点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
作者供稿直发 | 编辑:3D视觉工坊
【导语】 通用机器人的终极考验,在于能否在复杂多变的物理世界中实现“边走边操作”(Mobile Manipulation)。今日,备受瞩目的具身智能最新成果 ABot-M0.5 正式发布。本文工作由高德地图 AMap-CV 实验室完成,是 ABot-Manipulation 系列继 ABot-M0 之后的又一重要续作。作为全新的统一世界-动作模型(Unified World Action Model, WAM),ABot-M0.5 以前所未有的架构创新,一举攻克了移动操作中“预测与控制脱节”的行业痛点,在 RoboCasa365、RoboTwin 2.0 等顶级基准测试中全面超越 π0、GR00T-N1.5 等知名基线,刷新了长程任务与细粒度控制的 SOTA 纪录。
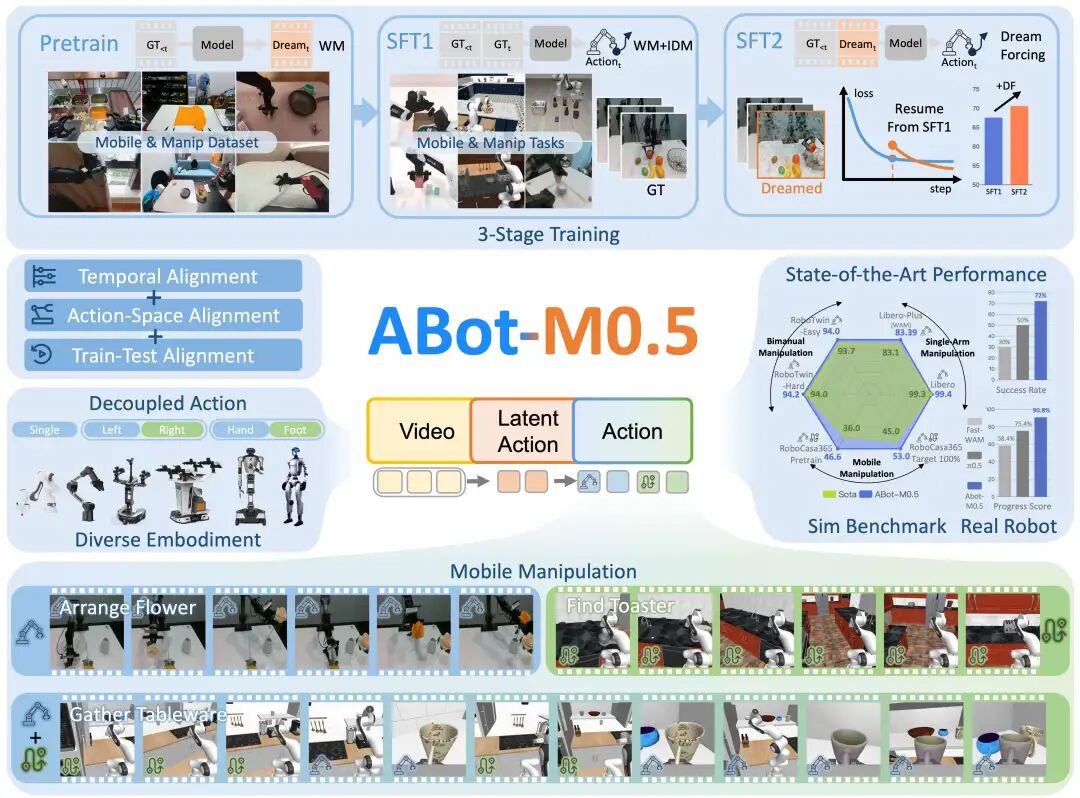 图1:ABot-M0.5 统一移动操作的世界-动作模型(WAM)整体架构与效果示意
图1:ABot-M0.5 统一移动操作的世界-动作模型(WAM)整体架构与效果示意
🚨 行业痛点:当“世界模型”遇上“移动操作”
近年来,视觉-语言-动作模型(VLA)在机械臂操作中表现出色,但它们本质上是“反应式”的,缺乏对物理世界演化的显式预测能力。为了赋予机器人“预见未来”的能力,研究界引入了世界动作模型(WAM)。
然而,当 WAM 直接应用于移动操作时,却遭遇了严重的水土不服,暴露出三大结构性瓶颈:
粒度错位:宏观的视频预测过于粗糙,无法直接映射到微观的电机级精细控制。 动作耦合:底盘的“移动”与机械臂的“操作”频率和物理特性截然不同,混合预测会导致严重的梯度干扰。 训练-推理鸿沟:传统的训练方式(Teacher Forcing)让模型在“完美”的 ground-truth 视频下学习,一旦在真实自回归推理中产生微小误差,就会引发灾难性的误差累积。
 图2:ABot-M0.5 模型架构示意
图2:ABot-M0.5 模型架构示意
💡 核心突破:ABot-M0.5 的“三大法宝”
为了彻底打破这些瓶颈,ABot-M0.5 基于 Wan2.2 视频扩散骨干网络,提出了一套系统性的工程解法,实现了从“未来预测”到“动作抽象”再到“硬件控制”的三级火箭式级联:
1. 中间潜在动作(Intermediate Latent Actions):搭建时空桥梁 ABot-M0.5 创造性地引入了“帧级潜在动作”作为中间层。它就像一位“翻译官”,将粗粒度的视频潜在状态转化为与具身硬件无关的运动意图,完美弥合了世界模型与底层控制之间的时间粒度鸿沟。
 图2:中间潜在动作架构示意
图2:中间潜在动作架构示意
2. 双层混合 Transformer(Dual-level MoT):动作空间的“分轨”解耦 针对移动和操作的异质性,模型设计了独特的 D-MoT 架构。在模态层面,为视频、潜在动作和可执行动作分配独立的投影与输出头;在动作层面,将底盘移动(Mobility)和机械臂操作(Manipulation)强制分配到不同的 Transformer 子塔中。这种“分轨”设计彻底消除了高频操作信号对低频移动信号的干扰,让机器人“走”得更稳,“抓”得更准。
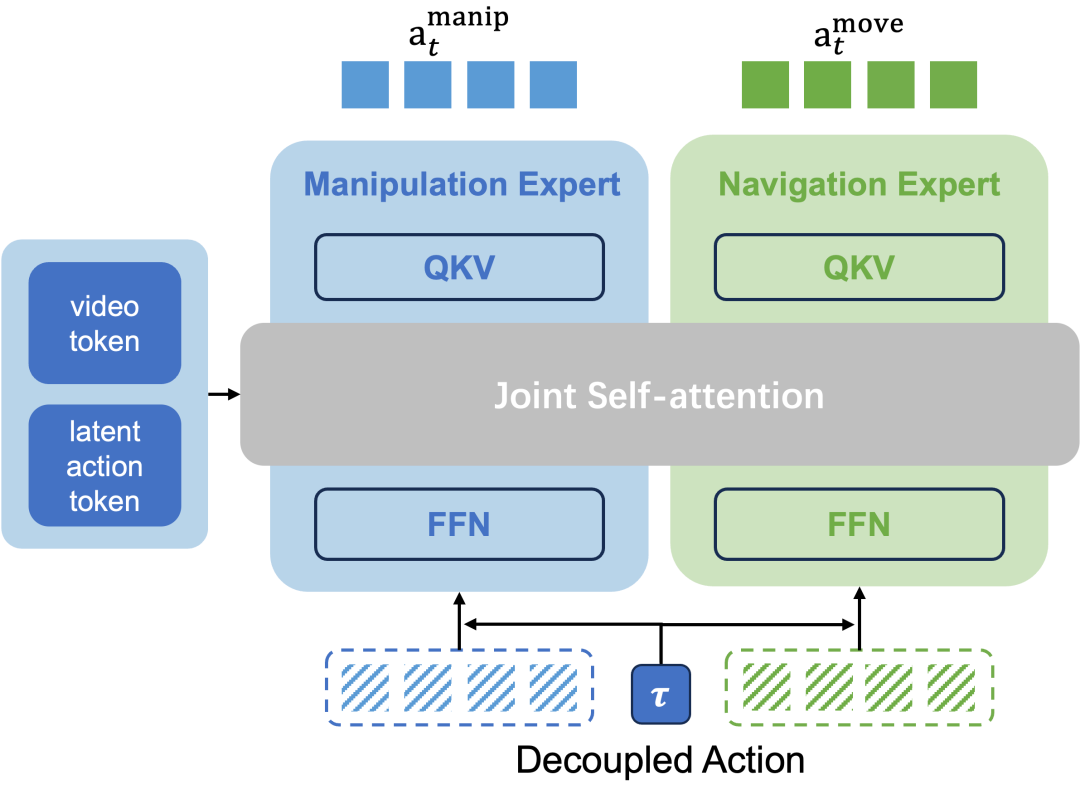 图3:双层混合 Transformer(D-MoT)结构
图3:双层混合 Transformer(D-MoT)结构
3. 梦境强制(Dream Forcing):打破温室,直面真实 这是 ABot-M0.5 最具启发性的训练范式创新。它摒弃了依赖真实视频帧的传统训练,转而使用模型自己“做梦”预测出的视频(哪怕带有瑕疵)来训练动作预测器。这种机制让模型在训练阶段就习惯了自回归推理中的误差,从根本上解决了长程任务中的误差累积问题,大幅提升了部署鲁棒性。
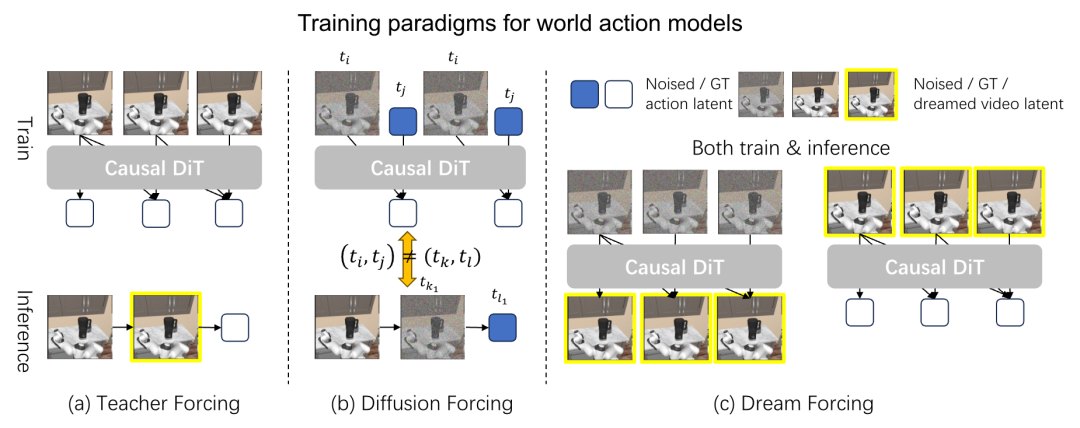 图4:Dream Forcing 训练机制示意
图4:Dream Forcing 训练机制示意
 图5:Dream Forcing 训练机制示意(续)
图5:Dream Forcing 训练机制示意(续)
🔋 从“预训练”到“真机部署”:三阶段训练与可视化揭秘
ABot-M0.5 的强悍性能,源于其精心设计的三阶段渐进式训练范式,让模型真正完成了从“看懂世界”到“掌控物理”的蜕变:
世界模型预训练(World Model Pre-training):模型首先在海量视频数据中进行预训练,学习物理世界的时空演化规律,构建出强大的“物理直觉”; 潜在动作预训练(Latent Action Pre-training):通过自监督学习提取帧级运动表征,将宏观的视频变化转化为微观的动作意图; 渐进式监督微调(Progressive SFT):模型先基于真实视频帧进行联合微调,随后无缝切换至“梦境强制”模式,让模型在自己预测的未来画面中训练动作,彻底抹平训练与推理的鸿沟。
 图6:注意力掩码可视化
图6:注意力掩码可视化
在可视化方面,论文展示的注意力热力图(Attention Maps) 直观印证了这一进化过程:从预训练初期的“四处张望”,到微调后精准锁定任务核心区域,模型的“视觉焦点”变得极其敏锐。同时,在 RoboCasa365 上的生成轨迹可视化更是惊艳,模型“梦境”中推演的移动与操作画面(通过黄绿双色清晰区分底盘移动与机械臂操作)与真实物理规律高度契合,真正做到了“所思即所见”。
 图7:预训练注意力热力图效果对比
图7:预训练注意力热力图效果对比
🏆 战绩斐然:全面制霸各大顶级 Benchmark
ABot-M0.5 的架构优势在严苛的实验中得到了充分验证:
移动操作(RoboCasa365):在极具挑战的家庭场景长程任务中,ABot-M0.5 取得了 40.3% 的平均成功率,大幅领先 GR00T-N1.5 (23.9%)、RLDX-1 (36.0%) 和 Qwen-RobotManip (35.9%)。在额外加了压缩记忆机制后(ABot-M0.6),甚至高达**46.6%**,超越其他模型10+%的准确率。
 图12:RoboCasa365 移动操作基准测试结果
图12:RoboCasa365 移动操作基准测试结果
精细操作(RoboTwin 2.0 / LIBERO):不仅在移动场景称王,在纯机械臂操作任务中同样登顶。在 RoboTwin 2.0 中斩获 94.1% 的平均分。
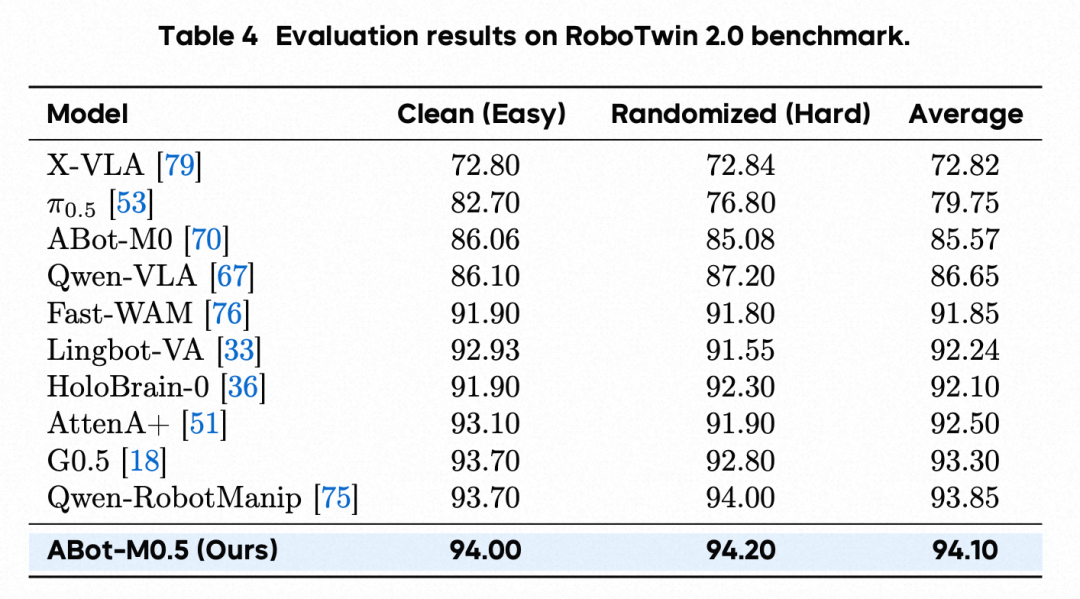 图13:RoboTwin 2.0 精细操作基准测试结果
图13:RoboTwin 2.0 精细操作基准测试结果
在Libero 中也斩获 99.4% 的平均分,超越 π0、Gr00t、Qwen-RobotManip等一众强手。
 图14:LIBERO 基准测试结果对比
图14:LIBERO 基准测试结果对比
文章也做了消融实验证实了“中间潜在动作”、“动作解耦”和“Dream Forcing”缺一不可,共同构筑了模型强大的性能基石。
真机效果更是令人振奋!在极具挑战的物理部署中,ABot-M0.5 展现了极高的数据效率——仅需 50 条真实演示数据,部署于 Agilex Piper 机械臂后,在要求极高空间精度的“圆柱体插入”精细任务中斩获 70% 成功率(远超π0.5的50%和FastWAM的30%);在“整理水果”等长程多步任务中更是达到了 80% 的惊人成功率。它彻底告别了传统模型在长程任务中“走一步错一步”的尴尬,证明了其从虚拟梦境走向物理现实的强大泛化能力。
 图8:真实机器人部署效果
图8:真实机器人部署效果

图9:花瓶放置

图10:整理水果

图11:挂杯
🚀 结语:从“感知”到“预见”的范式跃迁
ABot-M0.5 的发布证明了一个重要事实:通用具身智能的飞跃,不仅依赖于数据规模的暴力堆叠,更源于对“预测-抽象-控制”底层逻辑的系统性重构。
通过让机器人学会在“梦境”中推演未来,并在现实中精准执行,ABot-M0.5 正在为我们推开真正“全能管家”时代的大门。
🔗 论文全称:ABot-M0.5: Unified Mobility-and-Manipulation World Action Model
🔗 论文链接:https://arxiv.org/html/2607.00678v1
🔗 Github链接:https://github.com/amap-cvlab/ABot-Manipulation/tree/main
注:代码与模型权重即将开源,敬请期待!
本文仅做学术分享,如有侵权,请联系删文。
。




添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。










