点击下方卡片,关注“具身智能之心”公众号
作者丨OrcaTeam
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
大模型的下一站,不能只会聊天,还要懂“世界会怎样变化”
过去几年,AI 的能力像开了倍速键。大语言模型学会了预测“下一个词”,于是有了会写代码、会做题、会对话的 ChatGPT、DeepSeek、Qwen。视频生成模型学会了预测“下一帧”,于是有了越来越逼真的图像和视频生成模型,例如 Seedance、Sora。具身模型学会了预测“下一个动作”,于是机械臂、轮式机器人、人形机器人开始能完成越来越复杂的任务。但一个问题仍然存在:
AI 真的理解世界了吗?
它是否知道,一个盖着盖子的杯子被推倒,和一个没有盖子的杯子被推倒,洒水的后果会有什么不同吗?
它是否知道,使用微波炉加热剩菜时,应该根据食物种类、分量和当前状态,调整合适的加热模式和时长吗?
它是否知道,在学会某个具身动作后,换到不同物体、不同位置、不同环境里,该动作会对世界状态造成怎样不同的改变吗?
这正是智源研究院 Orca 团队想回答的问题。
Orca 的目标不是专门做一个更会回答的大模型,也不是专门做一个更会画图的图像生成模型,也不是做一个模仿动作的机器人策略模型。它想做的是一件更底层的事:
让 AI 在“脑海中”形成一个表征,该表征是对当前世界状态的高度“浓缩”。基于该表征,AI 能够建模向前和向后世界状态的演变。
这就是Orca作为“多模态表征世界模型(Multimodal Latent World Model)”的核心哲学:The World is in Your Mind.
Orca: The World is in Your Mind.
项目主页:https://orca-wm.github.io/
技术报告:https://arxiv.org/abs/2606.30534
Orca:从预测“下一个具体模态输出”,走向预测“下一个世界状态”
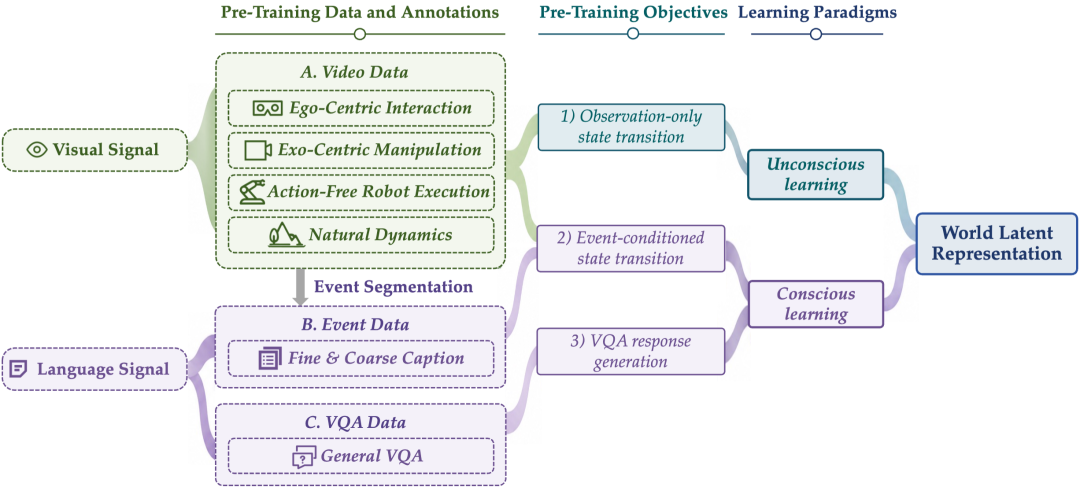
今天的大多数 AI 系统,都可以被理解为某种“Next X Prediction”的建模范式。以 Next Token Prediction 为建模中心的语言模型;以 Next Frame Prediction 为建模中心的图像、视频生成模型;以 Next Action Prediction 为建模中心的具身模型。但它们的建模方式都绑定在某一个或多个显式输出上。Orca 提出了另一种思路:不要只盯着显式输出,而是先学习世界本身的状态转移。
也就是说,模型看到一段视频、一张图、一个指令、一段事件描述后,Orca 不是简单地问“下一个词是什么”“下一帧长什么样”“下一步动作是什么”,而是先在内部形成一个统一的 World Latent Representation,即世界潜在表征空间。这个世界潜在表征空间就像 AI 的“脑海中的世界”,它把视觉、语言、事件、任务意图等世界上多模态的信号组织起来,学习物体如何运动、场景如何变化、动作会带来什么后果、事件之间有什么因果关系;当前状态如何走向未来状态;甚至在某些条件下,世界会不会朝另一个方向演化。

于是,语言、图像、动作都不再是孤立任务,而是同一个世界潜在表征空间的不同“出口”。想解释,就从表征空间读出文本。想预测未来画面,就从表征空间读出图像。想控制机器人,就从表征空间读出动作。
这就是 Orca 的核心变化:从 Next Token / Next Frame / Next Action,走向 Next State Prediction。
如何学习?
——两种学习方式:客观地看世界,主观地交互世界
Orca 把世界学习拆成了两条互补路径:无意识学习和有意识学习。通俗来讲,无意识学习负责积累世界客观经验,有意识学习负责把经验组织成可推理的因果结构。一个学“世界如何自然变化”,一个学“在特定条件和意图下,世界会如何变化”。
无意识学习:客观地看世界
人在学会语言之前,其实已经在大量观察世界了。婴儿会看到东西掉落,会看到人走动,会看到门被推开,会看到球滚到桌子下面。这些经验不是通过标签学习的,而是通过连续观察自然世界获得的。
Orca 的无意识学习也是如此。它从连续视频中学习自然、密集的状态转移:物体怎么移动,遮挡后是否还存在,接触关系如何变化,场景如何随时间演化。这部分不依赖人工标签,而是让模型自己从视频里吸收世界的动态规律。
简单说:给 AI 大量真实世界的视频,让它先学会“世界自己怎么动”。


有意识学习:主观地交互世界
只客观地看世界当然远远不够。因为人类真正强大的地方,在于我们会用语言、事件、因果和目的去组织世界。比如:
“今天要下雨,所以要带伞出门。”
“早高峰出门会堵车。”
“如果把腐烂的香蕉和葡萄放在一起,葡萄也会腐烂。”
“E=mc^2”....
这些不是简单的视觉变化,而是带有语义、意图和因果关系的状态转移。
Orca 的有意识学习,就是用语言描述的事件、任务指令和 VQA 问答,帮助模型学习稀疏但有具体意义的状态转移。


数据量有多大?
——12.5 万小时视频,1.6 亿条事件标注,且预训练持续 Scaling
为了让 Orca 真正学习世界,而不是只在小数据上“背答案”,团队构建了一套大规模预训练的存量数据。它包括:
12.5万小时视频数据,用于客观学习连续、密集的世界状态变化;
1.60亿条事件标注,用于主观学习语言约束下有具体意义的事件转移;
1150万条 VQA 数据,用于学习对世界状态的尝试理解。
这些数据覆盖了多种真实世界场景,包括:第一视角交互;第三视角物体操作;无动作标签的机器人执行视频;自然动态场景;事件级状态转移;通用 VQA 数据。这意味着,Orca 并不是只在某一种机器人数据、某一个图像任务或某一类问答数据上训练,而是在尽可能多的真实世界信号中学习一个统一的世界潜空间。

更重要的是,在当前版本中,Orca 只使用了约十分之一的存量数据。随着训练数据规模的增加,训练损失持续下降,表明训练范式的有效性。换句话说,这条路线仍有很大的 scaling 空间。
学习到的 latent 有效吗?
——一个 latent 表征空间,支持不同模态读出,对不同任务均有增益
Orca不仅要提出概念,还要回答一个本质问题:
如何验证学到的latent表征空间是有效的?它能否成为通用下游任务的接口?
因此,团队在backbone后加入轻量的模态readout模块,用于输出具体模态信息。在这一版本中,团队主要聚焦在三种 readout:
文本生成;
图像预测;
具身动作生成。
注意,这里并非是要刷每个任务的SOTA性能,而是期望回答上述问题。因此,团队的设置是:在下游任务后训练中,Orca的 backbone始终是冻结的,只利用LoRA或从头训练一个轻量的readout模块;下游任务全部都是zero-shot的OOD场景。

研究团队进行了探针实验,从训练过程中选出checkpoint,进行下游任务。结果表明随着预训练数据量的增加,latent对下游文本生成、图像预测和动作生成任务中的表现都持续提升,这表明该训练范式的可扩展能力。

Orca 在下游任务中和专有模型效果对比如何?
文本读出:Orca 更擅长状态转移的理解和动态运动的推理
在文本生成和视觉问答评测中,Orca 对比了多类世界模型和视觉语言模型,包括 V-JEPA、Emu3、Qwen3.5、Gemma、MiniCPM-V、DeepSeek-VL2 等。在 4B 规模下,Orca 在多项综合评测中取得了更高平均表现。

尤其值得注意的是,Orca 的提升主要集中在 状态转移、事件演化 等与世界变化密切相关的维度,说明优势更可能来自状态转移建模,而非泛泛的视觉问答能力。这说明,Orca 学到的不只是画面表层信息,而是更接近“世界如何变化”的内部规律。

图像读出:Orca 不做“画家”,而是现实世界的“预测家”
图像读出是 Orca 最容易被大众感受到的能力之一,但它的核心并不是“画一张漂亮图”,而是给定当前图像和指令,预测真实世界交互后的下一状态。
在真实场景交互基准 PRICE 上,传统图像生成模型如 FLUX 2、OmniGen2 虽然能生成 看起来合理 的精美图像,但在真实交互预测中常常出现无关物体/人手凭空出现、不符合物理常识的幻觉、忽略真实场景的物体刻板印象、以及指令控制失效等问题:

相比之下,Orca 能更好地保持机器人形态、场景一致性、物体关系和指令约束,生成更符合真实物理过程的未来状态。这表明 Orca 学习到的世界表征不仅能够生成视觉上合理的图像,更包含了对 状态转换、物体交互和 物理规律的有效建模能力,因此它不是一个单纯的“图像画家”,而是一个面向真实世界交互的“物理预测家”。
动作读出:Orca 没有在预训练中看动作标签,也能帮助机器人更好泛化
在具身动作生成任务上,研究团队发现 Orca 的预训练过程没有使用任何带动作标签,但其学习到的世界表征依然能够有效迁移到机器人动作生成中。值得注意的是,在动作读出中, Orca 主体保持冻结,仅接入一个与基线相同、从零训练的 Action Expert,在每个任务上仅使用域内 200 条轨迹进行后训练,机器人就已经能够完成多个OOD双臂操作任务。
gif1
实验结果显示,在环境 OOD 和物体 OOD 设置下,Orca 不仅在成功率和整体推进效果上优于 V-JEPA 2.1、Qwen3.5 等视觉/语言表征基线,也在执行过程中表现出更好的持续推进能力和偏差后的恢复能力,整体上达到经过大规模机器人数据预训练后 π0.5 的水平。
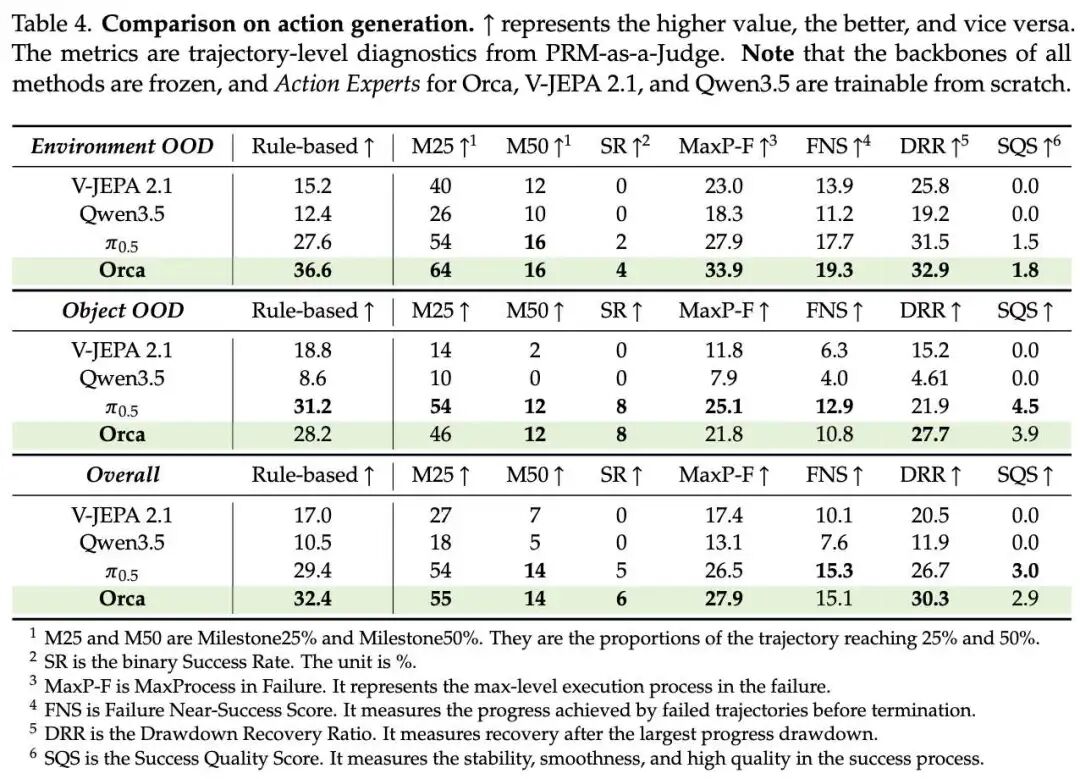

这说明,Orca 并不是直接从视频中学习“怎么控制机器人”,而是先学习“世界如何变化”;当这种世界表征再通过少量动作数据连接到机器人控制时,就有可能显著缓解具身智能长期面临的机器人数据稀缺和泛化困难问题。
这也是 Orca 对具身智能最有想象力的地方:Orca 希望让机器人先具备类似成年人理解世界变化的基础能力,再用少量示范激活具体动作技能,而不是像从零教一个三岁孩子打螺丝一样,完全依赖高成本的动作试错。
为什么 Orca 要同时“看世界、懂事件、会语言”?
为了验证 Orca 的能力究竟来自哪里,团队进一步做了消融实验:分别移除无意识状态转移、有意识事件转移和 VQA 问答生成三类训练目标,观察文本、图像、动作三种 readout 的变化。

结果显示,三类目标缺一不可,但分工不同:VQA 主要保留语言接口和语义理解能力;基于连续视频的无意识状态转移,为模型提供密集的自然动力学经验,对机器人动作读出尤其重要;而有意识事件转移,则把“语言/事件条件”和“视觉状态变化”对齐,是图像预测能够按照指令生成未来状态的关键。只有三者共同训练时,Orca 才能在文本、图像和动作三个方向上取得最均衡的表现,整体平均分最高。这说明 Orca 并不是简单依赖某一个监督信号,而是通过自然世界动态、事件语义条件和语言监督的共同约束,逐步塑造一个更稳定、更通用的世界潜空间。
Orca 使用众智 FlagOS 多芯片开源统一技术栈进行大规模分布式训练,相较具身社区 StarVLA 框架训练吞吐量提高了4.4倍。
Orca 是智源研究院通向通用世界基础模型路径上的一次早期探索。团队成员也在技术报告中客观、真实地讨论了当前 Orca 的边界:
它目前主要从视觉和语言信号中学习世界状态,而真实世界的变化还广泛存在于声音、触觉、力觉、光照、本体感受等更多模态中;
它的视觉状态监督仍依赖于已有视觉编码器空间,而真正的世界基础模型应当从多源世界信号中原生学习统一的状态空间;
受限于算力和模型规模,当前实验主要在 0.8B 和 4B 规模上展开,还不足以充分吸收更大规模的数据、知识和模态;
同时,现有图像预测评测基准、短时状态转移监督、下游读出接口和损失设计,也都还只是迈向通用世界建模的初步尝试。
但也正因为这些限制,Orca 的意义并不在于宣称一个已经完成的答案,而在于提出了一条值得继续探索的路线。未来,随着更多模态信号的接入、更大规模原生世界模型的训练、更系统的状态转移评测体系,以及“数据生成—数据筛选—模型训练—能力跃迁”的自进化闭环逐步建立,Orca 所代表的世界学习范式有可能从具身智能进一步走向科学发现、复杂系统建模乃至更广阔的认知边界。它是多模态表征世界模型的一个早期版本,但有可能成为通用世界基础模型的一块重要基石。
推荐阅读 :