“他山之石,可以攻玉”,站在巨人的肩膀才能看得更高,走得更远。在科研的道路上,更需借助东风才能更快前行。为此,我们特别搜集整理了一些实用的代码链接,数据集,软件,编程技巧等,开辟“他山之石”专栏,助你乘风破浪,一路奋勇向前,敬请关注!
该研究提出了首个无需训练的通用虚拟试穿(VTON)框架,巧妙地解耦了服装和姿态的约束,成功统一了“棚拍”(in-shop)和“街拍”(in-the-wild)两大应用场景,在保持服装纹理细节和姿态一致性方面取得了卓越的效果。更令人瞩目的是,该框架首次实现了多人虚拟试穿,为虚拟时尚体验开辟了新的可能性。

论文基本信息
论文标题: OmniVTON: Training-Free Universal Virtual Try-On 作者: Zhaotong Yang, Yuhui Li, Shengfeng He, Xinzhe Li, Yangyang Xu, Junyu Dong, Yong Du 机构: 中国海洋大学,新加坡管理大学,哈尔滨工业大学(深圳) 论文地址: https://arxiv.org/pdf/2507.15037v1 项目主页: https://github.com/Jerome-Young/OmniVTON 收录会议: ICCV 2025
研究背景与意义
虚拟试穿(VTON)技术旨在将服装图像无缝地“穿”在目标人物身上,从而革新在线购物体验。目前主流的VTON技术主要分为两大类:
监督式“棚拍”(in-shop)方法:这类方法通常使用成对的“模特-服装”数据进行训练,能够生成高保真度的结果,但难以泛化到不同领域或场景(例如,将网店的白底服装图用到生活照上)。 无监督“街拍”(in-the-wild)方法:这类方法提高了对不同场景的适应性,但受限于数据偏差,通用性仍然不足,且效果往往不如前者。
现有方法都需要针对特定场景和服装类型进行专门训练,这使得大规模应用变得不切实际。因此,开发一个能够跨越所有场景、无需额外训练的统一VTON框架,成为该领域一个亟待解决的挑战。OmniVTON正是在这一背景下应运而生。

核心方法
OmniVTON的成功关键在于其创新的免训练两步走策略,它巧妙地利用了预训练的扩散模型,并通过解耦服装和姿态的处理来克服挑战。

第一步:结构化服装变形 (Structured Garment Morphing, SGM) —— 保证纹理细节为了在无需训练的情况下精确地保留服装的纹理细节,OmniVTON首先引入了一个服装先验生成机制。
生成伪人体图像:对于仅有服装的图像,首先通过语义引导生成一个穿着该服装的伪模特图像。 多部件语义对应:利用骨骼关键点和语义分割图,在伪模特和目标人物之间建立起精细的、分区域的对应关系(如躯干、左上臂、右下臂等)。 局部动态变换:对每个服装区域进行独立的几何变换,使其与目标人体的相应部位精确对齐,生成一个结构上连贯的变形结果。
第二步:姿态注入与边界缝合 —— 保证姿态一致性为了让生成结果的姿态与目标人物完全一致,同时避免原始服装纹理的干扰,OmniVTON设计了独特的姿态注入和图像修复流程。
频谱姿态注入 (Spectral Pose Injection, SPI):传统的DDIM反演技术虽然能保留姿态结构,但也会引入不必要的纹理干扰。SPI通过对噪声的频谱进行分析,只保留了代表人体姿态轮廓的低频信息,而将高频部分替换为随机噪声。这种频率级别的调制,既保证了姿态的准确性,又为生成新纹理提供了灵活性。

连续边界缝合 (Continuous Boundary Stitching, CBS):SGM生成的服装先验在边界处可能存在不连续。CBS机制在图像修复过程中,通过在注意力层面对服装图像和变形后图像的特征进行双向语义信息交互,有效消除了拼接处的“硬边”和不自然感,确保了最终合成结果的视觉真实感。
通过将服装的纹理处理(SGM)和人体的姿态处理(SPI)彻底分开,OmniVTON有效避免了扩散模型在同时处理多个条件时固有的偏见问题。
实验结果与分析
研究团队在VITON-HD、DressCode和StreetTryOn等多个权威数据集上对OmniVTON进行了全面的评估。定量比较: 无论是在成对还是非成对的测试设置中,OmniVTON在FID、SSIM和LPIPS等关键指标上均显著优于现有的SOTA方法。如下表所示,在包含多种服装类型的DressCode数据集上,OmniVTON取得了全面的领先。

在更具挑战性的StreetTryOn基准测试中,OmniVTON在所有四种跨场景设置(店-街、模-模、模-街、街-街)中都取得了最佳性能,展现了其强大的泛化能力。

定性比较: 视觉效果对比进一步证明了OmniVTON的优越性。无论是上装、下装还是连衣裙,它都能生成高度逼真、细节丰富且姿态准确的结果。

在复杂的街拍场景中,OmniVTON同样表现出色,能够保持人物姿态和服装纹理的高度一致性,效果远超其他方法。

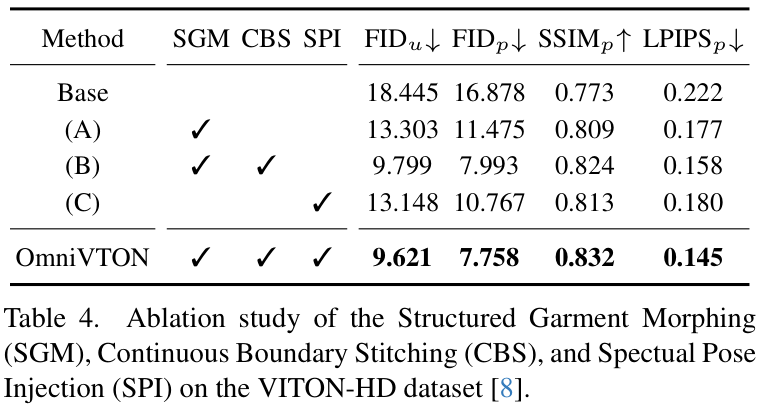
消融研究: 消融实验清晰地展示了SGM、CBS和SPI三个核心模块的有效性。缺少任何一个部分都会导致结果质量的明显下降,验证了框架设计的精妙与合理。

核心贡献与价值
OmniVTON最大的亮点还在于其首次实现了多人虚拟试穿。得益于SGM的创新设计,该方法可以毫不费力地将一件或多件服装同时应用到场景中的多个不同人物身上,极大地拓宽了虚拟试穿的应用边界,为家庭穿搭、团队制服设计等场景提供了可能。

总结来说,OmniVTON的贡献主要有:
提出了首个免训练的通用VTON框架,统一了“棚拍”与“街拍”场景。 设计了SGM、SPI和CBS等创新模块,有效解耦了纹理与姿态,保证了结果的高保真度和一致性。 实现了前所未有的多人VTON功能,展示了其强大的通用性和可扩展性。 代码开源,为社区的研究和应用提供了宝贵的资源。
尽管在处理极端人群密集或目标身体区域极小的情况下仍有挑战,但OmniVTON无疑为虚拟试穿技术的发展指明了新的方向,并向着更鲁棒、更通用的未来迈出了坚实的一步。
 本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗!











