点击下方卡片,关注【Xbotics具身智能实验室】公众号
你想要的这里都有~~
前三课我们把数据准备好,把 ACT 模型跑起来,看着训练曲线一路下降。
到了这一步,很多同学会产生一个美好的错觉:loss 降了,模型就该会干活了。
现实往往当头一棒——机械臂抖得像帕金森,夹爪还没碰到东西就闭了,碗被碰倒,箱子没封上,双臂各动各的像在打架。
在机器人学习里,“loss 很低”和“任务成功”之间,隔着一条巨大的鸿沟。
第 4 课要解决的,就是怎么跨过这条沟。你得学会三件事:看懂训练效果、读懂失败视频、把失败翻译成下一轮该干什么。
一、先拿个小任务练手:把碗放到盘子上
GHRC Walker S2 是咱们的主线任务,但它太“重”了——要完整评测一次,得启动 Isaac Sim 仿真环境,让策略真刀真枪跑一遍。不适合在直播课里当场演示。
所以我们先换个轻量级的练手场:LIBERO。
这是一个标准的桌面操作仿真环境,自带任务成功判定。训练时就能边训边测,直接看到成功率和执行视频。用它来学“怎么看训练效果”,最方便不过。
我们选的任务很简单:机械臂把碗放到盘子上。

听起来平平无奇,但这个小任务里藏着所有机器人操作的核心要素——接近、抓取、移动、放置、接触。不长,但够用。
训练命令和第 3 课一模一样,策略还是 ACT。唯一的区别是挂上了 LIBERO 仿真环境,所以训练过程中能同时看到三样东西:
训练 loss 有没有降?
成功率有没有升?
失败视频里到底发生了什么?
这三样凑齐了,才叫真正看懂一次训练。
二、第一眼:loss 降了,别高兴太早
训练开始后,你会看到 train/loss 从高处快速跌落,然后慢慢趋稳。动作重建误差也从 0.35 一路降到 0.13。
这说明模型确实在学习——“预测动作”和“真实动作”越来越像了。
但这里必须敲黑板:loss 低只说明“学进去了”,不说明“学会了”。

为什么?因为机器人不是在做离线选择题,而是在真实环境里一步步行动。图像分类认错一张图,不会影响下一张图长什么样。但机器人动作只要偏一点,下一帧看到的世界就变了——它进入了一个训练数据里从没见过的状态,在陌生状态里继续猜动作,更容易错,错了又导致下一帧更偏。雪球就这么滚起来了。
所以 loss 低是必要条件,绝对不是充分条件。你还得看成功率。
三、第二眼:成功率才是真成绩单
LIBERO 的好处来了:它有仿真环境和自动成功判定,训练过程中就能直接看到 eval/pc_success——评测成功率。

这时候你要同时盯三个东西:
train/loss:模型有没有在数据上学进去?
eval/pc_success:模型在仿真里能不能把任务做成?
eval/video:模型到底是怎么做的?成功长啥样?失败卡在哪?
只看 loss,容易被骗——loss 很低但机械臂总是抓偏,说明问题不在“拟合数据”,而在动作时序、目标位姿或者数据覆盖。
只看成功率,也不够——它只告诉你“成了几次”,不告诉你“为什么没成的那几次没成”。
真正的训练效果分析,一定是 loss 曲线 + 成功率曲线 + rollout 视频,三者一起看。
四、第三眼:盯着失败视频问五个问题
成功率告诉你“多少成”,但要改进模型,你得知道“剩下那些为什么不成”。
这只能靠看视频。而且不能泛泛地说“模型不行”“再训训”,要带着问题看。我们固定五个问题:
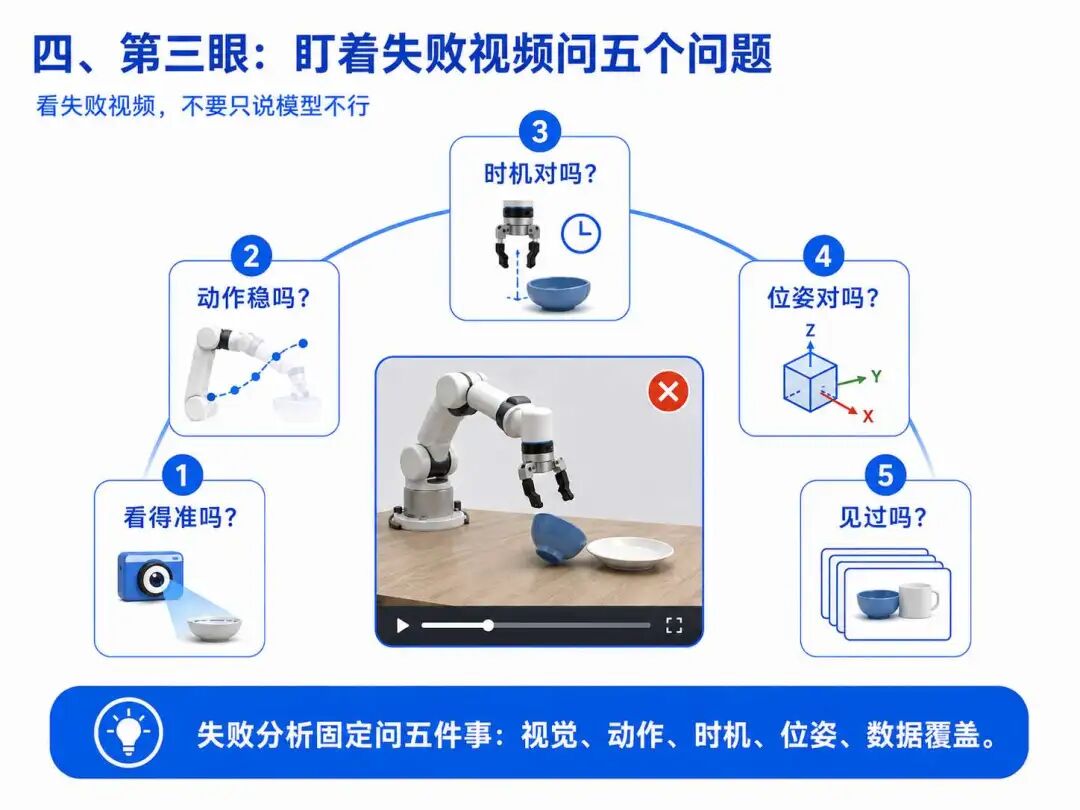
第一,看得准吗?目标在视野里吗?画面清不清晰?有没有被挡住?如果一开始视觉输入就有问题,后面动作再怎么调都是错的。
第二,动作稳吗?轨迹是平滑伸过去,还是一路抖、来回蹭、卡顿?靠近目标时开始乱抖?动作块之间有明显断点?
第三,时机对吗?夹爪是不是还没到位就闭合?是不是碰倒碗之后才闭?抬手是不是太早,东西还没夹稳?
第四,位姿对吗?末端到没到正确位置?差几厘米没够到?抓取点偏到边缘了?放置时没对准?
第五,见过吗?这个摆法、这个光照、这个起始位置,训练数据里出现过吗?如果没覆盖过,模型就是在“硬猜”。
很多失败,不是模型结构不够复杂,而是数据根本没覆盖到当前情况。
这五个问题,就是咱们后面的失败分析框架:视觉、动作、时机、目标位姿、数据覆盖。
五、把分析框架固定下来,随时可用
盯视频是个体力活,但失败类型不是无限多的。把五个问题固定下来,就得到一张失败归因表:

失败类别 | 在问什么 | 典型表现 |
视觉 | 模型看清目标了吗? | 目标被遮挡、相机糊、认错物体 |
动作 | 轨迹质量如何? | 抖动、卡顿、来回蹭、不连贯 |
时机 | 关键动作的时刻对吗? | 夹爪闭合过早/过晚,抬手太快 |
目标位姿 | 末端到没到正确位置? | 差几厘米够不到、角度偏、放歪 |
数据覆盖 | 这种情况训练见过吗? | 新摆位、新光照下失灵 |
用法很简单:看一遍失败视频,把现象归到某一类或几类里。
比如“夹爪还没碰到碗就闭合了”——这是时机问题。“靠近碗时轨迹一直在抖”——动作问题。“碗在相机里只露出一半”——视觉问题。“换个初始摆位就完全失败”——数据覆盖问题。
只有先说清楚“失败属于哪一类”,才谈得上对症下药。
归到数据覆盖,就该补数据,而不是盲目加训练步数。归到时机,就要看夹爪通道的预测时序,而不是只盯末端轨迹。归到视觉,就要调相机位置和光照,而不是只调模型参数。
一次失败往往不止一类原因。比如“目标被遮挡”导致“位姿估计偏”,再导致“抓偏”。这时候要找主因——最早出问题的那一环,通常会把后面整个链路都带歪。
六、把这套框架搬到 Walker S2 上
LIBERO 是练手场,GHRC Walker S2 才是主场。

好消息是,分析框架完全可以直接迁移。但 Walker S2 是人形双臂、四目相机、接触丰富的仿真任务,比单臂 LIBERO 多了几个需要专门盯的点。
第一件事:四目视角要配合看。
Walker S2 有四路相机:头部左右双目、左腕相机、右腕相机。头部双目看全局——站位对不对、目标在不在工作区、双臂有没有互相干扰。腕部相机看抓取细节——末端对准了没有、夹爪有没有夹到位、是不是差几毫米没够到。
很多失败在头部视角里根本看不出来,因为目标太小、太远、被挡住了。但切换到腕部相机,一眼就能看出夹爪偏了。诊断抓取类失败,优先调腕部视角。
第二件事:双臂协调。
Walker S2 很多任务不是单手操作,而是双臂协同。纸箱封装要两只手一起合上箱盖,搬运要同时夹住物体。
这比单臂多出一类问题:两只手的时序和空间配合对不对?一只手到位了另一只还没动?两臂有没有抢同一个空间?轨迹有没有碰撞?
建议分析时把视频拆开:先看左臂,再看右臂,最后看两臂之间的相对时序。很多时候单看一只手没问题,但两只手合起来就错了。
第三件事:物体状态和接触物理。
仿真里的物体是有物理的——位置、姿态、摩擦、接触。抓取稳不稳,很多时候要靠视频判断。
特别要留意两点:一是每个回合开始时物体有没有复位干净,上一轮的残留可能影响下一轮;二是夹爪和工件之间的接触效果——是不是夹到了又掉,抓取点是不是靠近重心,抬起时有没有打滑。
一句话总结:Walker S2 的分析 = 五类失败框架 + 四目配合 + 双臂时序 + 接触/复位问题。框架不变,但盯的点更细。
七、ACT 之外,还有两条路
分析多了你会发现,有些失败不是“训练不够”,而是 ACT 这条路线本身的局限。
回想第 3 课,ACT 用隐变量 z 来表达“这次用哪种操作风格”。训练时能表达多种风格,但推理时为了方便,通常直接取 z=0——永远走最主流的那种做法。如果主流做法在某个场景下被挡住了,模型就可能卡住。
如果想更自然地表达“同一个场景下多种合理做法”,就需要另一类真正的生成式动作模型。当前主流的有两条路线:

Diffusion Policy:像拼图一样“去噪”出动作。
直觉来自图像生成里的扩散模型。先把真实动作序列一点点加噪声,搅成一团完全看不清的纯噪声。然后训练神经网络,学会从噪声里一步步去掉噪声,还原出干净的动作序列。
用到机器人上,就是把相机画面、机器人状态作为条件输入,让模型从纯噪声动作开始,反复去噪,最终生成一段可执行动作。好处是多模态表达能力强,每次从不同噪声出发能生成不同但合理的结果。代价是慢——输出一段动作往往要跑 10 到 100 步去噪。
Flow Matching:让简单分布“流”向动作分布。
这条路比 Diffusion 更直接。不绕加噪去噪的弯,而是直接学习一个“速度场”——给定一团简单噪声,学习每个点在每个时刻该往哪里走、走多快,让它沿着一条连续路径流到目标动作分布上。
好处是路径更规整,步数更少,往往只需要个位数到十几步。比 ACT 慢,比 Diffusion 快,同时保留多模态能力。
把三条路线连起来看:
ACT:一把出,最快,但推理多模态弱
Diffusion Policy:多步去噪,多模态强,但最慢
Flow Matching:连续流,保留多模态,同时减少步数
它们都在解决同一个核心问题:同一个观测下,怎么生成一段合理动作?区别在于怎么生成、多快、能不能表达多个合理模式。
八、下一课预告:收束整个线上阶段
第 4 课把“训练能跑”升级成了“看懂效果、写出改进”。
我们先用 LIBERO 小样例学会了怎么看 loss、成功率和 rollout 视频,然后把失败归因抽象成五类框架:视觉、动作、时机、目标位姿、数据覆盖。接着把这套框架搬到 Walker S2,补充了四目视角、双臂协调和接触物理这些双足人形机器人的特有问题。
还速览了 ACT 之外的两条生成式动作路线:Diffusion Policy 和 Flow Matching,理解了它们各自的优势和代价。
最关键的是,学会了分清回放和推理,学会了把失败写成可执行的优化建议。
第 5 课会收束整个线上阶段。我们会复盘 ACT 从数据到训练到推理到分析的完整闭环,对比 ACT、Pi0、SmolVLA、GR00T 等大模型路线,最后把五次课的结果整理成 Walker S2 项目报告。
到那时,你应该能回答一个更完整的问题:
我不光知道模型怎么训练,也知道它怎么评测、怎么失败、怎么改进,以及如何把一次训练整理成可展示的具身智能项目。
真正的机器人训练,从来不是跑通命令那么简单。它是一场围绕数据、模型、动作、环境和失败案例的持续迭代。第 4 课学会的,就是看懂这场迭代里的每一个信号。

-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀










