摘要
Abstract
行为基础模型(BFM)通过大规模行为数据预训练,实现人形机器人全身控制的跨任务泛化能力突破。传统控制器依赖人工调参或特定任务训练,泛化性差且成本高昂;BFM则学习可复用的基础技能和行为先验,支持零样本或快速适应新场景。
香港理工大学等机构的综述首次系统分类三类BFM算法:目标导向学习、内在奖励驱动探索、前后向表征学习。

项目主页:
https://github.com/yuanmingqi/awesome-bfm-papers
人形机器人作为用于复杂运动控制、人机交互和通用物理智能的多功能平台,正受到前所未有的关注。然而,由于其复杂的动力学、欠驱动和多样化的任务需求,实现高效的人形机器人全身控制 (Whole-Body Control,WBC) 仍然是一项根本性的挑战。
虽然基于强化学习等方法的控制器在特定任务中展现出优越的性能,但它们往往只具有有限的泛化性能,在面向新场景时需要进行复杂且成本高昂的再训练。
为了突破这些限制,行为基础模型(Behavior Foundation Model,BFM)应运而生,它利用大规模预训练来学习可重用的原始技能和广泛的行为先验,从而能够零样本或快速适应各种下游任务。
来自香港理工大学、逐际动力、东方理工大学、香港大学和EPFL等知名机构的研究者合作完成题为“A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots”的长文综述,首次聚焦行为基础模型在人形机器人全身控制中的应用。
该综述系统性地梳理了当前BFM的最新进展,从预训练(Pre-training)和任务适配(Adaptation)两个角度对当前各类BFM算法提供了全面的分类体系,并且结合其他基础模型(例如大语言模型、大规模视觉模型)的发展动向对BFM的未来趋势和研究机遇进行了展望,有望对该领域的研究者和从业者产生引导作用。
人型全身控制:从 “定制化” 到 “通用化”
文章将人形全身控制算法的演化总结为下图中的三个阶段:

基于模型的控制器(Model-based Controller):
以MPC、WBOSC等算法为代表,面向基础的人形全身控制任务,极度依赖物理模型并且需要复杂的人工设计与调校,且鲁棒性较低。
基于学习的,面向特定任务的控制器(Learning-based and Task-specific Controller):
以强化学习、模仿学习等方法为代表,面向特定的、复杂的人形全身控制任务,支持灵活的任务设计,但跨任务的泛化性较差。
行为基础模型(Behavior Foundation Model):
在大规模人类行为数据集上进行预训练得到的模型,习得大量可复用的基础技能以及广泛的行为先验,具备快速适应不同任务的能力。
什么是行为基础模型?
“行为基础模型”这一术语首次出现在“Fast Imitation via Behavior Foundation Models”一文中,作者基于无监督强化学习+前后向表征学习(Forward-backward Representation Learning)方法构建BFM,实现了对多种模仿学习规则的支持,包括行为克隆(Behavioral Cloning)、特征匹配(feature matching)、基于奖励/目标的归纳(reward/goal-based reductions)。
该工作也被ICLR2024接收为Spotlight文章。后续的其他工作则将BFM定义为:“对于一个给定的马尔科夫过程,行为基础模型是一类以无监督强化学习方法训练得到的智能体。在测试时,可以为指定的大量奖励函数生成近似最优的策略,而无需额外的学习或规划”。

该综述将BFM的定义拓展为:“一类特殊的基础模型,旨在控制智能体在动态环境中的行为。BFM 植根于通用基础模型(例如 GPT-4、CLIP 和 SAM)的原理,使用大规模行为数据(例如轨迹、人类演示或智能体与环境的交互)进行预训练,从而对广泛的行为模式进行编码,而非局限于单任务场景。这一特性确保了模型能够轻松地对不同任务、情境或环境进行泛化,展现出灵活且自适应的行为生成能力。”
主要算法分类
文章将当前构建BFM的方法分为三类:目标导向的学习方法(Goal-conditioned Learning),内在奖励驱动的学习方法(Intrinsic Reward-driven Learning),以及前后向表征学习方法(Forward-backward Representation learning).

如下图所示,目标导向的学习方法会对智能体给予明确的任务指导,通常直接将目标输入到智能体的策略中。目标可以以多种形式指定,例如目标状态、目标函数或外部任务描述。
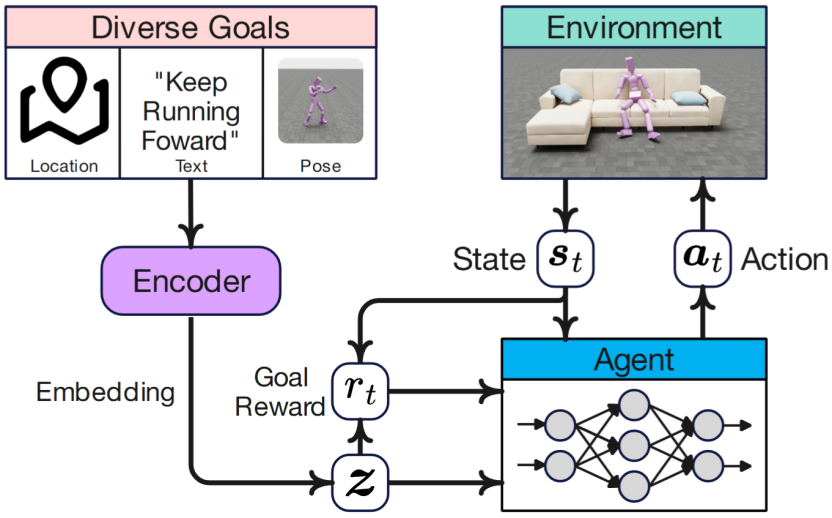
在目标学习的各类方法中,以DeepMimic为代表的基于动作追踪(Motion Tracking)的学习方法目前被广泛地应用于各类人型机器人任务中。在每个时间步,智能体通常被训练来跟踪给定参考运动的关节角度或下一时间步的运动学姿态。相较于直接模仿整个运动(尤其是复杂运动),学习跟踪单个姿态更容易实现且更具通用性,这也是基于跟踪的学习的主要动机。

MaskedMimic是典型的基于目标学习方法构建的行为基础模型,其包含两个阶段的训练过程。首先,MaskedMimic基于动作追踪方法对大量的行为数据进行模仿,学习各类基础运动技能。然后,将得到的底层控制器固定,并训练一个带掩码的变分自编码器对底层控制器包含的知识进行蒸馏得到高阶策略。MaskedMimic支持多种控制模态,并能在不同任务之间实现无缝切换。

在基于追踪的学习中,智能体始终被赋予了明确的目标,并通过显示指定的奖励函数进行训练,以实现定向的技能学习。相比之下,内在奖励驱动的学习则使用完全不同的方法,即激励智能体对环境进行探索,而不依赖于明确的特定任务奖励。智能体受内在奖励的引导,这些内在奖励是自我生成的信号,用于鼓励探索、技能习得或者发现新奇的事物。但是,只通过内在奖励训练BFM存在显著的限制,智能体通常需要进行巨量的训练才能实现广泛的行为覆盖,同时有概率产生不可靠的行为先验(例如,不安全或不切实际的运动),特别是对于具有极其复杂动力学的人形机器人而言。因此,在实际应用时,内在奖励往往要结合其他方法使用,例如目标导向学习,以确保学得模型的有效性。
近期BFM的主要进步受益于一种新的学习框架——前后向表征学习,其主要思想是将策略学习与特定任务目标进行解耦。前后向表征学习的核心是对后继测度(Successor Measure)进行学习,对于一个策略π,其后继测度定义为:

其代表了对未来访问状态分布的建模。基于后继测度,动作价值函数可以表示为:
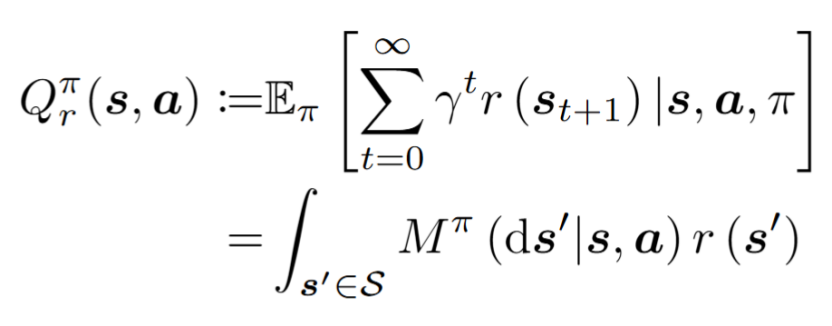
以上公式将动作价值函数分解为两部分:后继测度和奖励函数。因此,只要学习到了策略π的后继测度,即可对任意奖励函数对应的动作价值函数进行零样本估计,而无需进一步的训练。在具体学习时,后继测度又被分解为:
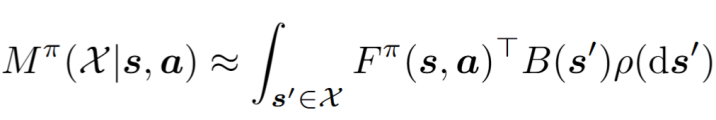
如下图所示,我们分别使用一个前向嵌入网络和一个后向嵌入网络进行训练。最终,

我们可以将策略表示为:

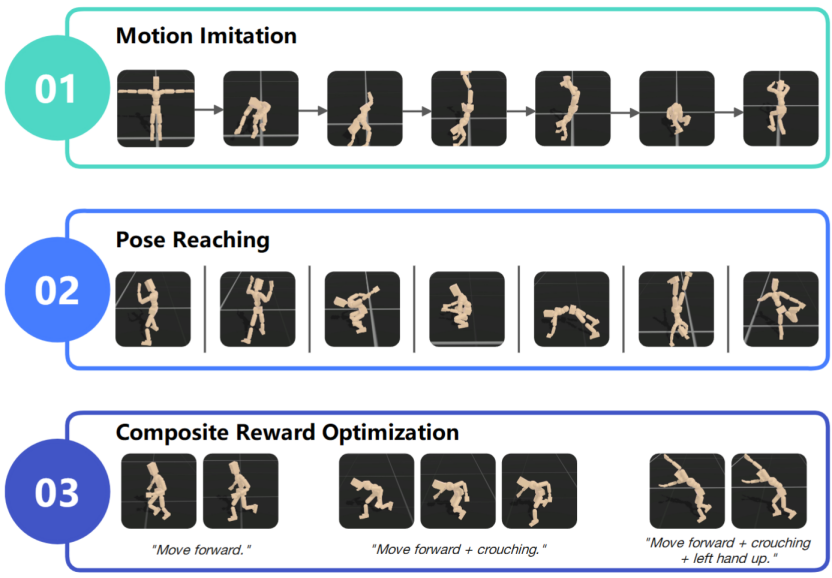
Meta基于前后向表征学习方法开发了Motivo模型。如下图所示,Motivo学习了广泛的行为先验,并展现出卓越的零样本自适应能力,可应对各种下游任务,包括复杂的运动模仿、姿势达成和复合奖励优化。并且,Motivo 能够在确保运动自然性的同时实现实时运动控制。
潜在应用与现实限制
文章进一步对BFM的潜在应用和现实限制进行了分析,如下图所示:

应用方面:
(1)人形机器人的通用加速器:BFM包含了大量可复用的基础技能和广泛的行为先验,可以消除白板训练,实现对下游任务的快速适应。诸如Motivo等高级BFM能直接将高级任务映射为控制动作,大幅缩短开发周期。
(2)虚拟智能体与游戏开发:BFM能生成逼真、情境感知的NPC行为,结合LLMs实现复杂指令解析,为游戏提供前所未有的交互真实感。
(3)工业5.0:BFMs使人形机器人融合预训练技能与实时适应性,支持多任务切换和直观人机协作,推动以人为中心的弹性制造。
(4)医疗与辅助机器人:BFMs帮助机器人在非结构化环境中适应多样化需求,如个性化康复训练和日常辅助任务,应对人口老龄化挑战。
限制方面:
(1)Sim2Real困难:BFM在学习丰富行为技能的同时,也加剧了仿真与现实的差异,如动力学不匹配和感知域偏移,目前的实际应用仍主要局限于仿真环境,真实部署面临行为泛化不稳定等挑战。
(2)数据瓶颈:BFMs 训练数据规模远小于LLMs或视觉模型,且机器人真实数据稀缺,多模态数据(如视觉-本体感知-触觉对齐)尤其缺乏,亟需更大规模、高质量数据集支撑发展。
(3)具身泛化:当前BFMs仅针对特定机器人形态训练,难以适应不同构型(如关节类型、驱动方式或传感器配置),需开发更具通用性的架构以实现跨平台技能迁移。
未来研究机会与伴随风险
最后,文章探索了未来的研究机会和伴随的风险:

研究机会方面:
(1)多模态BFM:未来BFM需整合视觉、触觉等多模态感知输入,以增强非结构化环境中的适应能力,但面临数据集和训练范式的挑战。
(2)高级机器学习系统:BFM可与LLM等结合,形成认知-运动一体化架构,由LLM负责任务规划,BFM执行实时控制,实现复杂任务的灵活处理。
(3)缩放定律:BFM的性能可能随模型规模、数据量和计算资源提升而增强,但需平衡行为多样性与控制效率,其中数据质量对行为先验的学习尤为关键。
(4)后训练优化:借鉴LLM中的的微调、RL对齐和测试时优化技术,可提升BFM的行为对齐性和实时计算效率,需开发针对机器人控制的专用方法。
(5)多智能体系统:BFM能免除单机器人基础技能训练,直接支持多机协作研究,但需开发基于群体交互数据的新型模型以解决物理协调难题。
(6)评估机制:当前缺乏BFM的标准化评估体系,未来需构建涵盖任务泛化性、鲁棒性和人机安全的多维度基准,推动通用物理控制器发展。
风险方面:
(1)伦理问题:训练数据的局限性可能导致机器人行为编码人口偏见或泄露用户健康隐私,而其实体化部署可能放大有害动作的社会风险,亟需建立覆盖数据规范和实时行为治理的新框架。
(2)安全机制:BFM面临传感器干扰引发的控制失效和多模态攻击漏洞等风险,需通过对抗训练和跨模态校验等机制确保其在开放环境中的可靠性和安全性。这些挑战要求研究者在技术创新的同时,同步推进伦理规范和安全防护体系的建设。
结语
该综述首次系统性地梳理了行为基础模型在人形机器人全身控制领域的引用,全面地介绍了相关技术演化历史、方法分类、实际应用、技术瓶颈以及未来研究机会与伴随的风险。尽管 行为基础模型展现出前所未有的强大能力,其也面临着重大挑战,包括 Sim2Real 差距、实体依赖和数据稀缺等问题。在未来的工作中解决这些局限性将有助于开发更可靠、更通用的行为基础模型。希望我们的工作能启发更多相关的后续研究。

往期文章
全球首篇自动驾驶VLA模型综述重磅发布!麦吉尔&清华&小米团队解析VLA自驾模型的前世今生
字节跳动Seed实验室发布ByteDexter灵巧手:解锁人类级灵巧操作
具身专栏(三)| 具身智能中VLA、VLN、VA中常见训练(training)方法
具身专栏(二)| 具身智能中VLA、VLN分类与发展线梳理
具身专栏(一)| VLA、VA、VLN概述
π0.5:突破视觉语言模型边界,首个实现开放世界泛化的VLA诞生!
斯坦福&英伟达最新论文:CoT-VLA模型凭"视觉思维链"实现复杂任务精准操控
RoboTwin2.0全面开源!多模态大模型驱动的双臂操作Benchmark ,支持代码生成!
开源!Maniskill仿真器上LeRobot的sim2real的RL训练代码开源(附教程)
迈向机器人领域ImageNet,大牛PieterAbbeel领衔北大、通院、斯坦福发布RoboVerse大一统仿真平台
CVPR 北大、清华最新突破:机器人操作新范式,3.3万次仿真模拟构建最大灵巧手数据集
人形机器人四级分类:你的人形机器人到Level 4了吗?(附L1-L4技术全景图)建议收藏!
斯坦福最新论文:使用人类动作的视频数据,摆脱对机器人硬件的需求
爆发在即!养老机器人如何守护2.2亿老人?产业链+政策一览,建议收藏!










![2025年中国驱控一体控制系统行业现状、竞争格局及未来趋势分析:市场接受度不断提升,销量稳步增长,本土企业发展提速[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-09-24/68d34370b35eb.jpeg)