功率。无论是计数逻辑还是上下文记忆,EventVLA 都游刃有余。

真机部署下的 EventVLA 展现出极强的抗遮挡与时序推理能力。机器人能够自主通过视觉捕捉到纸条上的数字“4”,并在后续执行中准确抓放 4 次。
04
总结与展望
EventVLA 提供了一个极具启发性的范式转变:在具身智能的长程(Long-Horizon)操控任务中,与其让模型被动地接收并处理海量冗余的连续历史数据,不如赋予其主动筛选与结构化存储的“认知机制”。通过巧妙结合静态的基础视觉锚点与动态的前瞻性关键帧捕捉(KEM模块),EventVLA 成功打破了传统 VLA 模型对完全可观测环境的依赖。
它不仅以极低的计算和显存开销实现了对稀疏交互信息的高效保留,更在真实物理世界的复杂遮挡、时序计数和多阶段交互中展现出了卓越的记忆推理能力,为解决长序列非马尔可夫任务中的决策瓶颈确立了高效且优雅的新路径。
未来,团队计划进一步探索层级记忆(Hierarchical Memory)架构与更深度的特征压缩技术,以期在更加开放、事件密度更高的长程具身探索场景中,实现更大规模的记忆管理与认知调度。