文章转载自公众号:企业存储技术
本文只做学术/技术分享,如有侵权,联系删文。
近年来,AI大模型的规模以超摩尔定律的速度扩张,单个训练集群中的XPU(GPU/AI加速器)数量从数十颗迅速攀升至数百乃至上千颗,这对芯片之间的互连带宽、信号完整性、系统功耗与散热工程提出了前所未有的挑战。目前,业界头部厂商已经在Scale-up域互连、模块化封装和整机架构上给出了各具特色的答案。以下6张图分别展示了当下及未来最具代表性的几种技术路径:

·NVIDIA HGX B200/B300 NVL8:UBB板的中央放了2颗NVSwitch交换芯片,负责8颗GPU之间的Scale-up互连。
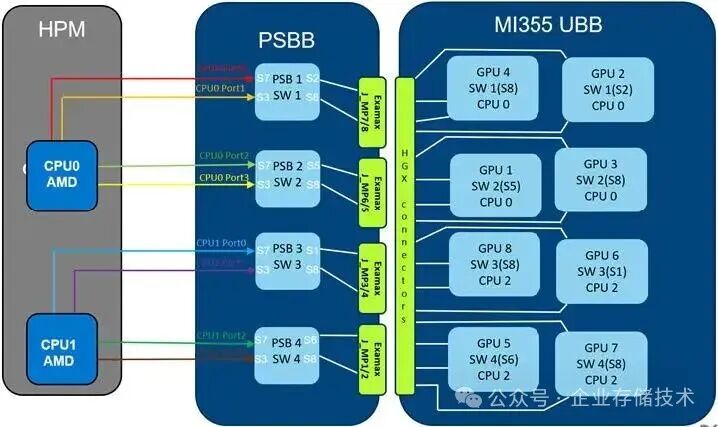
·通过Infinity Fabric(点到点Fullmesh,无Switch)连接的8 x AMD Instinct™ MI355X 288GB 1400W OAM(引用自Dell PowerEdge XE9785L Field Service Manual)

·NVIDIA NVL72超节点中的GB300 1U Compute Tray Block Diagram,每2颗B300 GPU+1颗Grace CPU焊在一块主板上。牺牲模块化换取极致的信号完整性(SI)和功率密度。

·AMD Helios AI超节点机架中的一个Compute Tray(MI455X+Venice CPU)。采用模块化设计,4个GPU模组直插背板,通过DAC铜缆实现Scale-up机柜级互连,兼顾灵活性与可维护性。
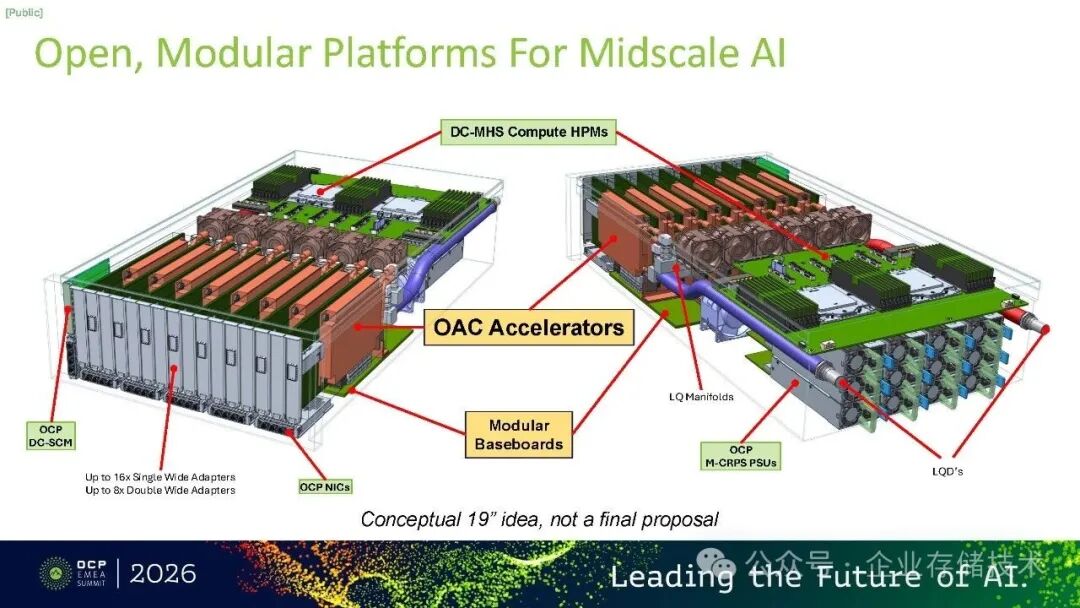
·《》概念图则展示了一种面向子机架级XPU的高功率适配卡形态,试图突破传统OAM在功率和尺寸上的限制;
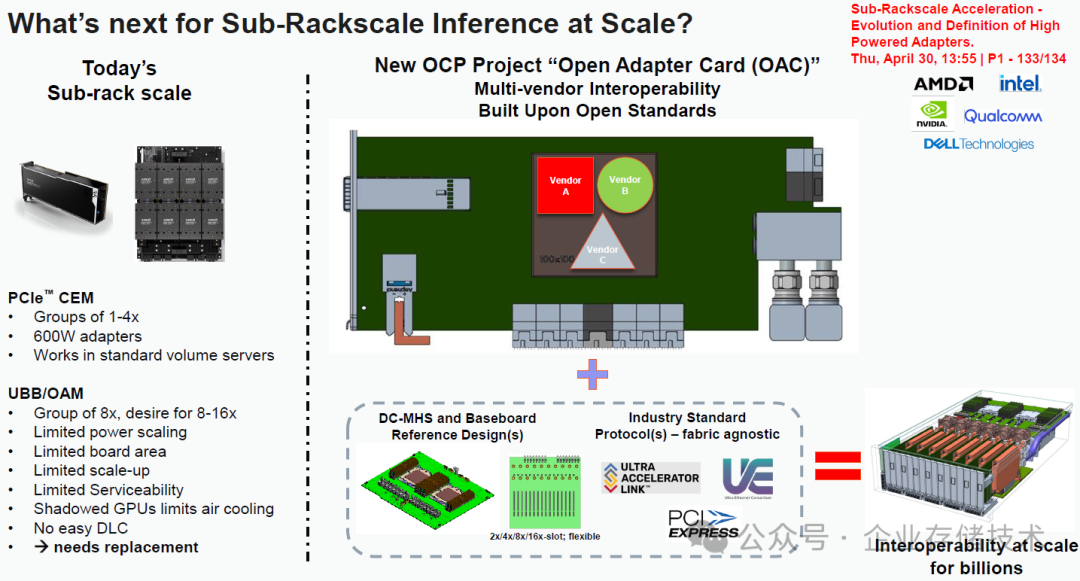
·上图在《》中讲解过,引用自上的演讲资料。这里补充一点:112 lane连接器,正好可以继续满足AMD 8个GPU之间的xGMI Fullmesh全网状连接(7x16)。
上述几种方案在信号走线长度、连接器级数、功耗密度和可扩展性上各有取舍:OAM 2.0模组虽兼容传统8卡服务器,但在超节点规模下因增加Mezz连接器和长距离PCB走线,导致112G乃至224G速率下的信号损耗逼近临界值;而采用模组直出背板、铜缆或光互连的替代形态,正成为下一代XPU封装与超节点设计的关键探索方向。
正是在这一技术转型的节点上,锐捷网络技术专家程旭升在2026 Open AI Infra Summit超节点生态论坛发表了题为《下一代XPU模组设计的方案探讨》的演讲,系统分析了下一代XPU模组面临的挑战、形态设想、供电散热方案以及在超节点中的铜互连与光互连实践。以下内容即根据该演讲整理而成,并由@唐僧_huangliang添加评论。

目录
1. 下一代XPU模组的挑战及设想
2. 下一代XPU模组设计的方案探讨
3. 基于XPU模组的超节点计算tray设计方案
4. 单层光互联超节点设计探讨
01
下一代XPU 模组的挑战及设想
下一代XPU 模组将会面临XPU芯片多 die 封装,芯片尺寸变大,SI(Signal Integrity,信号完整性)速率将会急速提升,从现有的56G、112G 提升到 224G 乃至更快。与此同时,XPU的功耗也会升的更大,XPU模组会面临相关问题,比如说其供电方案会从水平变成垂直,带来背向散热的挑战,对于整机系统工程而言,比如说 64卡、128 卡甚至 512 卡等系统,其HBD 域的提升对于整机工程域的技术挑战也相当大。
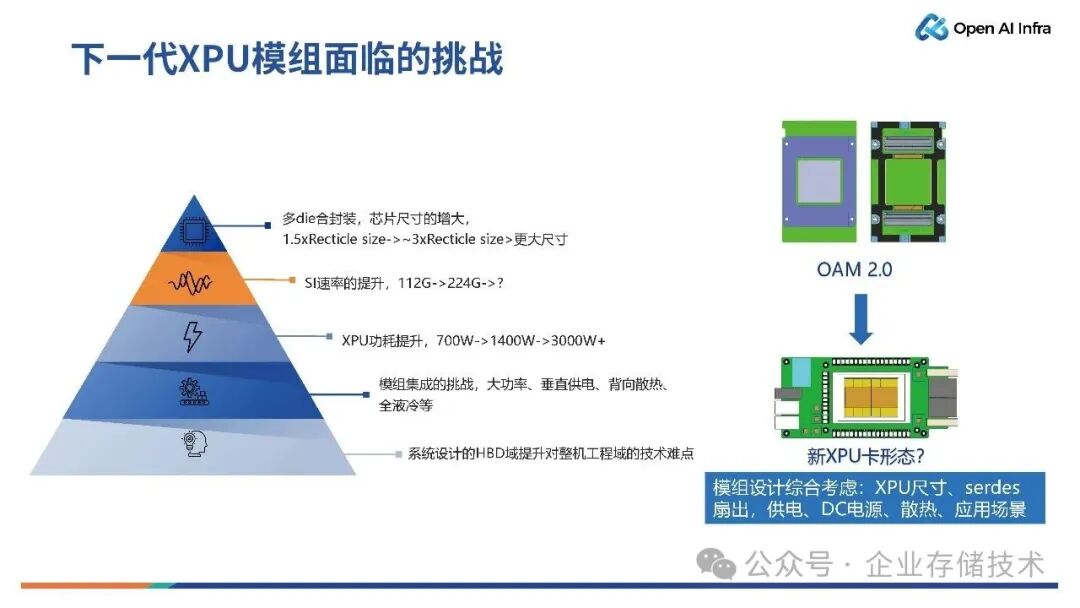
综合看,XPU模组设计需要考虑如下几点:XPU 芯片的尺寸、SerDes 扇出数量和方向、供电方案、DC 电源以及应用场景等。
下一代XPU 模组应该如何变化?下图是关于 XPU 模组的形态设想。
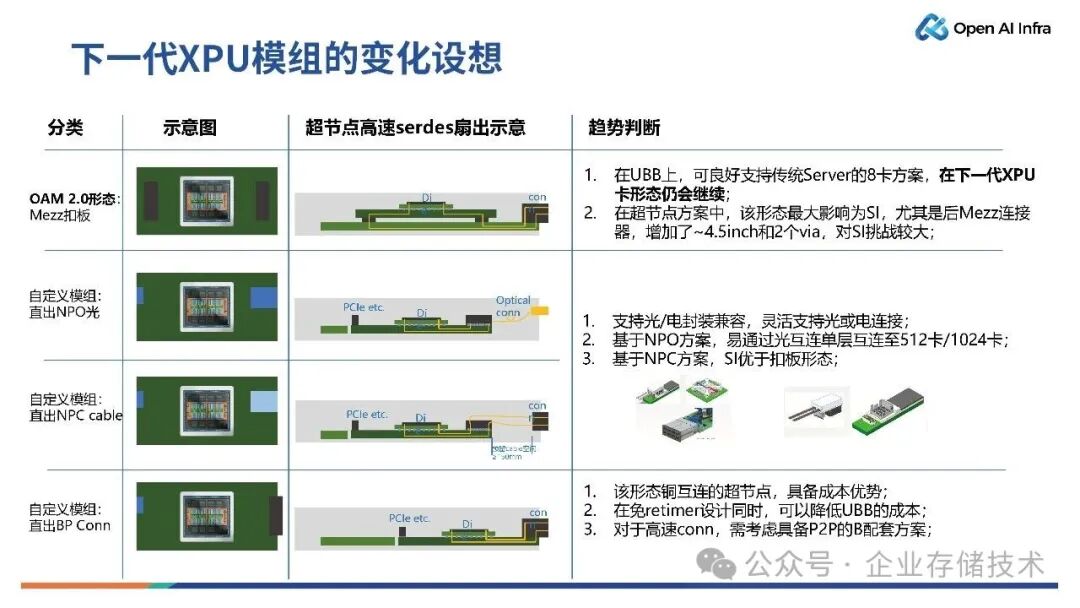
当前行业内采用的OAM 2.0 模组,在匹配传统 8 卡服务器时比较合适。但是在超节点方案中,OAM 2.0 模组最大挑战之一是 SI,它在信号传输的链路上,不仅增加了物理路径向后的 Mezz 连接器,要增加两个过孔(Via),还额外增加了约4.5 英寸的走线距离,这些因素会恶化信号预算,对 SI 的挑战较大。
唐僧_huangliang点评:OAM/SXM后续代表产品,如NVIDIA Rubin NVL8、AMD MI440X等。
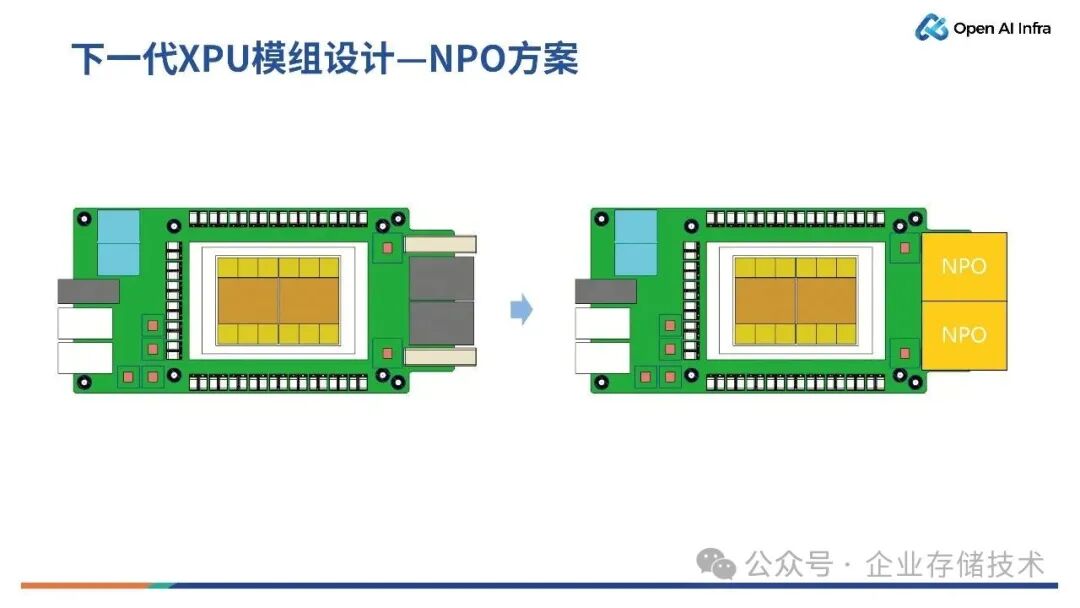
上图所示的中间两个自定义模组是直出NPO 光形态和直出 NPC 线缆形态。现在的光互连是热门话题,业界有提议将 XPU 采用光电合封方案,但这意味着XPU 完成验证之后,还要将光模组合封在一起,这对于整个 XPU 的推出时间以及合封良率有着一定的挑战。但如果将NPO 模组和 GPU 芯片贴在一张 OAM 卡上,技术风险小,不会有额外的成本,可以加速产品推向市场。
但在超节点系统中,铜互连依然有着巨大的优势。在上图第四种模组中,该形态基于铜互连,采用连接器直出方式,避免高速信号途径UBB板布局,而是直出到BP Conn(Backplane Connector,背板连接器),在超节点内部实现 SI 的收益最大化,即实现更稳定、更高效的电信号传输。
唐僧_huangliang点评:DAC连接器直出方式后续产品,如NVIDIA Vera Rubin NVL72(GPU不是单独模块)、AMD Helios/MI455X。
下一代XPU 模组应该具备什么样的形态?
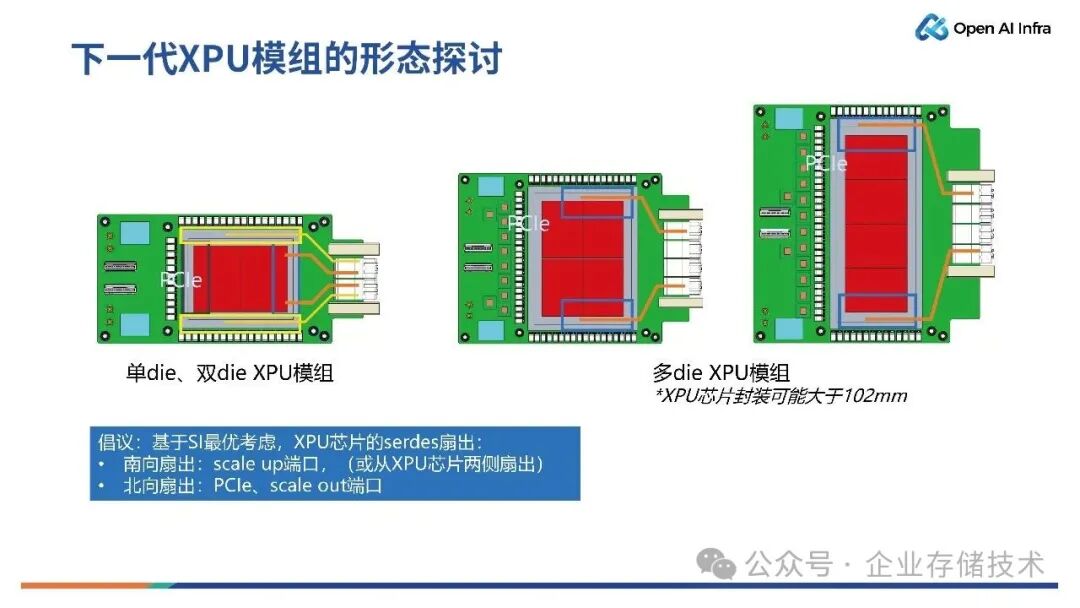
如上图所示,是几种未来不同芯片尺寸的构想图。
最左侧是单die/双die的 XPU 模组,其单卡功耗将可以达到 1200W、2000W 甚至更大,其 SerDes 预期会达到 3.2T 或者6.4T。
随需求的发展,后续还会有四die的合封芯片,可能是一字形排列或田字形排列的类型。不过,一字形排列的对于芯片的封装挑战较大,田字形的四die 合封可能性较大。
因此,当前基于单die或者双die 的 XPU 模组,其设计思路是基于 SI 最优,将 SerDes 直接扇出到背板,分为南向和北向。南向扇出是到Scale Up 端口(或从 XPU 芯片两侧扇出),北向扇出到 PCIe、Scale Out 端口。
基于下一代XPU 模组的服务器架构应该是什么样?接下来让我们讨论一下。

超节点的计算Tray,采用了 Scale Up 端口直出到背板的设计方案。每个Tray 上有四个 XPU 模组,直接连接至背板侧。因此,其 GPU 的 SerDes 可以直出到背板系统或者 Cable Tray。
唐僧_huangliang点评:NVL72和AMD Helios的计算Tray其实都属于这种方式,有一点区别是NVIDIA GB300的CPU和GPU应该都焊在主板上;而AMD MI455X则是4个模块,连接到Venice服务器主板。焊死的好处是SI信号插损最小;而模块化的好处则是灵活(除了不同CPU/GPU搭配,还便于维修),CPU-GPU之间如遇SI问题用retimer也不难解决。
在典型8卡服务器场景,基于下一代XPU模组可考虑通过两种方式互连8卡:一种是XPU 模组实现 Fullmesh 互联(fullmesh的转接板);另外一种是通过交换芯片来实现全带宽互联(switch in server)。
唐僧_huangliang点评:根据AMD公布的MI440X照片,应该还是在UBB板上无switch直接Fullmesh互联;NVIDIA Rubin NVL8应是继续通过NVSwitch互联。
目前看,8卡服务器可能不满足大模型参数量的发展需求,需要进行 16 卡服务器的设计。由于其互联是在一个系统内,互联比较复杂。因此我们建议采用中置 BP(背板),一层竖插 8 张,再加一个交换节点,分两层可以实现 16张卡的系统设计。
唐僧_huangliang点评:我见过有的国产GPU服务器采用这种设计,成本上应该要比2台8卡GPU服务器高,另外如果采用PCIe Switch搞不好中间带宽会有瓶颈?另一种方案就是OCP前不久刚介绍过的Open Adapter Card,提供8-16 XPU卡支持,个人感觉OAC如果后续用UALink互联的话,在16卡时也要分摊Switch的总带宽。
02
下一代 XPU 模组设计的方案分享

在规格设定上,下一代XPU 模组基于双die 设计,未来随着芯片工艺的进步也可以做到四die 设计。模组尺寸为 102 毫米 X210 毫米。之所以设计 102 毫米的宽度,是因为基于这个尺寸可以在 19 英寸的机柜上放置四张模组,以实现向前兼容。
该GPU 芯片模组的功率设计不低于 1400W;其南向接口最多支持 64 Lane/GPU 卡,更多考虑导向方案和 SerDes 数量,北向接口支持 Gen5/Gen6 的 PCIe,更多考虑供电和管理侧接口。
唐僧_huangliang点评:国内的超节点目前32-64个XPU的偏多,另外阿里磐久128本质上是2套64 XPU超节点。NVIDIA NVL72和AMD Helios都是72个GPU,所以南向Scale-up接口不能低于72 Lane。
接口设计
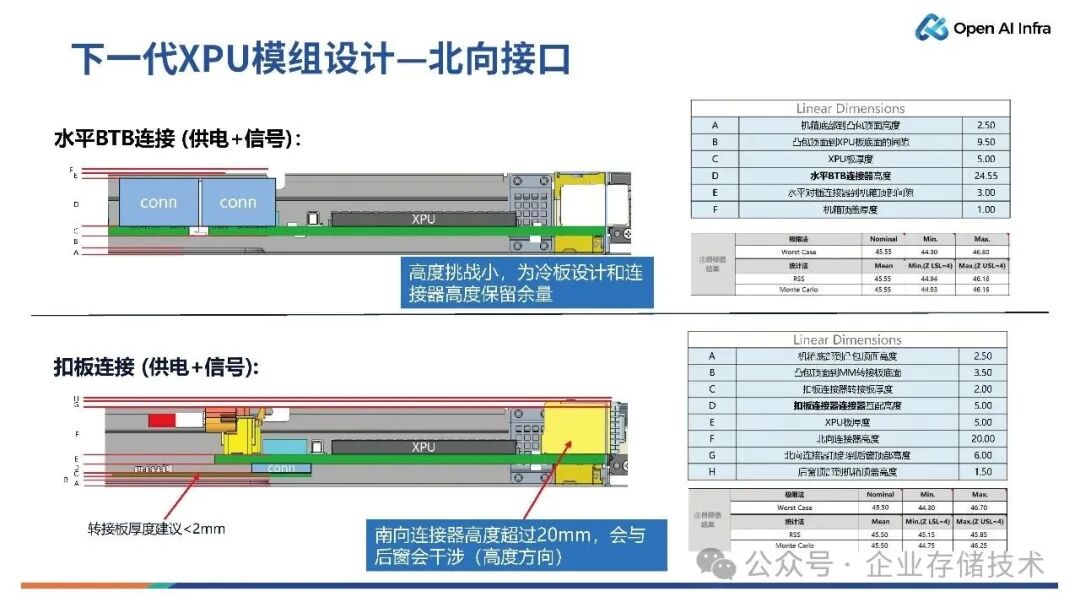
如上图所示,北向接口可以有多种选择。第一种方案是,仍然选择水平对接的板对板连接器方案,前面插到背板,后面与sw板对插,实现PCIe 的通道北向扇出, Scale-Up 端口南向扇出,避免传统长距离走线带来的信号损耗。
另外一种方案是XPU 模组采用扣板连接的形式,该扣板连接器可以实现供电或者 PCIe、低速信号。不过根据分析,如果采用扣板形式,由于机箱内部的高度空间极度紧张,OAM卡的top面高度空间基本被限制在 20 毫米以内。在这个高度下,对连接器的高度及密度不友好,通常选择4pair/column的连接器方案。OAM卡SerDes扇出数量有一定的限制。
如果采用水平对接的话,底部区域可以更加宽裕,上面能够选择的连接器就更多。比如说选用8 pairs 连接器可以轻松实现 64 通道或者 72 通道的南向的 SerDes 的扇出。
唐僧_huangliang点评:AMD Helios应该采用的是水平对接方案。其实扣板方案,在1U机箱中还有一个维护要开盖的问题。
导向设计

在南向上,该XPU 模组因为是直插背板系统,那么背板系统连接器不是主要的问题,更大的问题变成了该模组的导向系统如何设计?
板卡在盲插情况下,一定要有导向系统。导套可以左右各一个,如上图所示。这种导套会占用OAM卡102毫米的宽度空间,一个占据 15 毫米,两个就会占据 30 毫米,但优势是导向能力最优。
那么为了减少对空间的占用,可以如上图中间所示,将导套放到上面,其优势是不占用布局宽度,但是劣势是占用了连接器的高度,那就可以考虑4Pair 的连接器。
那如果密度更大,GPU的扇出 SerDes 达到 6.4T,那就可以如上图最右侧所示,将导套偏转放在中部,同时减少导销、导套的空间。
供电设计
下一代XPU 模组的供电设计比较简单。

从现在的规划而言,下一代XPU 模组的供电依然会采用 54V 方案,通过 IBC(Intermediate Bus Converter ,中间总线转换器)转换成 12V,或者更低的 6V,实现对GPU 供电。
供电模式可以有两种,水平供电模式或者垂直供电模式。
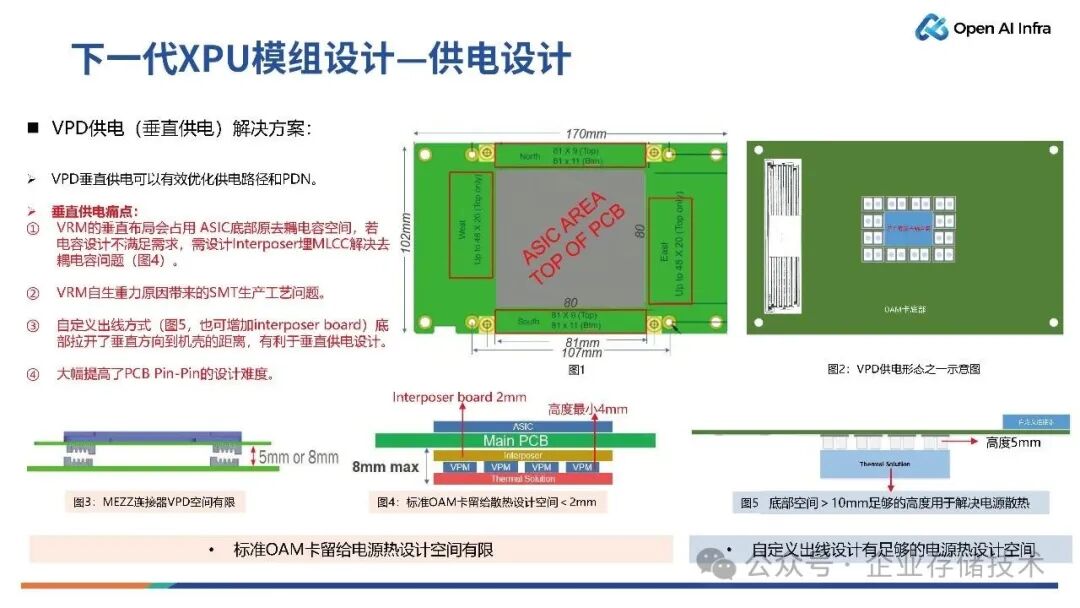
水平供电的痛点在于XPU 功耗越来越大导致 PCB 损耗越来越大,压降、PDN 很难满足电源设计要求等;而垂直供电的痛点在于,VRM(Voltage Regulator Module,电压调节模块)的垂直布局会占用 ASIC 底部原去耦电容空间,若电容设计不满足需求,需设计 Interposer(中阶层)将 MLCC 埋进去以解决去耦电容问题,确保芯片的稳定工作。
此外,垂直供电面临着另外一个挑战,即散热。一般而言,标准OAM 卡留给电源热设计空间有限,连接器的热耗比较大,为采用风冷方式进行散热,就需要预留散热空间,至少 3-4 毫米的散热风道,这样整个堆叠结构的底部至少保留 8-9 毫米的空间。
因此,采用垂直供电的方式,其背面需要空间散热。
散热设计
在关于模组的散热设计方面,我们做了两种功耗的仿真。
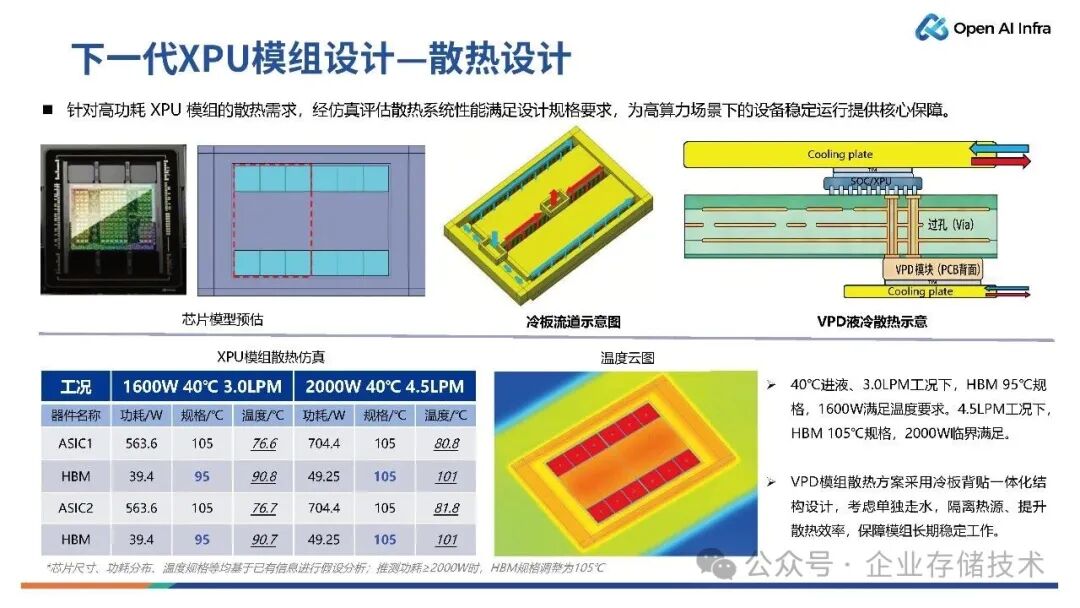
如上图所示,一种是1600W,一种是 2000W,都是双die 设计的 XPU 模组。其中可以看出,最大的挑战在于 HBM 的散热。业界不同的 HBM 性能有一些差异,有些产品是 95 度的规格,其散热挑战就比较大。在 2000W 情况下,HBM 考虑支持的结温要到 105 度,才能够实现更好的散热。
唐僧_huangliang点评:如上图,1600W的XPU模组,在40℃进液(二次液)温度的下只需要3.0LPM流速,即可支持95℃规格的HBM内存;而到了2000W的XPU,在同样进液温度下要提高到4.5LPM流速,并且HBM支持的温度规格也要提高到105℃。
另一点,如果设计了PCB背面VPD垂直供电,则背面也要加冷板散热结构。
互连设计
此外,我们也需要对XPU 模组的互连设计进行规划。
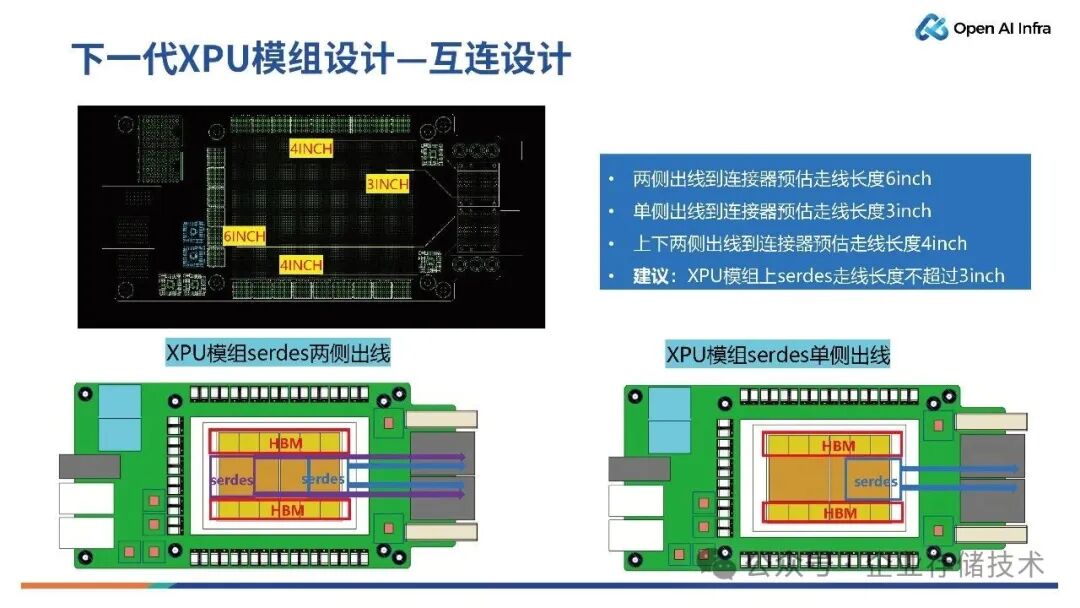
如上图所示,XPU模组的 SerDes 可以双侧出线,也可以单侧出线。如果两侧出线到连接器预估走线长度为 6 英寸,而单侧出线到连接器预估走线长度为 3 英寸。如果GPU 模组本身较厚,那么 6 英寸情况下 SerDes 损耗会比较大。
我们建议,对于下一代的XPU 芯片设计,可以将南向接口放到右侧,北向接口放到左侧,XPU 模组上 SerDes 走线长度不超过 3 英寸,这样损耗可以节省 3-4dB。
超节点场景互连
下图是针对XPU 模组应用在超节点场景所做的估算。
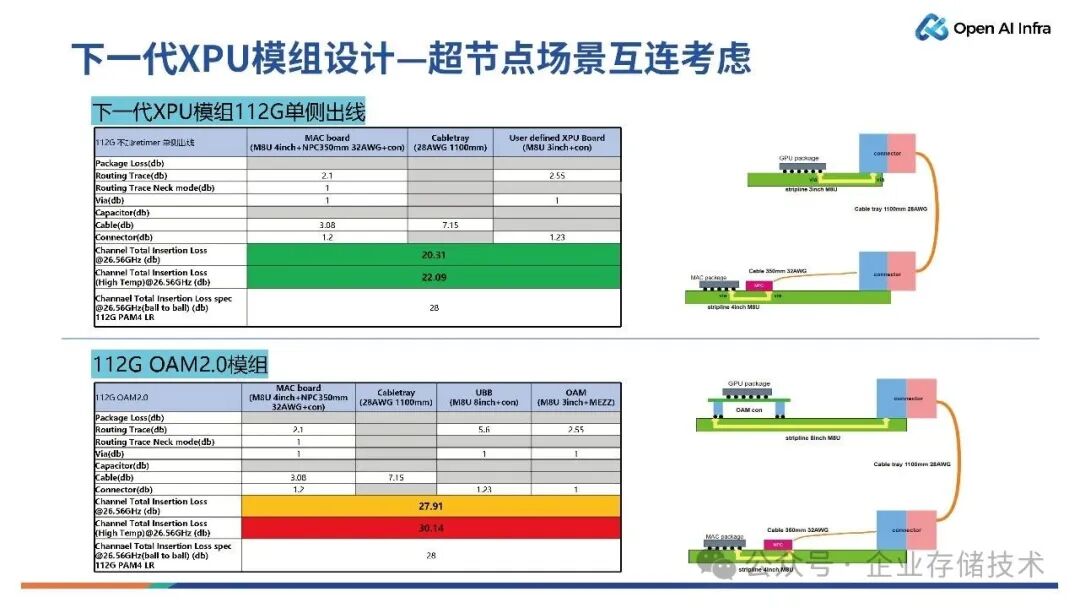
如上图上半部分所示,此处所展示的是基于Cable Tray 的 112G 设计系统。该系统采用整机柜形式,从GPU 芯片到连接器、Cable、连接器、交换节点,整个损耗在 20dB 左右,高温下的损耗在 22dB,远低于规范所要求的 28dB,有足够的损耗余量,能够满足 112G 设计系统的需求。
上图下半部分是112G 的 OAM2.0 XPU 模组,对比可知,该方式的设计损耗比较偏临界数值(传输损耗是 27.91 dB,高温下的损耗为 30.14),就会超过规范所要求的 28dB。
唐僧_huangliang点评:如图,OAM方案的差别,一个是多一次插损;另一点就是南向Scale-up接口包含从左侧的出线——在PCB内的走线更长。
这正是为什么我们需要选择一个新的XPU 模组封装形态的原因。
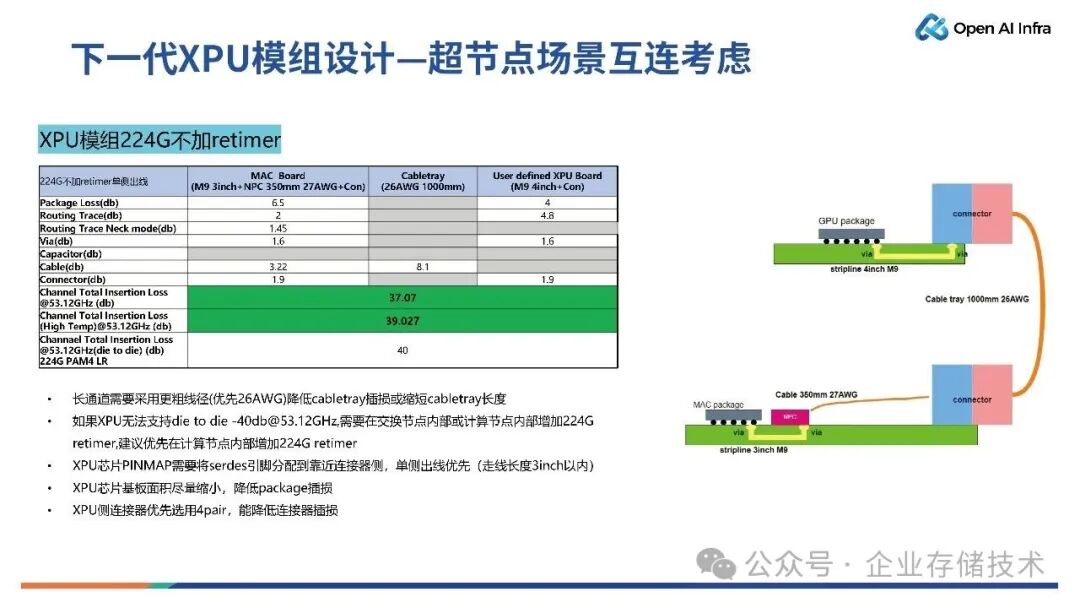
如上图所示是XPU 模组在 224G 系统不加 retimer 的情况下的相关损耗情况。根据计算可知,die 到 die 的损耗在 37dB,叠加高温损耗是 39dB,基本上可以满足规范所要求的 40dB 的损耗,因此这种设计方式是可以适用于超节点的方案。
唐僧_huangliang点评:仔细对比112G和224G的配置,可以看到前者的MAC板、Cable tray、XPU板用的材料等级不同。我整理在下表:
MAC Board | Cabletray | User defined XPU Board | |
下一代XPU模组112G单侧出线 | M8U 4inch+NPC350mm 32AWG+con | 28AWG 1100mm | M8U 3inch+con |
224G不加retimer单侧出 | M9 3inch+NPC 350mm 27AWG+Con | 26AWG 1000mm | M9 4inch+Con |
不难看出,为了应对速率提高,PCB材质提高,线也变粗了。
以上这些,就是关于XPU 模组本身的硬件工程设计方案。
03
基于下一代 XPU 模组的计算 tray 设计方案
那么基于下一代XPU 模组的计算 tray 设计方案应该如何进行?
基于铜互连方案

如上图所示,这是4 卡*2000w计算节点的布局参考。该方案基于铜互连方案构筑而成,将 4 个 XPU 模组放到计算节点的前侧,直插背板系统,这就可以实现免 retimer 设计,可以让系统设计更为简洁。未来如果 XPU 模组实现四die 的设计,我们认为采用田字形布局更为可靠。
唐僧_huangliang点评:AMD Helios/MI455X的GPU模组排列方向与上图有些相似。不过Helios节点适配的是双宽机架。
基于光互连方案
那么基于光互连的方案如何设计?
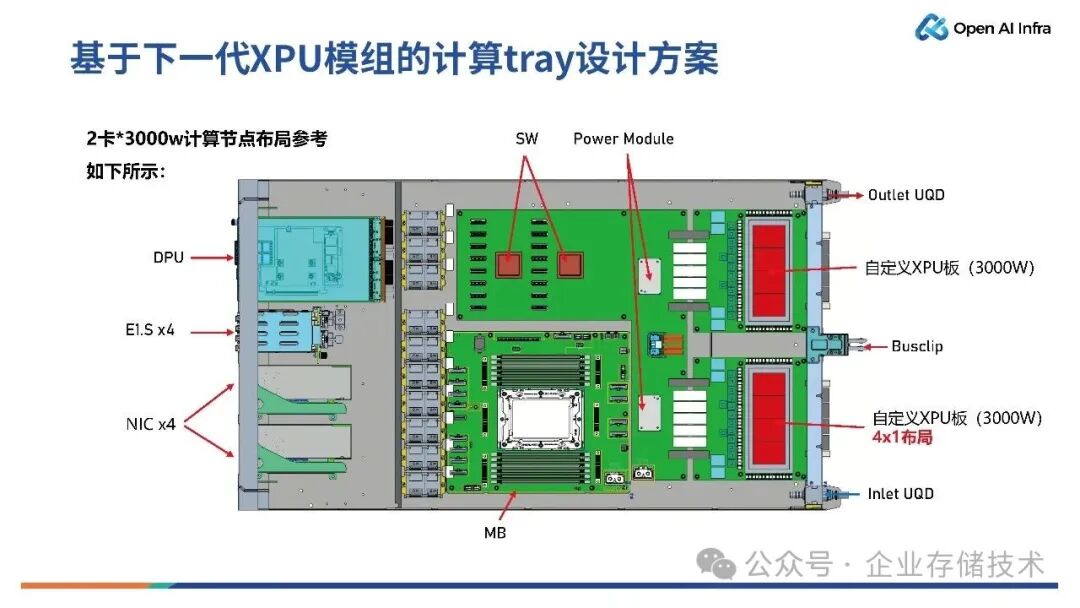
如上图所示,是2 卡*3000W计算节点的布局参考。在该方案中,如果需要达到512 卡或者 1024 卡,可以将连接器、模组做一个小小的改版,就可以变成光互连的场景。
唐僧_huangliang点评:像AMD Helios那样的双宽Compute Tray,若面对上图XPU采用4x1 Die布局宽度增大的情况,仍可以支持到单节点4卡。
04
单层光互联超节点设计探讨
那么,基于单层光互联的超节点设计如何实现?
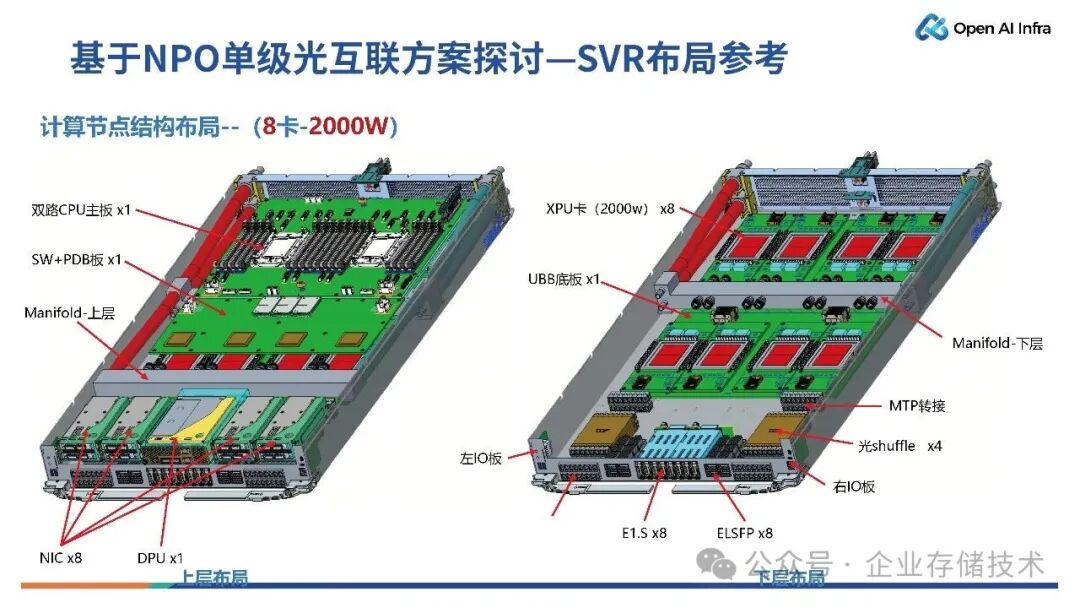
我们认为,基于光互连,计算节点不一定要非要做到跟超节点一样。不必是1U 4卡,也可以考虑 2U 8卡的设计。
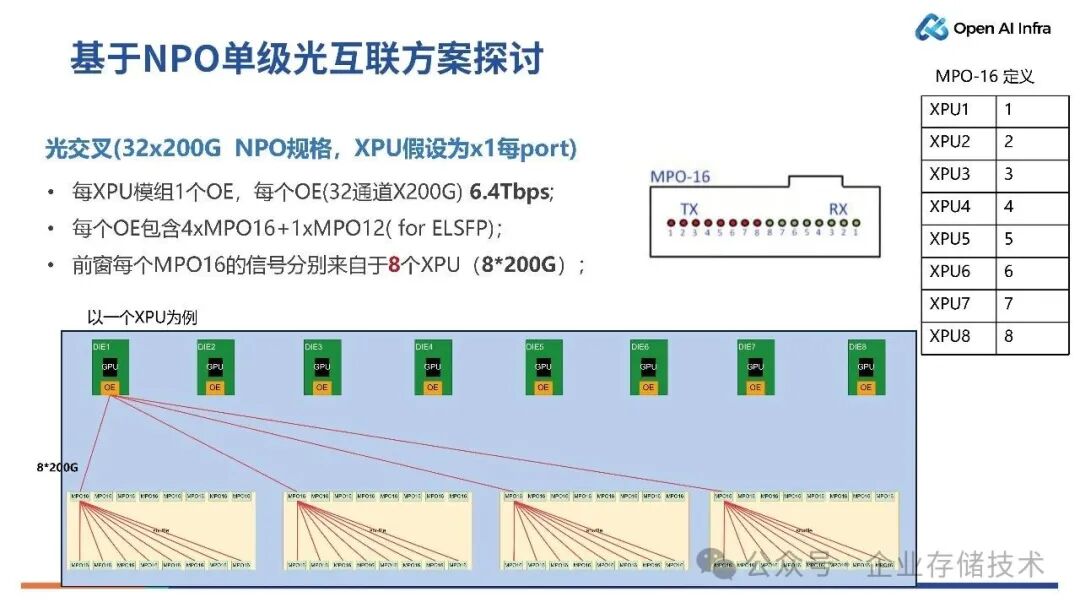
如上图所示,该方案具备8 个XPU 模组,上面有 OE(Optical Engine,光引擎)系统。该 OE 系统可以直接将所有端口都通过一个 Shuffle(Fiber Shuffle )实现连接。每个通道对应一个 XPU 模组,比如说 1 通道对应GPU1,2 通道对应 GPU2。我们在一个 2U8 卡的系统里面,就可以实现全光扇出。
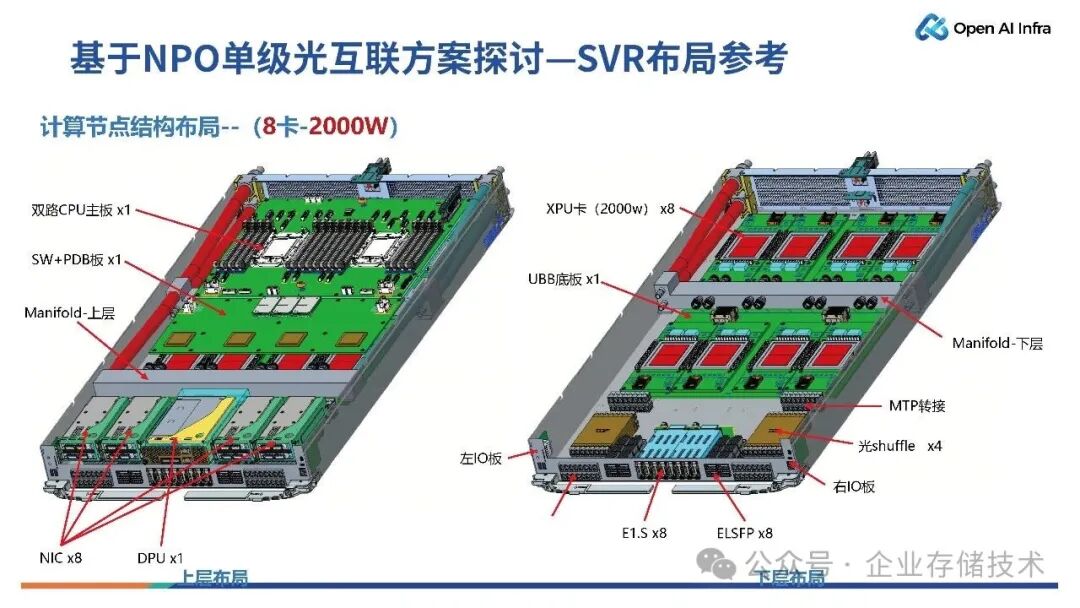
如上图所示是一个2U8 卡的布局,可以实现 2U 设计,1U 摆放 8 张基于 NPO 的光模组,另外一层实现主板以及其他 PCIe Switch 的设计。
唐僧_huangliang点评:估计是由于光传输的阻抗小,SI和延时问题比铜要好不少,所以8个GPU水平布局,与光shuffle之间的距离远近也不太敏感了。
整体而言,基于该方案能够实现512 卡或者 1024 卡的全光设计。如果全部是 2U 节点,那么一个机柜可以放置 16 台服务器、实现 128 卡,4 个机柜(还要加2个交换柜,编者注)则可以实现 512 卡的单层全光互联。
参考内容 《》
END
✦
✦
2026中国AI智能体大会
✦
智猩猩主办的2026中国AI智能体大会7月2-3日杭州举行,大会设有开幕式,企业级AI智能体、AI智能体产品创新2场论坛,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness7场技术研讨会。最终议程已公布。











点击下方名片 即刻关注我们










