点击下方卡片,关注“具身智能之心”公众号
事情是这样的,我们最近做了件事:把NVIDIA Jim Fan,近半年挂名的工作拉了个单子。
他是英伟达 GEAR 实验室的一号位,GR00T 项目的联合负责人,推特签名写着"Solving Physical AGI, one motor at a time"。
全世界最会给具身智能布道的人之一,可以说他的工作能影响全球具身的发展方向。

论文清单拉完,20 篇。但看完之后,有件事是我们没想到的:真正在做大脑的工作,只有两三篇。
Vesta 算一个(通用具身推理模型),NitroGen 勉强算半个(其实是游戏 agent),再加一篇视觉表征预训练。剩下十七八篇,全是在干别的:造数据、造仿真,或者把仿真里学的东西迁到真机上。
当然,这不是说大脑不重要。20 篇论文还不能给整个行业下这种判断。
但它代表的是一件更具体、也更值得琢磨的事:英伟达现在并没有把重心放在大脑上。他们把力气押在了大脑之外,仿真、世界模型、Ego、灵巧手等等。
这是他们的判断,不是所有人标准答案。但一号位用 20 篇论文的选择替自己投的票,我们觉得值得认真看一看。
01
并不是不做大脑
先澄清一下,不然容易造成大家的误会。
Jim Fan 当然做大脑。Vesta 就是一个高层推理模型。负责"看懂场景、想清楚该干嘛"这一层。并且把定位、导航、问答和Planning的能力做到一起,也就是通用具身推理模型。

但低层的末端具体怎么动的感觉-运动策略,jim fan基本不当研究课题,反而是当成一件可以被"制造"出来的东西。
这就是今天我们文章的支点:高层认知,他当研究做;低层策略,他当产品造。
如果沿着这个分界,再回头看那十七八篇论文,脉络会更清晰。他们基本上都在服务于一件事:构建一条能源源不断"造"出低层策略的流水线。
这条流水线分三段,数据、仿真、迁移。前面两个部分和大家已经聊得够多,我们快速带过;真正的重头戏在第三段。
02
数据的本质是烧人,世界模型是新电网
数据这部分,Jim Fan 说了句狠话。他在 Sequoia 的"Physical Turing Test"演讲里讲:
真机数据是"人力燃料",比化石燃料还糟糕。你真正消耗的还是人力。一台机器人一天最多采 24 小时,遥操作背后站着的是一个个真人。他把这条路比作烧化石燃料,把仿真比作核能。
所以 GEAR 近半年数据的工作很多。
EgoScale 用第一视角人类视频、GRAIL 从 3D 资产加视频先验生成、HumanoidMimicGen 用整身规划批量造。底层都是同一个动机:别烧人,去仿真里烧核能。
第二部分是仿真和世界模型。这块的信号也很明确:世界模型不再是「一条候选路线」,它已经成为基础设施本身。
Cosmos 3、Isaac Lab、SimFoundry,一个负责生成、一个负责高性能仿真、一个负责自动造场景。
Jim Fan 给 2026 定的调子是一句口号:"2026 is the year of World Models for physical AI",范式从「预测下一个词」变成「预测下一个物理状态」。
这两段我们点到为止。因为它们只是在为第三段蓄势:只会造数据、造世界还不够,得能把仿真里练出来的东西,稳稳地搬到真机上。
这一步过去十年是具身领域最玄的一道关。而 GEAR 近半年做的,是把这道关,变成一条流水线。
03
真机派的丧钟,是龙头自己敲响的
先说说"老叙事"是什么。
过去很多年,圈内的共识大致是:仿真再逼真也有 gap,机器人到了真实世界很大概率会翻车,所以真机数据才是王道,谁采的真机数据多谁就牛X。
这套逻辑撑起了全世界的具身数采行业,当下也是。
现在把 GEAR 近半年做迁移的几篇论文摆到一起。VIRAL(CVPR'26)、Doorman(CVPR'26)、CHIP、SONIC。我们发现它们用的几乎是同一条流水线。

这条流水线长这样:
这个配方,在 VIRAL 上跑一遍能做托盘搬运,在 Doorman 上跑一遍能开门,在 CHIP 上加个"顺应性"模块能做发力型任务。同一套模具,换个任务浇一次,就出一个能上真机的策略。
套娃了,属于是。方向已经很清楚了:
sim2real 正在从一门「一次性玄学攻关」,退化成一条「一个任务一个任务往外浇」制造配方。一个难题一旦变成模具,真机派手里「数据多」这张牌,就没那么值钱了。
不服?看数字。这些都来自各自的论文和项目页:
VIRAL:Unitree G1 人形机器人,训练用了 64 张 GPU,真机上能连续做 54 个 loco-manipulation 循环,托盘位置、桌子高度、桌布颜色、灯光、13 种以上物体全部随机,全程 zero-shot,不微调。
Doorman:纯 RGB 输入,zero-shot 开各种没见过的门。还有个关键的数字,它开门的速度比人类遥操作还快 31.7%(平均 7.15 秒)。尾巴上加的那段 GRPO 微调,把成功率又拉高了 20~30%。
CHIP:用"事后扰动"这个巧劲,不做数据增强就让机器人学会自适应调软硬(顺应度 0.05 到 0.5 连续可调),接上 GR00T N1.5 微调后,搬箱、擦写、开门这类发力型任务做到了 60~90% 成功率。
SONIC:整身控制的底座,参数从 1.2M 增到 42M,用了1 亿多帧动捕数据、700 小时、21000 GPU 时训出来,gamepad、VR、视频、文字、音乐都能驱动同一套动作。
把这几篇串起来看,会指向一个共同的赌注:未来不在真实世界里 scale,而是在仿真的"梦"里 scale 完,再迁移到真实世界。
这是NVIDIA给jim fan的底气。 GEAR 手里有 Isaac、有 Cosmos、有全世界最多的 GPU,Jim Fan 却亲口说真机数据是"烧人"。
真机派的丧钟,是龙头自己敲的。
还有DreamZero ,这篇连policy的步骤都想省掉。它的名字就是判断:World Action Models are Zero-shot Policies —— 世界模型本身就是策略。
它把一个视频扩散模型直接当策略用,比同类 VLA 泛化好 2 倍,14B 的模型优化到 7Hz 实时闭环,30 分钟就能迁到一个新本体上。这一波也直接开启了全世界 WAM 和 Ego-centric 研究的浪潮
这正好回到我们开头那个支点:在英伟达的图景里,低层策略是被"造"出来的下游产物,不是一个要死磕的独立课题。
04
但真机派不认
写到这里你大概能看出来,我们一直在讲 GEAR 一家,得请真机派出场了。
押注「真机数据 + 端到端大脑」的这波人,很强。而且他们内部正在发生一件更有意思的事,我们把三家摆出来:
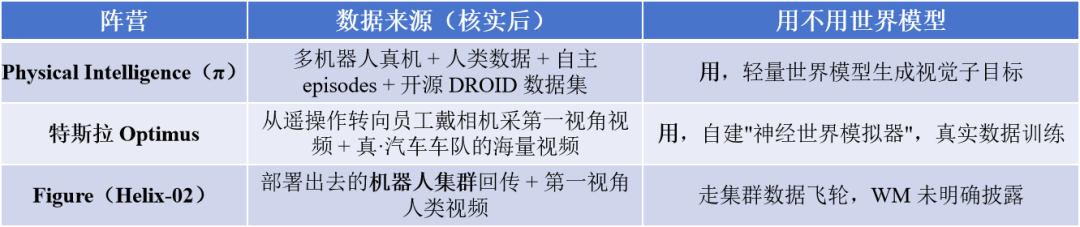
先说 π。它是公认的全球具身引领者,最新的 π0.7 今年 4 月发布。顺带吐槽一下,PI 已经快三个月没有新东西啦。

标题叫"a Steerable Model with Emergent Capabilities",主打组合泛化。没叠过衣服数据的新机器人也能完成任务。
古早的π0是大规模真机数据训练的,π0.7 官方并没有披露过具体数据量,只说数据来自多种机器人、人类数据、自主采集的片段和 DROID。
值得一提的细节是,π0.7 自己也装了一个世界模型。它在测试时用一个「轻量世界模型」生成合成的视觉子目标,来辅助泛化。
这就串起了一个反直觉的结论。你以为的战争是"NV用世界模型 vs 别人不用"。真相是:连最硬核的真机派 π,到了 π0.7 也主动靠拢世界模型。全行业其实已经默认了,世界模型是当下的技术解法之一。
那分歧到底在哪?在这台世界引擎烧的燃料从哪来:
GEAR / Jim Fan:造。 用 Cosmos 生成一个世界,赌自己能把它生成得够便宜、够真。
特斯拉:采。 它的"神经世界模拟器"(Ashok Elluswamy 去年 11 月在 ICCV 讲的)是用真实车队数据训练 出来的,当然还没有搬到具身上。注意,
π:混着来。 真机 + 人类数据 + 一个轻量 WM,走务实的中间路线。
其实还有Generalist、Gensis等很多公司,我们没有展开聊。感兴趣的朋友可以在评论区补充。
所以,我们想强调的是「不做大脑、去造仿真」这套排序,只能算英伟达的判断,不是唯一解。
05
英伟达不是真理,但值得关注
调研一圈下来,GEAR 押注的方向还是比较清晰的,是一台闭环的飞轮:造数据 → 造世界 → 迁到真机。
在英伟达的图景里,低层策略是这台飞轮的下游产物。谁掌握了飞轮,谁就能源源不断地"造"出大脑。
这是英伟达具身一号位这半年只有两三篇碰大脑、却拿十几篇修水管的原因。
他的赌注是:大脑的壁垒并不高,飞轮才是护城河。这件事我们觉得值得国内关注。
国内大量的注意力还在卷 VLA 和 WAM。如果 GEAR 这套赌注哪怕对了一半,那真正的护城河,可能就在这条没人愿意做的、又脏又累的数据-仿真-迁移供应链里。
当然,GEAR 的这套排序,是站在英伟达的肩膀上。
它是英伟达的判断,不是具身智能的普适真理。π 用真机数据也做出了组合泛化。押反面的人,未必就是错的。
Jim fan用 20 篇论文告诉你的,从来不是"大脑不重要"。他告诉你的,是他对"先做什么、后做什么"的判断。
让我们拭目以待。












