论文题目:MMSearch-R1: Incentivizing LMMs to Search
论文地址:https://arxiv.org/pdf/2506.20670
代码地址:https://github.com/EvolvingLMMs-Lab/multimodal-search-r1

创新点
不同于 RAG 的固定检索流程或提示工程驱动的代理,MMSearch-R1 用 GRPO 强化学习直接优化大模型何时、如何、如何总结地调用外部搜索工具,实现了“按需搜索”而非盲目检索。
通过让模型在 8 次 rollout 中自我验证,无需人工标注即可判定一道 VQA 题是“可内部回答”还是“需外部搜索”,并细分为图像搜索、文本搜索或混合搜索三类,从而自动得到搜索-免搜索均衡的 5 k 训练集(FVQA-train)。
在奖励函数中引入搜索惩罚因子:答对且未搜索得满分,答对但搜索过则打折。该机制鼓励模型优先使用内部知识,仅在必要时才触发搜索,显著降低 30 % 以上的搜索调用。
方法
本文提出 MMSearch-R1,以 Qwen2.5-VL-7B 为骨干,在 veRL 框架内采用改进的 GRPO 强化学习算法,直接在大模型参数中注入“何时搜索、搜索什么、如何利用搜索结果”的策略。训练时,模型每步采样 512 条(图像、问题、答案)三元组,每条做 8 条 rollout,最多三轮对话、两轮搜索;奖励由“答对得分×搜索惩罚”与格式分加权构成,搜索惩罚促使模型优先用内部知识。为此,作者先基于 MetaCLIP 概念分布与 InfoSeek 构建 FVQA 语料,利用自验证策略将样本自动标记为搜索-免搜索两类,形成 5 k 均衡训练集;同时部署 SerpAPI 图像搜索、SerpAPI+Jina Reader+Qwen3-32B 文本搜索两条真实网络工具链,配以三级缓存、限流与失败重试机制,供模型在 rollout 中按需调用。推理阶段,模型先自评知识边界,再决定是否触发图像或文本搜索并生成查询,直至给出最终答案。
MMSearch-R1 整体流程示意

本图用一张“VIPER 月球车”的真实照片作为故事起点,像一部三幕剧一样把 MMSearch-R1 的完整搜索链路拍成连续画面:第一幕,模型盯着图片发现“我知道这是月球车,但完全不知道它哪天被取消”,于是先打上
GRPO 训练与多轮搜索交互流程

本图上半部分是GRPO 强化学习引擎的“后台机房”——左侧画着 Policy Model(πθ)与 Reference Model(πref)两条并行线,中间用 Group Computation 模块把 8 条 rollout 的奖励做归一化,再经 KL 约束后回传梯度;右侧 Reward Model 把“答对得分×搜索惩罚”注入训练闭环,直观呈现“搜索越少、奖励越高”的优化目标。整个交互链条像放电影一样逐帧展开,把“何时搜、搜什么、怎么用”的决策逻辑完全可视化,让人一眼看懂 MMSearch-R1 是如何在真实互联网环境里边想边搜、边搜边想的。
FVQA 数据集构造全景

本图(a) 自动化流程展示如何从 MetaCLIP 概念、网络图-文对、GPT-4o 生成 QA;(b) 知识分类树状图覆盖艺术、人物、事件等八大领域;(c) 总览图把自动语料、人工标注、搜索-免搜索平衡采样串联成最终 5 k 训练集与 1.8 k 测试集,一目了然地说明了数据来源与配比。
实验
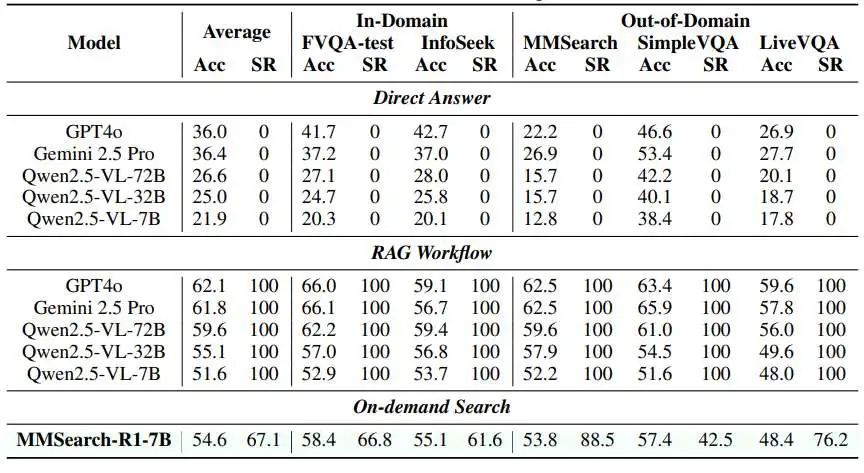
本表把同一规模(7B)的 MMSearch-R1 与闭源大杯 GPT-4o、Gemini 2.5 Pro 以及开源 7B→72B 系列在五个基准上的“答对率 vs 搜索率”一次性摊开:横向看,RAG 工作流把搜索预算打满(100%),换来 51.6–66.0% 的准确率,却造成大量冗余调用;而 MMSearch-R1 在保持 54.6–59.5% 平均准确率的同时,将搜索率压到 67.1–88.5%,在 LiveVQA 这类新数据上甚至只用 42.5% 的搜索步就能逼平或反超 32B-RAG,说明强化学习让模型真正学会了“能答就不搜、答不出再搜”,用更少的搜索换取了与更大模型相当的表现,验证了“按需搜索”策略的实用价值。
-- END --

关注“学姐带你玩AI”公众号,回复“多模态检索”
领取多模态检索创新方案合集+开源代码