
因为公众号平台更改了推送规则。记得点右下角的大拇指“赞”和红心“推荐”。这样每次新文章推送,就会第一时间出现在订阅号列表里。
将预填充和解码过程拆分到不同硬件上运行的AI推理管道——例如两个不同的GPU或一个GPU与一个定制加速器——已经显著加快了AI推理速度,并大幅提升了效率。
但AI推理的分解并不止于此:它还可以深入到模型本身。特别是前馈网络(feed-forward network,简称FFN),为在解耦的流水线中优化AI推理提供了一个独特的机会。
与其在单一硬件上管理整Transformer层或模块,分散式流水线可以将其拆分:将attention机制运行在内存丰富的加速器(如GPU)上;而将FFN运行在无需处理KV缓存不断增长的加速器上。
FFN的工作原理
一旦attention机制完成,模型就会以输出向量的形式提供一种“最佳猜测”。这种猜测基于模型可用的有限“空间”,并相对于每个先前的token进行调整。由于attention层无法看到整体情况,因此FFN就派上了用场。
FFN显著提升了猜测的质量,但其工作需要更大的表面积。它首先通过增加维度来扩展可用空间,从而能够访问训练过程中学到的更广泛的模式集合。
本质上,attention表示:“根据我目前所掌握的信息,这是最合理的猜测。”而FFN则表示:“是的,以下是一些支持这个猜测的原因。”
例如,一个token可能传入,FFN 可以通过装饰器以及其后传入的Python代码来确定:
这是用于管理网络请求或路由的代码部分
它使用Python 编写
很可能基于Flask 构建
Flask通过装饰器来定义端点,因此应将其视为一个端点的一部分
代码表明这是一个“/”路由,因此与网站的首页相关
其工作原理是扩展来attention层输入的数据的维度空间。在GPU 和优化加速器之间,会传入一个“隐藏状态”——本质上是一个捕获attention过程结果的向量。该加速器随后将其投影到更高维的空间中,以捕捉更多上下文信息。
一旦完全捕捉到这一上下文,它就会被“重新”放入标准维度中,获得更为丰富的纹理信息,然后要么输入下一层,要么在最终层时,结果会继续进入词汇选择阶段以生成最终输出。
基于内存优化加速器的FFN也非常适合混合专家模型。使用HBM的GPU虽然能实现计算饱和,但需要显著更大的批处理大小;而基于SRAM的加速器在小批处理规模场景下表现更优。
分解FFN可加速AI推理解码步骤
AI模型的大部分参数都包含在FFN本身中。但FFN所需的内存是固定的,attention模块方面没有可扩展的KV缓存需要管理。
相反,您清楚地知道其中的内容:函数所使用的权重,用于捕捉输入到attention层或转化为最终标记时的细粒度上下文。这使其成为在固定内存的分散式流水线中,将计算卸载给另一组加速器的理想选择。
因此,您可以预测性地在整个AI推理过程中扩展和管理FFN。
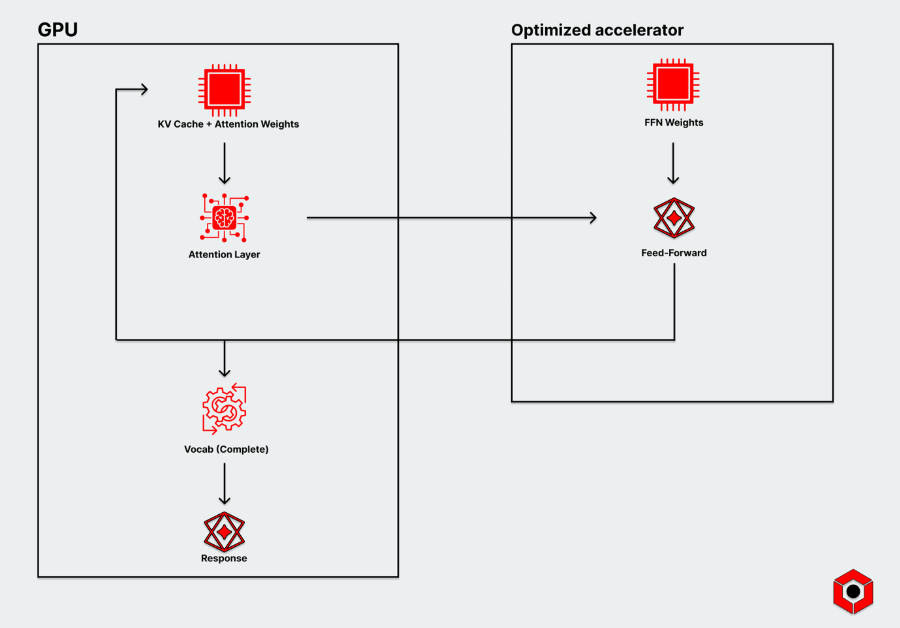
例如,内存优化的加速器可以将FFN托管在SRAM池中,使其在无需调整日益增长的KV缓存时延与吞吐量之间复杂权衡的情况下,实现显著更低的延迟处理。
这种方法也非常适合混合专家模型。
虽然专家的全部数据仍存储在SRAM中,但推理过程仅调用其中一小部分专家。权重始终可访问,而加速器仅在需要特定专家时才支付计算成本,从而降低了能耗。
分层FFN能为企业提供更好的可预测性
AI应用本质上难以预测:输出结果可能差异巨大,KV缓存的大小未必均匀增长,甚至提示文本中多出一个空格也可能导致完全不同的响应。
这对企业来说是一个巨大的挑战,因为AI驱动应用的成功不仅体现在结果上,更在于能否可靠、可量化地满足需求并实现扩展。没有任何企业希望自己的应用在几天内就迅速走红,导致现金流被大幅消耗。
分层的FFN如何推动推理瓶颈时代下爆发式增长
由于AI推理需求持续飙升,以满足用户对质量与延迟的要求,GPU 的需求正在急剧增长。这极大地加剧了GPU的部署压力,并在平衡延迟与吞吐量需求时进一步导致效率低下。
自定义加速器可管理FFN,有助于解决上述两个问题:它在不牺牲质量的前提下保持低延迟体验。同时,当任务需要使用GPU而非推理优化的加速器时,还能帮助优化GPU的使用效率。
处理FFN也并非推理流程中唯一能支撑业务需求的环节。运行在支持SRAM加速器上的小型模型,能够处理代理网络中相当一部分较为简单的任务(例如代码生成中的任务)。此外,加速器还可托管预测模型以加快推理速度,而这类模型也在迅速进步。
在每种情况下,拆解显然是实现规模扩展的途径,以应对随着更大规模智能体网络出现而急剧上升的整体流程复杂性对AI推理的巨大需求。
原文链接:
高端微信群介绍 | |
创业投资群 | AI、IOT、芯片创始人、投资人、分析师、券商 |
闪存群 | 覆盖5000多位全球华人闪存、存储芯片精英 |
云计算群 | 全闪存、软件定义存储SDS、超融合等公有云和私有云讨论 |
AI芯片群 | 讨论AI芯片和GPU、FPGA、CPU异构计算 |
5G群 | 物联网、5G芯片讨论 |
第三代半导体群 | 氮化镓、碳化硅等化合物半导体讨论 |
存储芯片群 | DRAM、NAND、3D XPoint等各类存储介质和主控讨论 |
汽车电子群 | MCU、电源、传感器等汽车电子讨论 |
光电器件群 | 光通信、激光器、ToF、AR、VCSEL等光电器件讨论 |
渠道群 | 存储和芯片产品报价、行情、渠道、供应链 |

< 长按识别二维码添加好友 >
加入上述群聊

带你走进万物存储、万物智能、
万物互联信息革命新时代











